AI development and usage currently depend heavily on general-purpose GPUs, but the rapid rise of generative AI is pushing these chips to their limits in performance, cost, power efficiency and availability. To sustain AI’s evolution and practical implementation, specialized semiconductors optimized for AI computing are essential.
Since 2016, PFN has been developing the MN-Core™ processor series with Kobe University—AI-dedicated chips that deliver high speed and efficiency for training and inference. Designed from the ground up with a completely different architecture from general-purpose GPUs, the MN-Core series specializes exclusively in the computations required for AI, achieving outstanding processing performance and efficiency.

As the first model in the MN-Core L Series, the MN-Core L1000 is a processor under development designed specifically for generative AI inference. Unlike conventional processors that place memory and logic side by side, the L1000 adopts a 3D-stacked architecture that vertically stacks memory and logic. This structure enables significantly greater memory bandwidth than the high-bandwidth memory (HBM) used in current high-end GPUs.
In addition, while many recent AI processors rely on SRAM (static random access memory), the L1000 employs large-capacity, cost-efficient DRAM, achieving both high speed and large memory capacity at lower cost. As a result, the L1000 can process more tokens per second during generative AI inference, delivering up to 10× faster performance compared to existing GPUs and other processors.

MN-Core 2 is the second generation model in the series that boasts a top-class energy efficiency. Compared with the first-generation MN-Core, the second generation has larger memory bandwidth and smaller size, allowing high-density positions in compact blades.
| MN-Core 2 | MN-Core 2 (power efficiency) | |
|---|---|---|
| FP64 | 12 TFlops | 37.24 GFlops/W |
| FP32 | 49 TFlops | 148.9 GFLops/W |
| TF32 | 98 TFlops | 297.9 GFlops/W |
| TF16 | 393 TFlops | 1,192 GFlops/W |


