Vol.6 PLaMoのトライアルリリースに至る経緯
今回、PLaMo(プラモ)のβ版トライアルをリリースしました。そこに至るまでの話を初めての人に説明するカタチでさせていただけたらと思います。
◆PLaMoの開発開始
今までPLaMoの開発を進めてきたんですけれども、一番最初は昨年の夏、8月・9月ぐらいにPLaMo-13Bという130億パラメータのモデルを、産総研のスーパーコンピューターABCIを使って作りました。
その後に、経産省とNEDOの生成AI開発支援プロジェクト「GENIAC 1.0」が始まって、そこに応募して採択されました。今年の2月から8月にかけてPreferred Elements(Preferred Networksの子会社)の中で開発を進めていたのが、今回作っていたPLaMo-100Bになります。
◆100Bモデルの開発と計算資源
PLaMo-100Bは1000億パラメータなので、まずモデルサイズがもちろん大きいというのがあります。あとやっぱり13Bを作った時は、本当にいろいろ急いで作っていたので準備不足だったんですけれども、この100Bに関しては、データの整備だとか、いろいろな仕組みをちゃんとやりました。
あとは前と比べてかなり事後学習(ポストトレーニング、指示教師あり学習、アライメント)と呼ばれる部分についてもしっかり行っています。
今日はちょっと話す時間がないのですけれども、画像とか音声のマルチモーダル対応っていうのを進めていました。もともとですね、開発にあたっては使える計算資源というのが、今回使ったのはH100数百枚を6ヶ月間使ったんですけども、そのうち事前学習に3ヶ月ぐらい使っています。
今回の学習規模はもちろんすごく大きくて国内最大規模の1つですが、一方で、フロンティアモデルと呼ばれているモデル、GPT-4oとかAnthropicのようなモデルがどのくらい計算資源使ってるかは公開されてないですけど、おそらくMetaが作ったLlama3のでかいサイズと同じかそれ以上投入していて、Llama3の400Bの学習の場合だと、H100を1万6000枚2ヶ月間投入しました。(PLaMo-100Bは)だいたいLlama3 400Bより一桁小さくて、Llama3 70Bの数分の1くらいしか使ってない。
我々が作っているモデルはこういう制約はあるし、社内リソースも100人くらい開発体制があって作れるっていうわけではないんだけれども、そういった中でちゃんと目標集中しようということで、今回の「GENIAC 1.0」に関しては、応募の時点でまず、日本語関連能力「Jaster」と、あとは対話能力「MT-Bench」で結果を出すというところを目標に立てようと、それを中心に改良を進めました。
◆学習方法
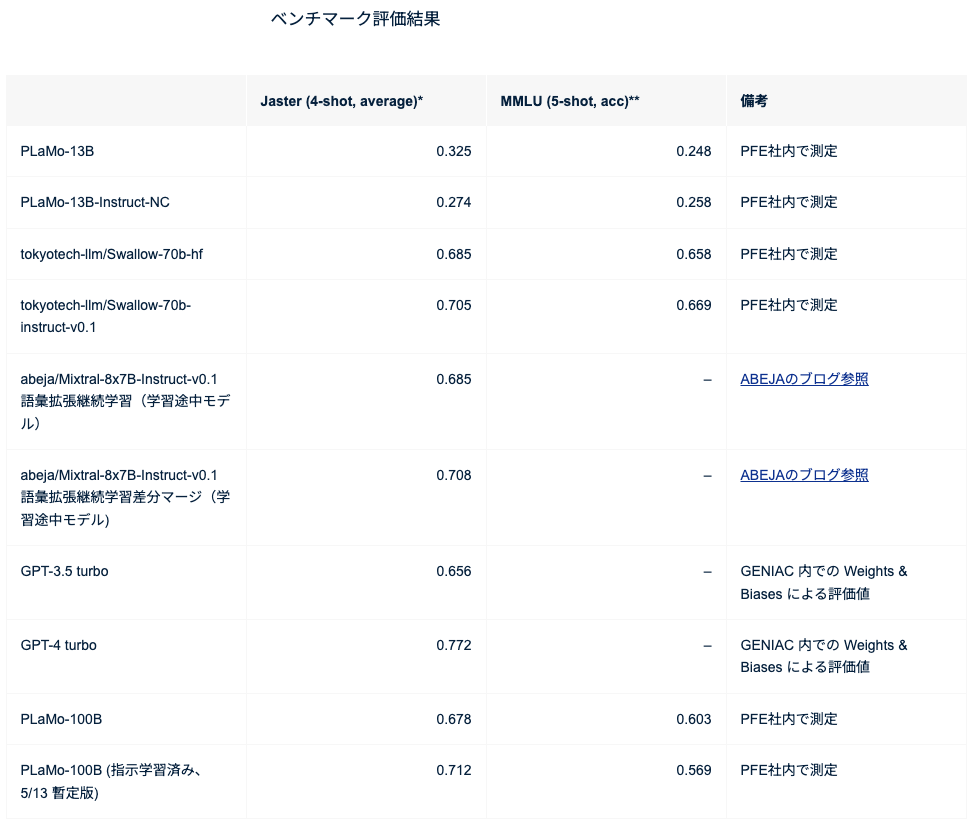
