Vol.1 LLMの事前学習と知識獲得に関する研究
最近の研究からの紹介です。
LLMの事前学習で新しい知識を獲得する時に、それがどういうカタチで獲得されているのかを調べた例で、韓国科学技術院(KAIST)と通信事業者のKT、University College of London (UCL)がやっている仕事です。
◆架空の知識を使った実験
まず、分析ができるようにわざと人工的に架空の知識を入れています。

架空の知識データセット例
例えば、”火星で40番目の政府・・・”のような絶対普通のテキストにはないような架空の知識を用意します。これを学習中の途中のステップ、例えばちょうど真ん中や、前半3分の1が終わったところとか、それぞれの学習途中にこの架空の知識が入った学習データを入れて、その後にも普通に他の学習をして、また入れて、ということをします。
◆知識の定着と評価
そして最後に評価する時にこの知識に関する質問をします。例えば、「(架空の)この政府では誰のもとで改革が行われましたか」など。そういったことを聞いて、ちゃんと正解を当てられるかを、その正解に関する単語の対数尤度(その単語を生成する確率)がどう変わるのかをもとに知識が注入されたかどうか調べます。
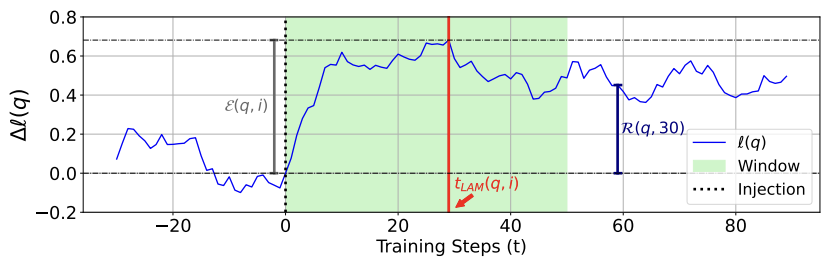
LLMの学習っていうのは、実際そのデータを見た時にちゃんとパラメータが更新されるんですけど、内部の学習では、モーメンタムという仕組みが動いていて、これはいきなりパラメータを動かすんじゃなくて、はずみ車のように重みを持ったボールを転がす時と同じような感じで、ある程度パラメータをアップデートしたその後も緩やかにちょっとずつ加えていくようなことをして安定化させます。
この仕組みがあるため、知識を導入した時よりも実際にその知識が定着するまでには時間差があります。20とか30ステップぐらいかけて徐々にその知識が入っていきます。その知識が入った場合のところの元との差(知識がどれくらい増えたのか)を測ります。
◆知識の忘却と維持
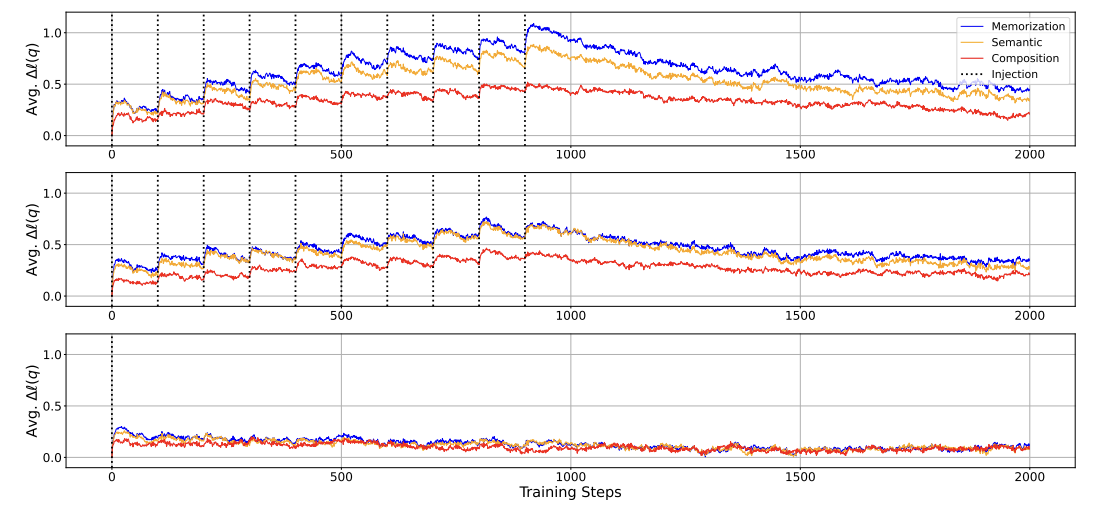
この論文の一番メインの図から、何が起きているのかを見ると、一番上のグラフだけを見てもらえばいいんですが、点線が入っているところで(火星の改革はこの人が行いましたとかの)知識を入れて、その答えに関する生成確率がどのくらい変わったのかをみると、バンッとちょっと上がって、学習が進んでいくと忘れていって、また入れて、忘れていく、というのが続いていきます。
なので、いきなり覚えるんじゃなくてLLMの学習知識獲得っていうのは、1回1回知識を導入した時にちょこっとだけ上がって、忘れていくというのが何回も繰り返されることによって、最終的にこれがある閾値を超えて、例えば全部の単語の中で一番確率が高くなるところでちゃんとその知識が獲得されたように見ることができます。
