Vol.8 小規模言語モデル(SLM)リリースの裏側
◆小さいモデルの開発背景
今回PLaMo-100Bという1000億パラメータのモデルを作っていた中で、訓練データの品質がすごく改善されていって、後半になればなるほど高品質なデータを集めたり、構築するノウハウができた。
あとは、ポストトレーニング(事後学習)ですね。SFT(supervised fine-tuning)と呼ばれる教師あり指示学習と、DPO (direct policy optimization)と呼ばれるアライメントでちゃんと指示を聞いてくれるようになって、いろんなタスクをこなせるようにするという部分も急速にノウハウができていきました。
そうした中、実はPLaMo-100Bを開発する中で、小さいモデルをこのタイミングで開発・リリースしていく予定はなかったんですが結果的にできました。
プレトレーニング(事前学習)の開発チームは基本的に、検証のために小さいモデルをずっと作り続けています。いきなり100Bとか大きいモデルを作るといろいろな問題が起きるので、刻んで1Bとか3Bのモデルを作るというのが計画に入っています。
今回の1Bと3Bのモデルは、小さいモデルを最初から作りたいというわけじゃなくて主に開発の検証目的で作っていました。
◆小さいモデルの性能と他社比較
1Bと3Bのモデルを事前学習が終わった段階で評価してみると、1Bだから小さいよね、性能そんなに出ないんじゃないの?って思ってたところが、結構できるっていうのが分かりました。
そこで、これくらい性能が出るんだったらポストトレーニングも既に作っているものがあるからそれをちゃんと組み合わせてやってみよう、という風に評価してみたら、想定していたよりもすごく性能が出たというのがあります。
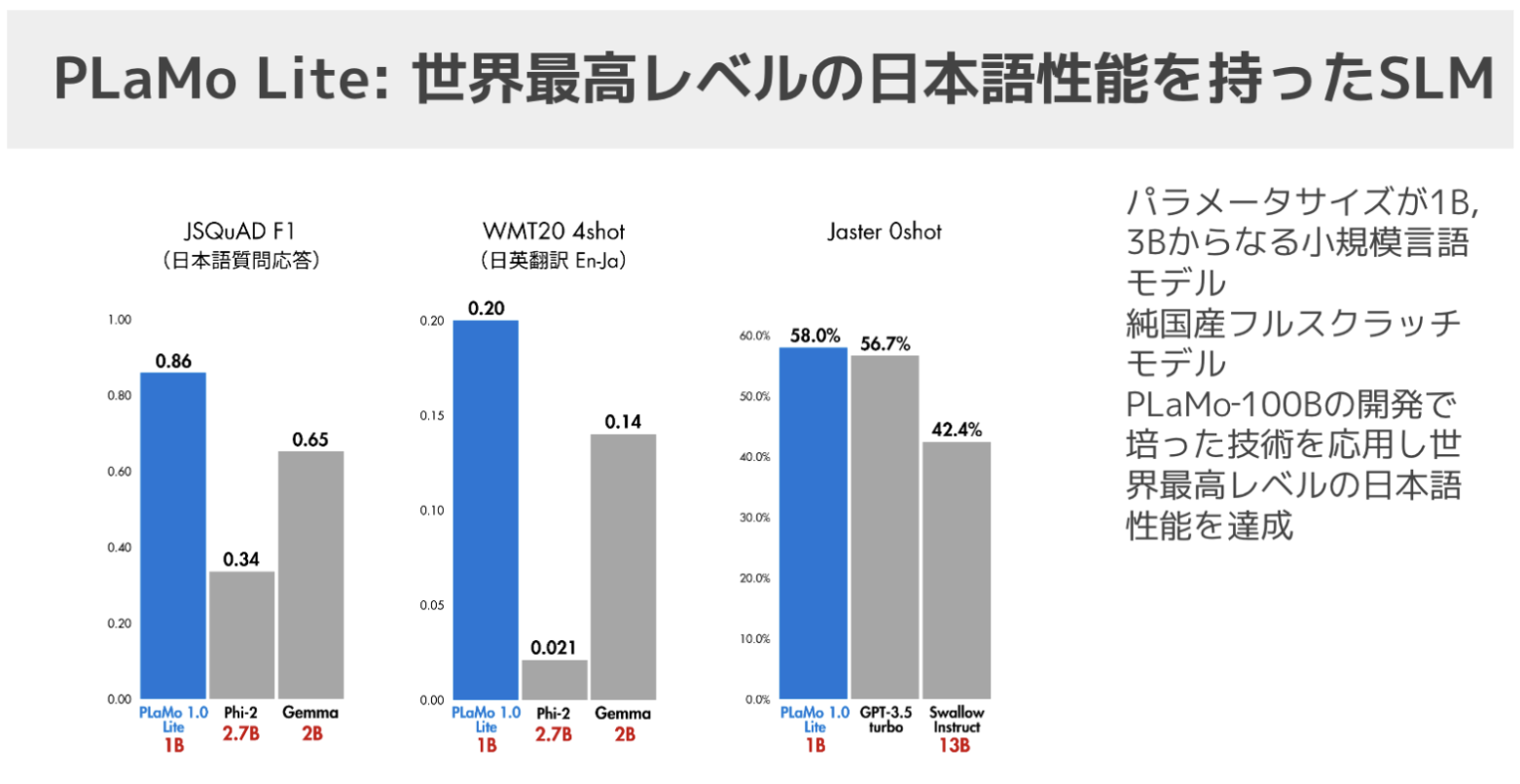
これが1B(PLaMo 1.0 Lite)の結果なんですけども、左側のJSQuADという日本語質問応答とWMTで、こういう性能が出ています。
世の中にいくつか出てきている他の同じようなサイズのモデルの中で、たくさんあるんですが、代表的なのがマイクロソフトが作っているPhiシリーズと、グーグルが出しているGemmaシリーズです。
この2つは非常によくできていて、特にMMLUとか結構ちっちゃくても性能いいよ、というのがあるんですが、日本語生成や日本語タスクをやらせようと思うと結構壊れちゃうというのが分かっています。
実際、今回評価したところでもPLaMoの小さいモデルの方が大きく勝っていて、日本語質問応答とか日英翻訳の英語から日本語の結果とかを見ると、PLaMoがちゃんと結果を出せていて、他のモデルがまだうまくいってないというのが分かりました。
これくらいのサイズでちゃんと日本語を扱えるようになったというところでは、ある意味初めてのモデルになっているというふうに思います。
