Vol.5 番外編 医療・ヘルスケア領域におけるLLMの構築
リサーチャーの岩澤です。先日出したブログについて、話させていただけたらと思います。タイトルは「医療・ヘルスケア領域における大規模言語モデルの構築に向けて」となっています。
◆概要
最初に概要ですが、既存の大規模言語モデル、LLM(Large Language Model)に対して、PFN(Preferred Networks)独自の医療ドメインのデータセットを用いてファインチューニングを行いました。ファインチューニングを行ったモデルを、「Llama3-Preferred-MedSwallow-70B」と名付けているんですが、医療特化の大規模言語モデルとして新しく開発しています。
このモデルの一番の推しポイントなんですけど、日本医師国家試験においてGPT-4を上回る成績を収めていて、なおかつ「Hugging Face Hub」というモデルの公開を行う場所があるんですが、その中で日本医師国家試験の成績が一番高い最高の性能を誇るようなモデルとなっています。
◆医療・ヘルスケア分野とLLMの相性
内容についてもう少し詳しく説明していきます。まず最初に、なぜ大規模言語モデルで医療・ヘルスケアをやるかという話なんですけど、そもそも医療・ヘルスケアの分野とLLMは非常に相性が良くて、いろんなタスクでLLMが役に立つと考えられます。
例えば、診断の補助をはじめとして、論文からナレッジ抽出をしたりですとか、あとはお医者さんが実際に所見文をたくさん書くわけですが、そういった所見文の要約ですとか、さまざまな場面で大規模言語モデルが役立つタスクが考えられます。ですので、医療の分野においてLLMは非常に大きな役割を果たすことが考えられています。
ただ現実はそう簡単ではなくて、実際、今回ベンチマークとしても使っている日本医師国家試験でLLMはなかなか苦労しているということが分かっています。良いモデルとされているGPT-4ですら日本医師国家試験において合格点ギリギリという状況です。
実際の試験合格者は、合格点より50点とか、それ以上の点数で結構余裕で合格している方も多いので、それを踏まえるとLLMの精度は実際のお医者さんに比べるとまだまだというような印象を持っています。
◆ファインチューニングに取り組む理由
PFNでは、事前学習から全て自社で行っているPLaMo(プラモ)に加えて、様々なモデルのファインチューニングにも取り組んでいます。これはなぜかというと、特に医療ヘルスケアの領域では個人情報といったセンシティブなデータも多く、こうしたものを最初からモデルの事前学習で使ってしまうと、(もちろん個人情報は伏せた状態でこういったデータは受領しているわけですが)万が一データを削除してほしいというような要望を受けた時に、モデルの学習し直しになかなかのコストがかかってしまう。
ということで、比較的容易にデータをカスタマイズして再学習が可能なファインチューニングで、こうしたセンシティブなデータの対応ができるようになると事業的なリスクも非常に低く保つことができますし、両者にとって良いと考えています。
◆ファインチューニングの手法
こうしたファインチューニングではいろいろな手法があるんですけど、今回私たちは継続事前学習と呼ばれるようなファインチューニング手法を用いて、既存のLLMの改良を行っています。