5U rack-mount server equipped with eight MN-Core 2 boards

A desktop machine equipped with a single MN-Core 2 board. Compact and easy to install in an office environment, it offers a simple way to experience AI acceleration powered by MN-Core 2.
*MN-Core 2 Devkit basic package is provided in Japan only.
The first-generation MN-Core consists of four dies integrated into one package. With each die has 512 MABs, the processor has a total of 2,048 MABs. Developed in the TSMC 12nm process, the first-generation MN-Core has higher peak performance and energy efficiency than other accelerators with the same process.
In 2020, PFN began operating MN-3, a supercomputer powered by 160 MN-Core processors connected with a specialized interconnect. MN-3 has topped the Green500 list of the world’s most energy-efficient supercomputer multiple times.

The MN-Core series processors have shown significantly higher performance for actual AI workloads than GPUs thanks to its high energy efficiency and high peak performance.
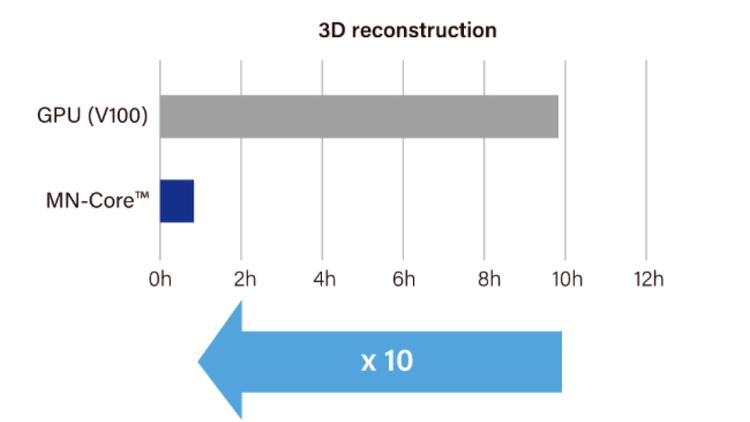
First-generation MN-Core achieved a tenfold increase in speed for neural network-based reconstruction of thousands of 3D models from 2D images for PFN 3D Scan. (1st-generation MN-Core)

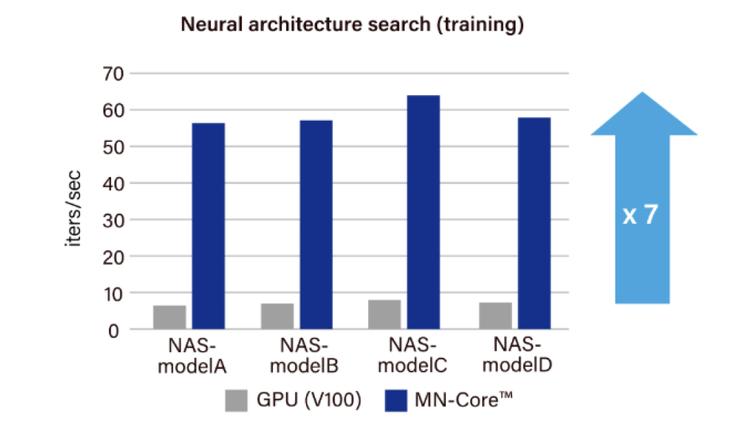
Automatic optimization of the image recognition model for Kachaka, an autonomous mobile robot that are currently sold in Japan, was seven times faster when powered by MN-Core™ than GPU. (1st-generation MN-Core)

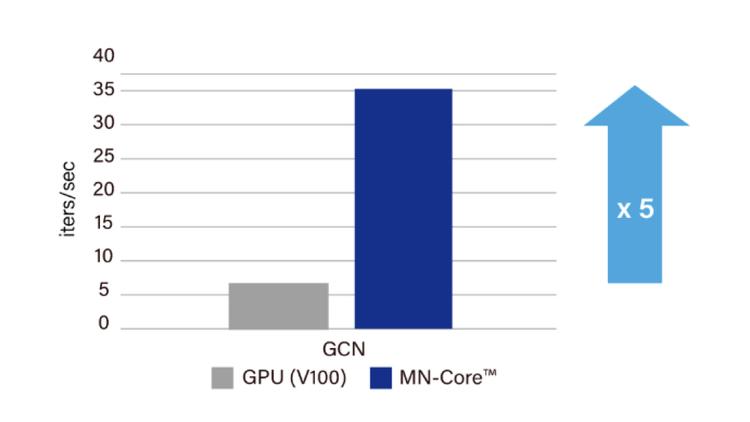
The speed for neural network-based atomistic simulation of new materials on Matlantis™ was over five times higher with MN-Core than GPU. (1st-generation MN-Core)
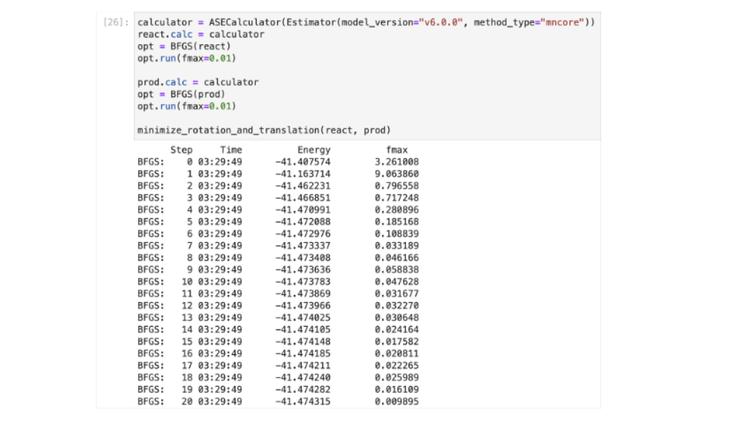
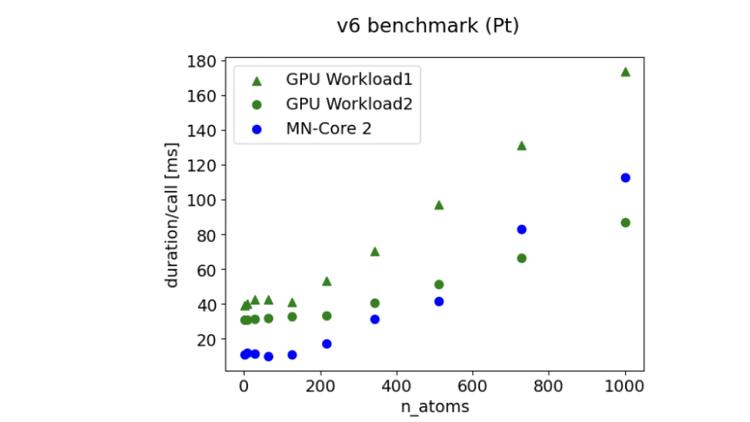
Through PFN’s cloud service PFCP™, the computing power of the second-generation MN-Core 2 was experimentally used in Matlantis, confirming faster performance than GPUs in atomic-level simulations of low-atom-number systems.