もう一つ興味深いことが、この知識注入に関してはいろいろわかって、例えば学習を入れるタイミングが前半でも後半でも知識の獲得速度はあまり変わらなくて、例えば、後半の方が物分かりが良くなっていて、ある知識を獲得する速度が変わるというのは見られなかったです。
また忘れる速度がどんな場合でもかなり一定に忘れていくっていうのがありますので、例えば、最初に知識を入れた箇所も最後に入れた箇所の場合も、その後ずっと学習が続いていくと入れた知識を忘れていっちゃうというのが起きています。
なので、例えばファインチューニングした時に、新しい固有の知識をどんどん入れていった時にも同じようにアップデートするたび、既存の知識はどんどん忘れていって、壊れるということが起きているのが分かりました。
◆忘却を防ぐ工夫
いくつか分かった知見としては、例えば入れる知識に関しては全く同じ文で入れるんじゃなくて言い換えた方がいいっていうような話が前にもあったんですけども、今回の場合にも言い換えた時には良いのが分かったんですけど、何が良いかっていうと、忘れにくいということが分かりました。
入れている知識、上がっている知識量は同じなんですけども、同じ文章を繰り返した場合にはすぐ忘れます。恐らく同じ文章で獲得した場合のパラメータがすごく頑健じゃなくて、そこが壊れちゃうと簡単に忘れちゃうんだけれど。文章を言い換えているといろんな形でそれを覚えているので、パラメータがある部分がアップデートで壊れても、他のところが生き残りやすいことによって忘れにくくなっているのではないかと思われます。
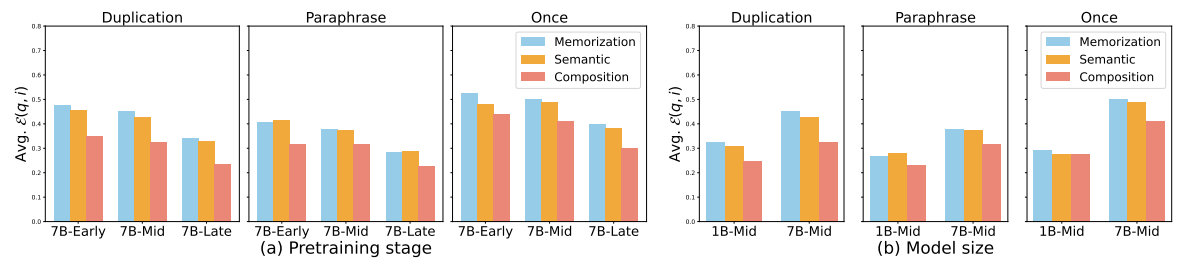
知識に関しても3つの評価の仕方をしていて、
- メモライゼーション:ちゃんと記憶しているのか
- セマンティック:それをかなり意味的に言い換えても覚えているのか
- コンポジション:2つ以上の知識を組み合わせないと推論できないようなタスクの評価
それぞれについて、メモライゼーションの方が忘れやすくてコンポジションはそれに対して獲得しにくいけれども忘れにくいというようなことが分かりました。
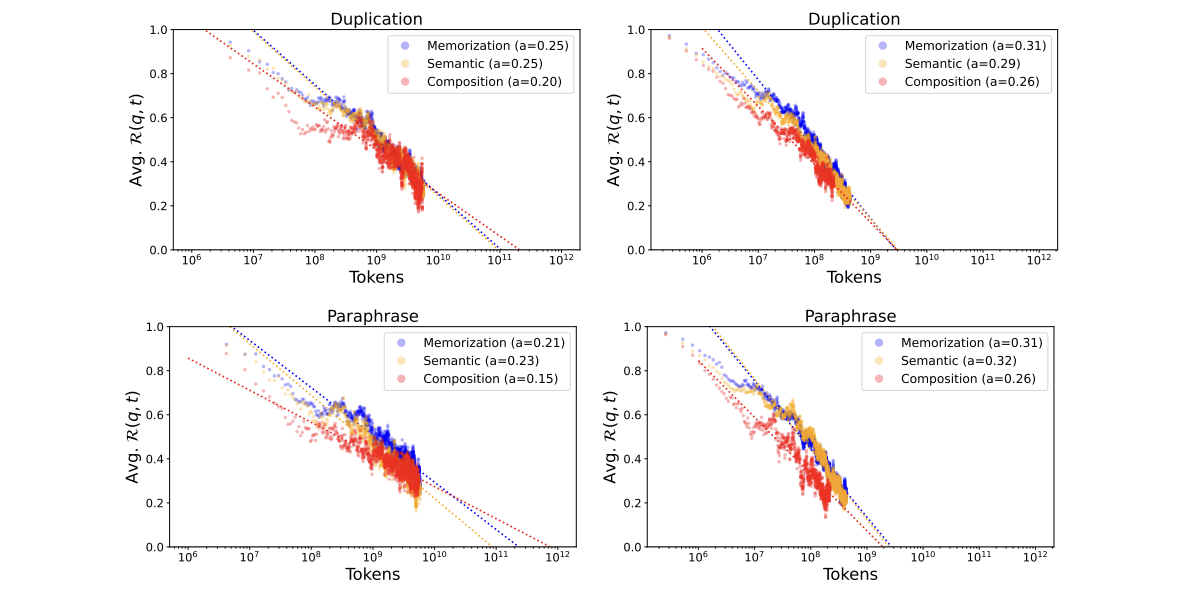
また、大きいモデルの方が1回あたりの知識獲得量の部分(対数尤度が上がる部分)が大きいというのが分かりました。一方で、忘れる速度は大きくても小さくても変わらないというのが分かりました、という論文でした。
◆示唆されるLLM学習の工夫
いろいろな知見があるんですけれども、まずそもそもなんで忘れるのかということに関して、(これもちゃんと実験しないと分かんないんですけど、)おそらく破滅的忘却と呼ばれる現象が起きている。
