Vol.9 状態空間モデルとトランスフォーマーの進化
今日は、状態空間モデル(State Space Model)と呼ばれるトランスフォーマーの後継と期待されるモデルの話をさせていただけたらと思います。
◆広く普及しているモデル「トランスフォーマー」
トランスフォーマーというモデルが今広く使われていて、特にLLMとかではデファクトでみんな使っているし、画像認識もViT(Vision Transformer)という名前で使われています。何か処理したいなという場合には、トランスフォーマーをとりあえず使っておくという風になっています。
あまりにもトランスフォーマーが世の中で使われるから、トランスフォーマー専用のチップが出てきたり、ライブラリとしてもトランスフォーマーで特にボトルネックになる自己注意機構の部分が速くなるようなフラッシュアテンションのような、ものすごくチューニングされたライブラリが出ているので、みんなとりあえずトランスフォーマーを使おうという風になっています。
◆トランスフォーマーの問題点
一方で、トランスフォーマーがこのまま全部に使われていくかという観点でいうと問題がいろいろあるのは分かっています。一番の問題とされているのが、入力が大きくなるにつれて計算時間とか使うメモリの量が急激に大きくなってしまうというのがあります。
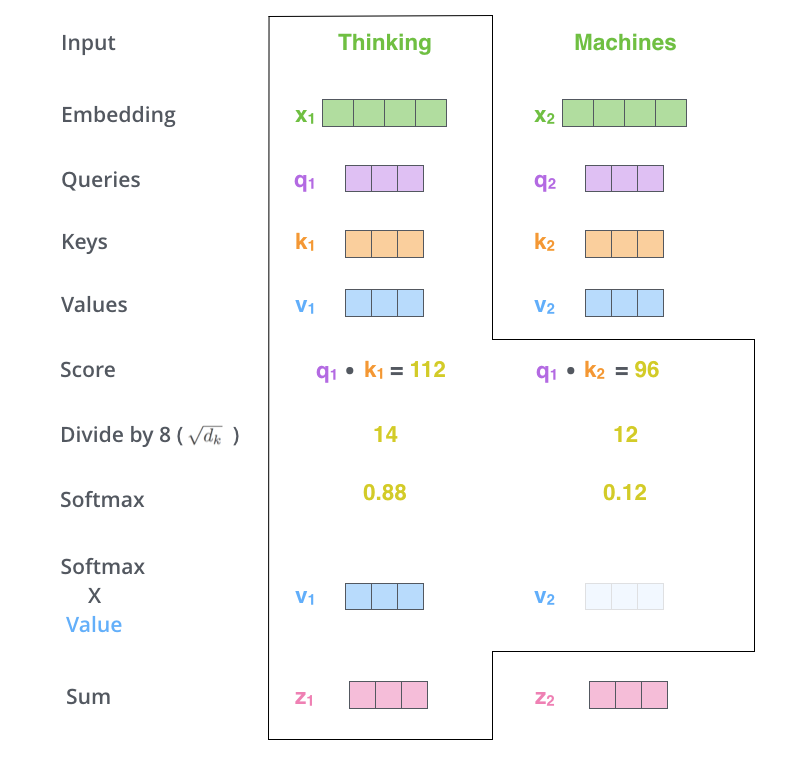
出典:https://jalammar.github.io/illustrated-transformer/
それを説明するために、トランスフォーマーを知らない人向けにこの図を見せながら説明します。トランスフォーマーはトークン列を入力とします。ここで「Thinking」と「Machines」となっているところです。
そして「Thinking」っていうトークンに対して、「Embedding(埋め込み)」とよばれるベクトルを計算して、それを元に「Queries(クエリ)」と「Keys(キー)」と「Values(値)」っていう3つのベクトルを出します。ベクトルというのは値をいくつか並べた塊とおもってください。
この「クエリ」と「キー」と「値」がどういう役割をするかというと、「クエリ」はその位置で自分がどういう情報が欲しいかを表していて、「キー」は自分はこういう情報を持っているというのを表しています。
そして「キー」と「クエリ」が近ければ、そのキーの位置にある情報をクエリの位置に持ってくるという意味になっています。このベクトルは向きを持っています。この向きが同じ向きを向いているときに近いというようにいいます。
そして、具体的に何の情報を持ってくるのかというと「値」を持ってくるという風になっています。まとめると、それぞれの位置で、クエリと近いキーがどれかを調べ、近いキーの位置にある値を集めてきます。
トークンがたくさんあった時に全ての場所の「クエリ」において全部の位置の「キー」とどれと似ているかっていうのを調べます。全てのクエリと全てのキー間で調べる必要があります。これがトランスフォーマーの一番コアになっている部分です。これによってトークンのいろんな場所から自由自在に情報を取ってくることができます。
しかし、ここが問題点です。トークンの数がN個あると、N × Nのクエリとキーの関係を調べなければなりません。今のLLMとかコンテキスト長が4Kです。この場合4000×4000の関係を調べる必要がありますし、コンテキスト長が100万だったら100万×100万の関係が発生して、そうなると途端に計算量が爆発して大変になります。
今話したのは学習の時なんですけど、推論の時にもまったく同じ話があります。推論の時には1個ずつ生成していくので、その時には途中で処理したこの「キー」と「値」だけ残しておきます。後で使う時には今の生成しようと思っている場所のところで出力した「クエリ」と過去の「キー」を評価して「値」を取ってくればよいです。