これから、同じように小さなモデルで日本語タスクでもうまくいくモデルがたくさん出てくると思うんですけれども、そもそも日本語のデータを集めて良い性能を出しているようなPLaMo-100Bのデータセット構築と事前学習と事後学習のノウハウを適用しているので、小さなモデル開発においても競争力があると思います。
大きいモデル向けに作られたポストトレーニングもうまくいっていて、例えばJasterとか、MT-Benchって呼ばれる対話しながらいろんなタスクをこなせる、というところも性能が実際上がってます。Jaster 0shotだとPLaMo Liteが一番良くて、このJaster 0shotの58.0%っていうのはSwallow-13BとかGTP3.5 turboに勝っていますし、他の多くの大きなサイズのLLMにも勝っている数字です。
◆小さいモデルの需要と応用
このモデルをこれからリリースしていくんですけれども、世の中で話を聞いてみると結構小さいモデルを使いたいっていうお客さんが特に産業領域とかエンタープライズ領域で非常に多いです。
代表的なのが自動車で、自動車でも中で音声で対応したり、いろいろなインターフェースとして使うっていう例もありますし、ちょっと先の話なんですけども、自動運転のような部分でLLMとくっつけるというようなのも研究として進んでいるので、非常に興味を持っていると聞きます。
自動車は移動中にずっとクラウドにつないでいるわけにもいかないし、ネットワークが切れる場所とかいくらでもあり、ネットワークの先のシステムに頼っていられないので、そういったところが非常に需要がある。そういうところで日本語をちゃんと使えるモデルがなかったので興味を持っていただいています。
あとは産業領域の、例えばエッジで動くようなデバイスのところは、いろいろある話の中でもむしろ小さいモデルの方が興味があるというふうに話をいただいています。
◆ロボティクス分野での利用
あと、まさにプリファードロボティクスでやっているようなロボットの領域でも非常に需要があります。ロボットも今はまだデバイス側で高性能なLLMが動かないなか、基本的にクラウドに繋ぎながら動かしているんですけれども、デバイス内で動かしたい需要があります。
プリファードロボティクスのカチャカっていうロボットは、クアルコム社のチップが乗って動いてるんですけど、そういうチップの上でLLMがそのまま動くと良いっていう話はあって、そういったところでは小さいモデルを使っていくことが今後増えてくるように思います。
こういう小さいモデルをSmall Language Model(SLM)って呼びます。私が20年前に大学で言語モデルの研究をしていた時よりまだめちゃくちゃ大きいんですけれども、とはいえ10億パラメータだとか、もっと小さい3億パラメータや1億パラメータだとか、そういったものも今いくつか出てきていて性能をどんどん上げようとしています。