ニューラルネットワークというのは、一つのことを覚えるときに、多くのパラメータを他の概念と共有しています。犬のことを覚える場合と猫のことを覚える場合に、例えば50%ぐらいのパラメータが共有されています。そうやって共有されていると、いいこととしては、例えば何か犬に関しての新しい知識を得たら(例えばそれが動物に関する知識だったら)、それは猫にも転用できるので、覚えたことを他の現象に使うこと(汎化)にはすごく良いです。
一方で、あることを覚えたら副作用として、今まで覚えていた他のことが壊れちゃうようなことが起きてしまいます。もちろん忘れたくないので、これをどうやって防ぐのか今後工夫が必要です。
あと、モデルが大きい方が学習効率が高いというのも昔から示唆されていたんですけど、
なぜかはやっぱりよくわかっていなくて、私の仮説としては、大きいモデルの方が同じ情報でもその情報をより効率的に圧縮された形で表現できていて、そこの表現上だと、覚えるために調整しなきゃいけないパラメータ数が少ないので効率よく覚えられる。
または、もしくは加えて、新しい知識を覚えるということはパラメータを更新するということなんですけど、小さいモデルの場合だと、どのパラメータを動かしても損失を下げられないという場合がよくあるんですけど、大きい場合だと基本的に下がる方向の候補が桁違いに多いので、知識を覚えるためにこっちの方向にパラメータを下げたら下がるな、という方向が見つかりやすい。宝くじ仮説とかともちょっと関係するんですけどそういうのがあるかもしれないです。
もともと大きいモデルの方が干渉しにくくて忘れにくいのかなと思ってたんですけど、なぜか今回の結果だと忘れにくさは(モデルの大きさに)あまり関係なく、これはちょっとよくわからないです。
学習の時にこうやるといいかもしれないという示唆としては、人間よりも(人間も忘れちゃうんですけど)、今のモデルだと学習すればするほど昔学習したものをすぐ忘れちゃうので、学習データの知識密度は高い方が良い。関係ないことをちょっとでも見て更新したら昔のを忘れちゃうので、基本的には覚えたいことを濃縮してそれを短期決戦で短い学習期間で覚える方が良いかもしれない。
あとは、今回出た方法のようにして新しい知識をファインチューニングとかで入れた時に古い知識を忘れていくというのは正確に測ったりできるので、医者がモニターしながら手術するのと同じように、ファインチューニングの時も、過去の知識の忘れ度合いをモニタリングしながら知識を導入するのはあるかもしれない。
究極的には、人間は、閾値を超えれば忘れないことができているので何か方法はあるはずなんですね。なので、その方法をうまく見つけることができると良いかなと思ったのと、大きいモデルが解決できるのは分かってるんですけど、それは学習推論共に良くないので、大きなモデルでなくても同じように学習速度が上がるような方法が見つけられると良いかなと思います。