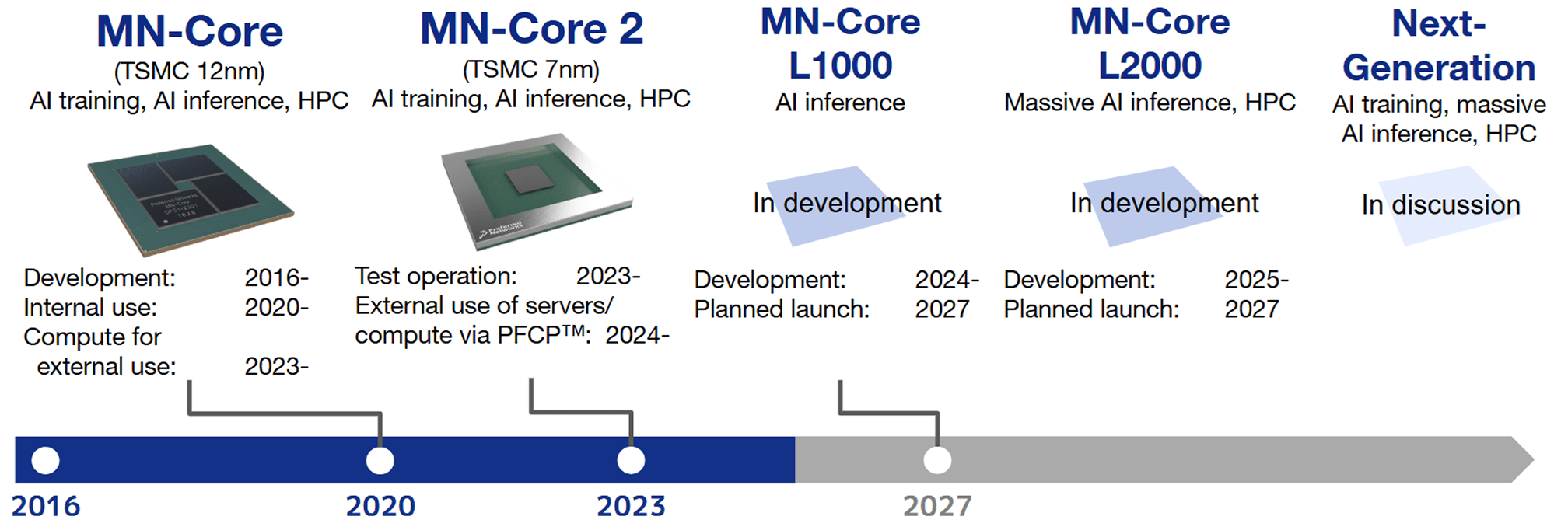
PFN foresaw the rapid rise in demand for AI chips and launched development of the first-generation MN-Core™ processor in 2016. We continue to advance development and commercialization efforts today.