そちらについてもう少し詳しく話していこうと思います。まずLLMのファインチューニングには継続事前学習以外にも、指示学習などいろんな手法があります。
特に指示学習がLLMのファインチューニングでよく聞かれるんですが、これは特定の指示と返答のペアを用いて学習を行うもので、LLMが元々持っている知識を強調したり、あと出力のトーンとか構造を制御する、そういったスタイルを変更したりするのに役に立ちます。一方で新しい知識の獲得、これ自体はなかなか不向きだというふうに言われていて、そういった研究もだんだんと出てきています。
私たちが使った継続事前学習は、文字通りモデルを最初に作るときの事前学習と同様の形式でモデルの学習を行うので、これは事前学習に含まれていないようなモデルにとって新しい知識にも対応できるとされています。
我々が特に今回、医師国家試験にも対応していく中で、日本語の医療知識が既存のLLMには足りていないというような問題意識がありました。ですので今回は事前学習と同様の形式をとるような継続事前学習でモデルの訓練を行った、そういった経緯があります。
継続事前学習を行うにあたってベースのモデルには「Llama-3-Swallow-70B」というモデルを選びました。これは東工大と産総研の合同グループによって開発されたモデルで、公開されているモデルの中でも高い日本語能力を持ったモデルとなっています。今回こちらのモデルをベースにモデルのファインチューニングを行いました。
もう一つ、モデルの改良をやるにあたってQLoRA(キューロラ)という手法を行っています。基本的には、大規模言語モデルというのは文字通り非常にサイズが大きいモデルになっていて、これは計算リソースを大量に使ってしまうものになっています。QLoRAと呼ばれる手法では、一回モデルを量子化します。そうすると普段のモデルよりも小さいメモリの中で扱うことが可能になります。
そうすることによって700億パラメータという非常に大きなモデルであったとしても、比較的エコにファインチューニングを行うことができるというのが今回の一つの推しでもあります。実際、今回のQLoRAを用いた継続事前学習だと、社内の計算機クラスタを使ってファインチューニングを行っていますが、A100と呼ばれるGPU2枚のみでファインチューニングができています。
◆結果と今後の課題
それでは結果の方に行きたいんですが、今回開発したモデルの評価を行うために「IgakuQA」というベンチマークを使いました。これは何かと言いますと、2018年から2022年の日本医師国家試験5年分の問題をLLMに解かせるような、そういったベンチマークになっております。
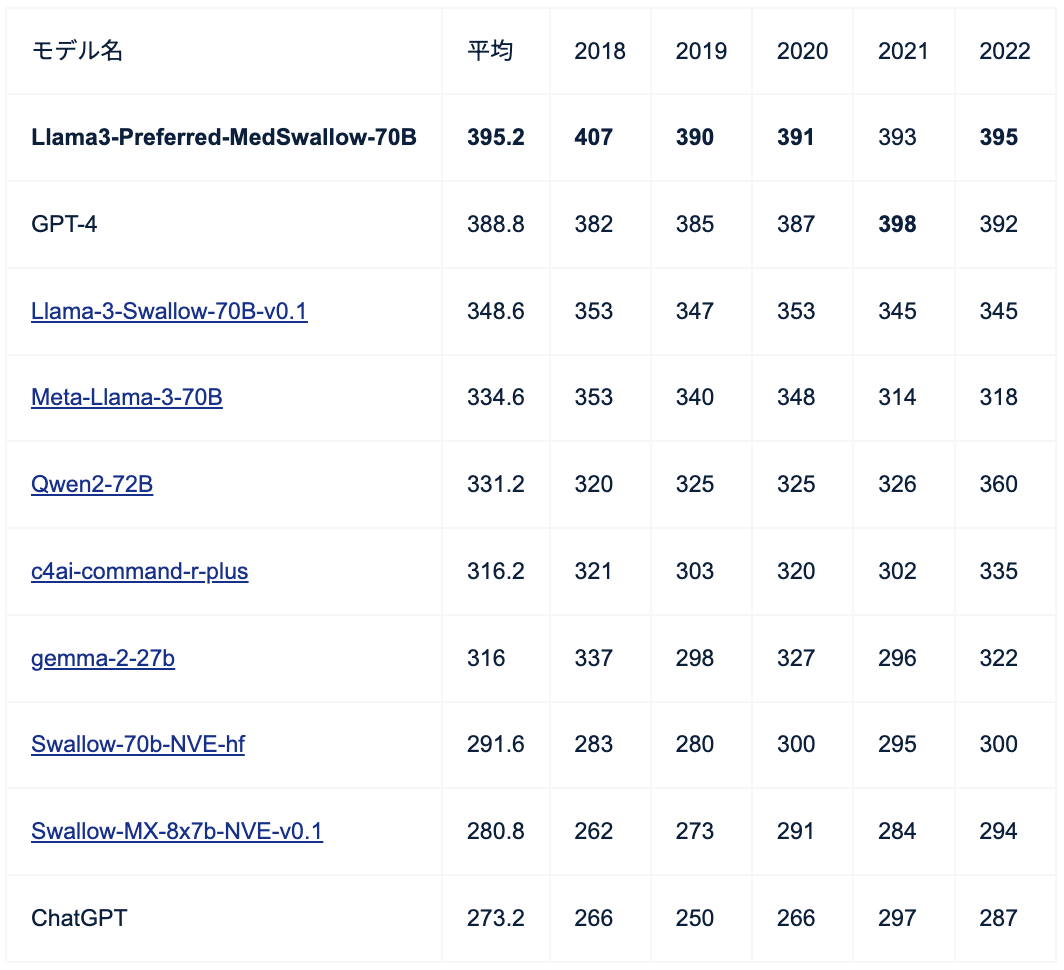
実際の結果がこちらの表なんですが、今回いろいろなモデルの日本医師国家試験での結果を計測しました。中でもGPT-4はやっぱり結構成績がいいわけですね。5年間の平均で388.8点を取っています。
我々は「Llama-3-Swallow-70B」をベースモデルとしていて、ファインチューニング前は348点ほどしかないんですけど、ファインチューニングをしたことによって395点と、およそ50点高めることができております。
