Vol.10 状態空間モデルとトランスフォーマーの進化(後半)
◆状態空間モデルの問題点とMambaの登場
一方で、この状態空間モデルは有望だったんだけども言語モデルに関してはなかなかトランスフォーマーのような性能が出ないっていうのが分かっています。

Mambaっていう去年の12月ぐらいに出た論文でわかったこととしては、今までの状態空間モデルでは内部の線形変換する部分(上記のA, B, C)は時間とともに変わらないのをつかっていました。しかし、これらは、入力依存にして変えるっていうのが重要だというのが分かりました。
これがどういう時に役に立つかっていうと、特に言語の場合、例えば「あー」のような意味のないことを言ってる時と意味のあることをいっている時があります。このとき、AやBのような行列が一定だとすると、常に入力情報が隠れ状態に入っていくというのがおきてしまいます。意味のない入力は無視すべきです。
なので例えば、入力に応じて「あー」とか言ってる場合には、Bとかはその時にはほとんど情報を消すようになっていて、Aっていうのはほぼ情報を残すようになっているっていう風に、入力に応じて変えられることとかができるようになります。
その他にもいろんな表現力が一気に上がるし、特に「In-context Learning」のような過去のコンテキストに応じてモデルが変わってあたかも学習したことのように能力が変わるっていうようなところも、重みが変わらないとそういうのは起きないんですけど、おそらくそういう能力も入力に依存して重みが変わると起きると思われます。
Mambaっていうのはそれを導入して、入力に応じてパラメータを変えるようにして、モデル自体は非常に単純なモデルを使ってやっています。固定サイズのモデルでうまくできるようにトランスフォーマーと同じような性能でいろんなタスクを達成できるようになったというのが去年の12月ぐらいの話です。
◆Mambaの性能向上
そこから先に進みまして最新の話で今どうなっているかっていうと、まずMamba2っていうが5月ぐらいに出てきていて、これはこれですごく理論的に面白い話なんですよ。しかし今回は理論面でなく実用面の話です。Mambaは入力に依存してモデルが変わるってなったんですけど、トランスフォーマーよりちょっと遅い。今の大規模学習はとにかく学習が速くないともう使えない。
今はとにかく、どれだけ学習データ投入できてたくさんモデルをアップデートできるか勝負なので、ちょっとでも速度が落ちちゃうとダメ。Mambaの時にはパラレルスキャンと呼ばれる並列で効率的に計算できるような方法を使って学習できるという部分で工夫して、それによって入力ごとにパラメータが変わったとしても効率よく学習できるようにしたんですけれども、それでもまだ遅い。
今のチップ、特にNVIDIAさんの最新のチップはとにかく行列積の演算がTensorコアで速いということが肝で、それを使えないと性能が出ないので、とにかく行列積を使うような縛り芸としてやらないといけなくなっています。

Mambaも同じように行列積の問題に帰着できるようにこの式を変形させないといけないということになりました。どうやるかっていうところで、このMamba2では論文の90%ぐらいは理論的な解析で、全部すっ飛ばして説明すると、このAっていう行列をスカラー値(1つの数字)にします。これを行列じゃなくてスカラー値っていうのもすごい表現力落ちちゃうんだけどもスカラー値にする。
これによって演算する順番を変えることができて、さっきのBとCの演算を先にすることができます。大きな行列積を先にすることができる。これによってMamba2はほとんどの計算っていうのを行列積を使って行うことができます。また推論のときには、状態空間モデルとして効率的に固定の記憶容量でできる。
◆最新のモデル進化と競争
一方でこの状態空間モデルでトランスフォーマーは全部乗り換えられるのかというと、実際そんな状況じゃなくて、状態空間モデルだと苦手な問題があるよねっていうのが色々わかっています。
逆にトランスフォーマーのモデルもこういうタスクはできるけどこれ苦手だよねっていうのがわかっていて、帰納バイアスが入っているしモデルの表現力的にも差があって、モデルとしては汚いんだけども、いいとこどりで層ごとに、ある層はトランスフォーマー(自己注意機構)を使って、ある層はMambaのような状態空間モデルを使ってっていうモデルがたくさん出てきています。
出典:https://arxiv.org/pdf/2408.12570
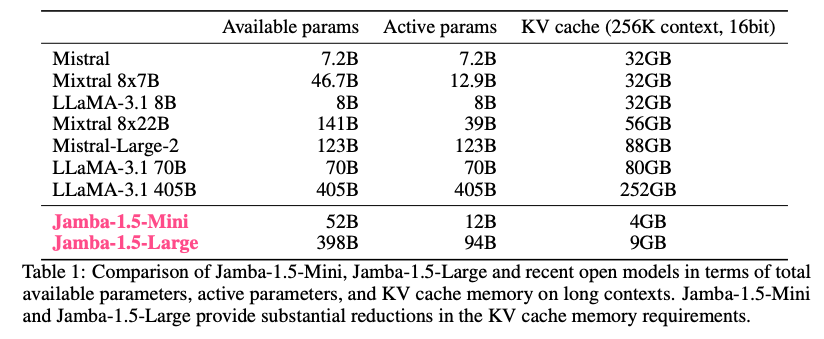
いろいろあるんですけど、例えば一番最近出たJamba1.5というモデルは、これはトランスフォーマーとセルフアテンションのモデルとMambaを交互にやっていて、交互といっても大体がMambaで一部分だけトランスフォーマーのモデルになっています。
これによって記憶しておかなければいけない過去の状態を劇的に減らすことができてます。こういうモデルが今いろいろできています。
なので、どれか一つの方法を取ったら全部解決という感じでなくて、絶妙なバランスがあって競争していると思います。
そういうことで、Mambaは去年の12月ぐらいに出てすごく注目されていて、ポストトランスフォーマーっていろんな人が提唱した中では一応生き残っていて、徐々に使われています。