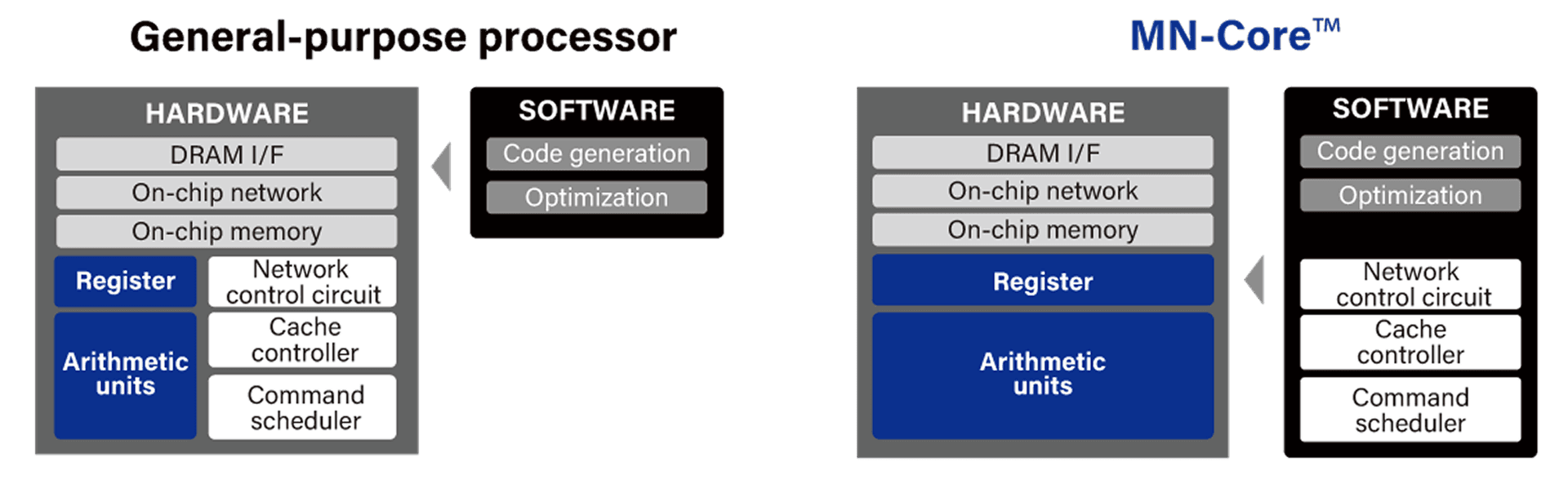
By shifting control and other hardware functions to software, the MN-Core series maximizes the proportion of arithmetic units on the hardware, achieving exceptional performance and power efficiency.
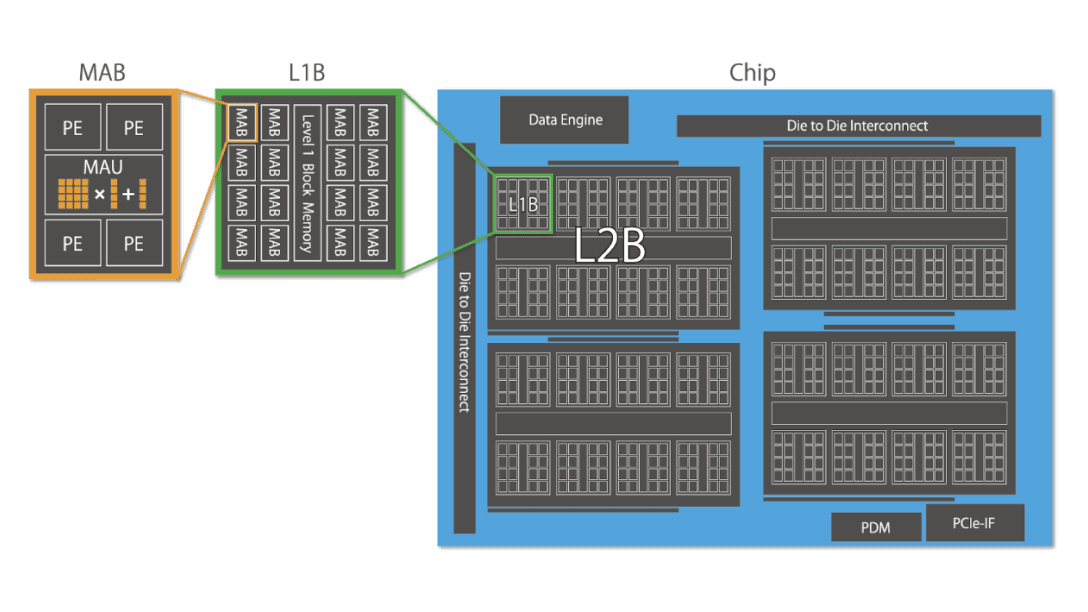
MN-Core has matrix arithmetic units (MAUs) densely mounted in its hardware architecture. Entirely composed of SIMD (single instruction, multiple data) with no conditional branch, the simple architecture maximizes the proportion of arithmetic units on the semiconductor area. The MABs (matrix arithmetic blocks), each consisting of four PEs (processor elements) and one MAU (matrix arithmetic unit), have a hierarchical structure. This allows flexible programming as each hierarchical level can have multiple modes such as scatter, gather, broadcast and reduce.