これはどういう状況かと言いますと、オープンなモデルとしては初めてGPT-4を超えるようなモデルとなっています。さらにですね、私たちの知る限りでは公開されているモデルの中で初めて医師国家試験で合格点を取れたモデルとなっていて、非常に大事なマイルストーンになっていると思っております。
医師国家試験の中でもう一つ特徴的なものとして禁忌肢があるので、その話だけ最後にできればと思います。何かというと、医療の文脈で危ないようなことが書いてある選択肢で、一定数(大体3、4問くらい)そういうものをもし選んでしまうと即不合格になってしまうような選択肢のことを禁忌肢と呼びます。
今回作った「Llama3-Preferred-MedSwallow-70B」が5年間の過去問の中で、どれくらい禁忌肢を踏んでしまったかということを調べました。

こちらが実際に禁忌肢を選んでしまった問題の一つで、ちょっと読みだすと大変なんですけど、68歳の女性が意識低下のために救急車で搬送されて・・・と。心拍数ですとか血液生化学所見ですとかいろいろなデータをもとに、実際に患者さんがどういった状態にあって、そのもとでどういった対処が必要か、ということを考えなければいけない問題となっています。
こちらの正解はb, c, dなんですけど、今回開発したモデルはbとdは合っていたんですが、eを選んでしまった。これはですね、副腎皮質ステロイドを補わずにeの選択肢をやってしまうのは非常に危ない行為になっていて禁忌肢とされています。
今回のモデルは決して多くはないのですが、残念ながら5年間の問題の中で4つ禁忌を選んでしまっていて、間違えた問題はどれも先程のような特定の状況があって、そこから診断をくださなきゃいけない、ちょっと難しい問題となっております。こういう問題って我々素人にとってももちろん難しいですし、LLMにとっても非常に難しい問題となっています。なぜかというと、与えられた状況から論理的推論をする必要があるからです。
このようなタスクはLLMにとってはまだまだ結構課題が多い分野であるというのが事実でして、実際にいろいろ対策が考えられています。 Chain-of-Thoughtというのもその一つですし、医療分野向けにもMedPromptといったような対策が講じられています。実臨床で活用できるようなレベルに達するには、医療分野におけるこうした論理的推論能力って非常に大事だと思っていまして、今後もさらなる研究開発が実際に必要なところだというふうに思っております。
◆まとめ
ブログの方にはその他の話題もいろいろ載せているんですが、お話としてはそんなところかというふうに思います。
最後に改めてラップアップしますと、今回、医療向けLLMとして「Llama3-Preferred-MedSwallow-70B」というモデルを開発して、これが医師国家試験において「Hugging Face Hub 」上で公開されているモデルの中で最高の性能を達成しました。今回のQLoRAを用いた継続事前学習が非常によく機能したことが検証できたような、そういった成果になっているんじゃないかと思っています。
こうした成果と同時に禁忌肢で見られたような課題もよく見えてきていて、そういった知見というのは今後の社内の研究開発やソリューション開発にも活用していく予定です。
ぜひ興味を持っていただいた方はご連絡いただけたらと思います。どうもありがとうございました。