まず、事前学習は5月ぐらいに終わっていて、この時点ではJasterが0.678くらい(1点満点)だったんですけれど、ここからさらにPost-training(事後学習)でどのくらい上げられるかっていうのを強化学習に強い人たちとかKaggle勢からなるアライメントチームが頑張りました。
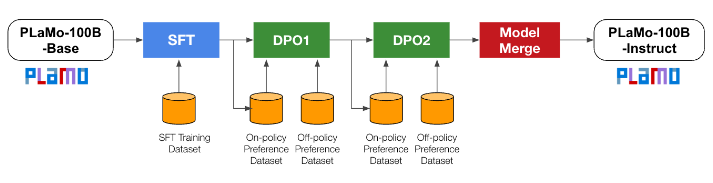
その中ではこういうパイプラインを使っています。まず最初にベースになる今回の事前学習(Pre-training)のモデルがあって、それにsupervised fine-tuningといって、正解付きのトレーニングデータセットを加えた後に、常にその正解を予測できるようにチューニングする。
その後にDPO (direct policy optimization)って呼ばれるアライメントの方法を2回反復させていて、最後に、ある能力に特化したモデル2つ持ってきて、それをガチャンとくっつけるというモデルマージをして今回の最後のモデルができています。
◆学習の工夫
まずそもそもsupervised fine-tuningっていうのは質問と答えのペアがあって、それでチューニングするっていう話です。
DPOに関しては、ちょっと前とか今でもRLHF(reinforcement learning from human feedback)という人間のフィードバックによる強化学習というのが使われていたりするんですけれども、それって結構学習不安定だったり学習しづらいっていう問題があって、最近だとこのDPOを使うのがかなり主流になっています。
DPOの場合も、2つの同じ質問に対して、例えば「日本の首都はどこですか」というのに対して「そういう質問はよく聞かれます」って答えるのと「東京です」って答えるのでは「東京です」の方がいいわけです(前者も次のトークン予測という意味ではあっている)。
「東京」の方を選ぶようにパラメータを更新するのを、本当は強化学習みたいな枠組みで解かないといけない。それをうまく式変形していくと、普通の最尤推定のような安定して学習できるような定式化にできて、それでスケールできるっていうのがこのDPOになっています。
しかも2回反復していて、1反復目である程度賢くなったもので再度それを評価をして、その評価自体も賢くなったLLMでやっていて、それで賢くしていくっていうのをやっています。
あとはデータ生成のところもかなり力を入れてやっていて、従来のLLM開発だと、かなりの人で工数をかけて「こういう回答がいいんじゃないか」とかの正解データを作るんですけど、我々がそこで競争するのはお金もないし時間もないし難しいので、基本的にはデータ生成をプログラム使ったりLLM自身を使って生成するっていうことを進めていました。
ここに関してもかなりいろんな工夫をしていて、そこが最終的な結果に貢献していると思います。
(次回へ続く。後半は成果と今後の課題、モデルの将来性などについてのトークです。)