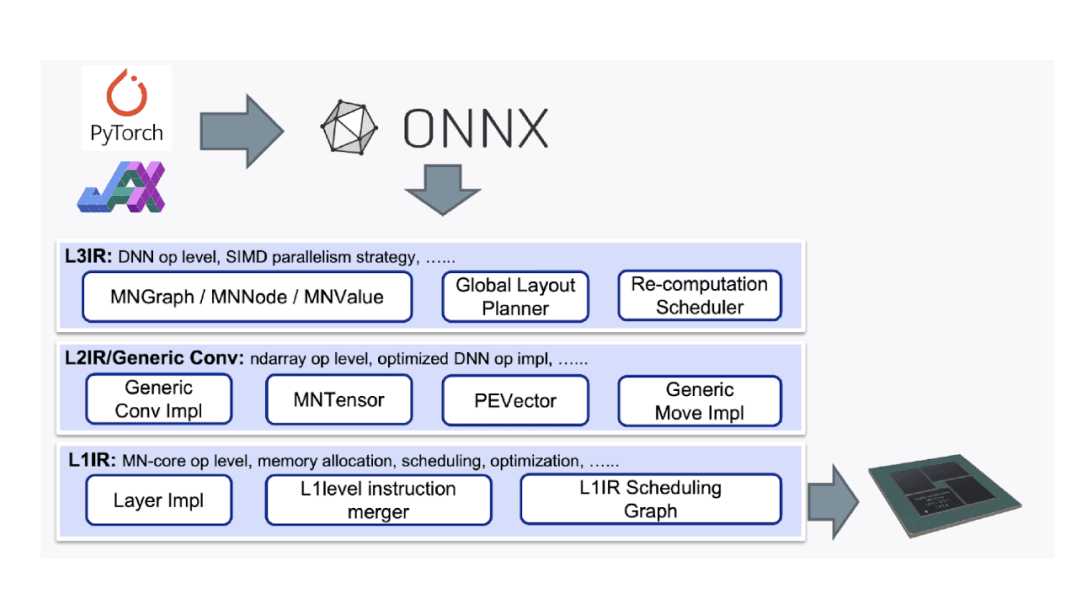
PFN also develops a compiler specifically for the MN-Core series so that users can harness its full potential without making major changes to existing AI workloads. The MN-Core compiler generates and supplies optimal instructions and moves data from computational graphs defined with high-level languages such as PyTorch and JAX. To efficiently perform different levels of processes from computational graph-level control to low-level instruction generation, the MN-Core compiler divides the problems according to their levels of abstraction and thus consists of components that make it easy to make improvements at the respective level.