その「キー」と「値」もそのコンテキストが長くなればなるほど大きくなって、これが毎回ものすごい量の「キー」と「値」を1トークン生成するごとに全部メモリに読み込まなきゃいけないっていうのが推論のボトルネックになっていて、これが推論が遅いことの原因です。
これがトランスフォーマーの一番の問題点で、これを解決するためにはどうしたらいいかっていうのをいろんな人がいろんなことを提案してるんだけど、まだ決定打が出てない。
◆状態空間モデルの有望性
今一番その中で有望視されているのが、この「キー」と「値」のような過去の情報を常に固定長に圧縮する方法です。これを状態空間モデル(ステートスペースモデル)と呼びます。
状態空間モデルの中でもMambaが特に有名ですが、Mambaの前に歴史がたくさんあります。この状態空間モデルってすごくRNN(リカレントニューラルネットワーク)と似てます。
RNNの一部は状態空間モデルだし、状態空間モデルの一部がRNNなんで、基本的にはほぼ親戚なんだけど、ざっくりと一番何が違うかっていうと、RNNの場合には内部状態を順に更新していくのだけれど状態を更新するときに何らかの非線形性が入っています。
ある内部状態のときに入力が来て次の内部状態に変わるとき、RNNは何か非線形性を入れるんだけども、状態空間モデルの場合にはそういう非線形性が何も入っていないモデルになっています。

例えば今ここで見せているのが状態空間モデルの例になっています。入力xtがトークンに対応します。xtにBtで変換をかけます。また内部状態h_tを持っています。内部状態はA_tという線形変換で変換した結果と、入力x_tにB_tで線形変換した結果を足します。出力は内部状態にC_tという線形変換をした結果で得られます。全部線形変換なので、全体としても線形変換です。
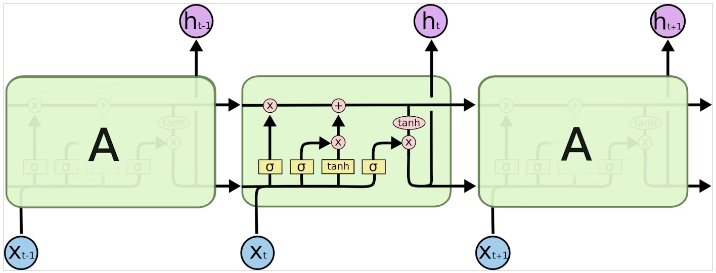
出典:https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca
これに対し、RNNの場合には内部状態が変わる場合に非線形性が入っています。例えばLSTMとかは上の図のような形で変換されます。この中で、σ、tanhとかかれているような部分が非線形変換です。すごい不思議な式に見えるけどよく考えられて作られているこういう式に従って次の状態が決まるようになっています。
このように状態空間モデルの方がRNNよりより簡単なモデルになってるんですけど、実はこれが重要だというのが分かってきました。
なんでかっていうと、まず学習の時に状態遷移に非線形性が入っていると、入力でどこかが入れ替わった時に出力がどう変わるかという間に何回も何回も非線形性が入るので勾配消失問題がおきてしまいます。これは入力をちょっと変えたら出力がめちゃくちゃ変わってちゃったりもしくは全然変わらなかったりするような問題が起きちゃうんだけども、線形になっていればそういった問題が起きないっていうのがあります。
あとは、状態が線形で変わっていくモデルはものすごくよく研究されていて、制御理論でもう50年ぐらいの歴史をもって研究されているので、いろんな技がそこで使えるっていうのもよく分かっています。そういうのが使われていくのは今後だと思うんですけど、よく分かっています。
この状態空間モデルは数年前から使われていて、これのいいところは固定サイズの状態で表されるとこ。入力がどれだけ長くなったとしても、すごく長い情報を一定サイズで表すことができます。
(次回へ続く。後半は状態空間モデルの問題点とMambaの登場、最新のモデル進化などについてのトークです。)