そういったものがなんで前はできなくて今できるかっていうと、先ほど言ったデータの品質がめちゃくちゃ上がっているのとポストトレーニングのところが変わった、というのがあります。
◆データ品質とポストトレーニングの重要性
データの部分はどれくらい品質が変わったかというと、例えばPLaMo-1B(PLaMo 1.0 Lite)の性能とちょうど1年前に作られたPLaMo-13Bの性能を比べると、1Bの方がかなり勝っているんですね。
1Bと13Bってアーキテクチャは何も変わってなくて、学習の工夫もほとんど変わってなくて、変わったのはデータの質のところだけです。なので、モデルサイズとか投入計算量の10倍分ぐらいの差はうちで言えば1年ぐらいのデータの質の差でこのくらい性能が変わっています。
こうしたデータを作る部分でLLMをものすごく使っています。いいデータをフィルタリングするためにLLMで学習データを作って、分類器を使って学習に有効なデータを分類するというようなこともやっていたり、LLM自身で生成したデータを使うというのもやっています。
いろんなものを今まさにオンゴーイングでどんどんデータ作ってるんですけれども、PLaMo-100Bがあって、特に日本語の生成に関しては性能もいいし使い勝手もいいので、そういうところでPLaMo-100Bをデータ構築に使っているところが競争力になっていると思います。
大きいモデルを今後もお客さんのところで使っていただくというのもあるけれど、開発の部分でもこういう強いモデルを社内で自由に使えるようになっているということ自体が競争力になると思います。
2つ目のポストトレーニングのところに関して話すと、一昔前までは「どういう指示に対してどういう結果がいいのか」だとか、よくアライメントである「こういうのはしちゃダメですよ」だとか、そういったアライメントのデータというのは大量の人によるアノテーションで行われていて、OpenAIとかは最初の頃やってました。
今はLLM自身の性能が上がってきて、LLMが「このデータはいいです」って判断して、そういったものが人がアノテーションをつけるのにも匹敵もしくは超えるような性能で出せるようになってきています。うちの場合だとポストトレーニングのところでも人によるアノテーションをほとんど使わずにできていて、そこではどんどんデータも作れるという風になっています。
ここも非常に競争領域になっていて、今だと例えば数学とかプログラミングの性能が特にものすごく上がり続けています。そういった問題に関して言うと自動的に評価ができて、正解データを作ることができる。
例えば数学だったら、ある証明をするとき、証明が成功したかどうかって自動判定できますし、プログラムも例えばコンパイルが通っただとか、テスト通ったっていう形で検証を自動的にできるので、ぐるぐるデータ生成して検証して、うまくいったものを正解として入れるっていう、そういったポストトレーニング側の進展も取り込んでいこうと考えています。

