Vol.14 番外編 テキスト埋め込みモデルの開発
こんにちは、エンジニアの鈴木 海渡です。2024年の夏季インターンシップでインターンの九門 涼真さんにやっていただいた研究なんですけれど、PLaMo(プラモ)をベースにしたテキスト埋め込みモデルの開発というテーマで進めてもらいました。
◆ テキスト埋め込みモデルとは
そもそもテキスト埋め込みモデルは何かってところを一応補足すると、文章をある数値の列に変換するっていうのがテキスト埋め込みモデルと呼ばれる技術です。
これによって何ができるかっていうと、一回文章を数値列に変換して、例えばその数値列にすると、その数値列同士の距離を取ることができるんですね。そうすると、「この文章とこの文章は似ている」とか、逆に「この文章似ていない」みたいなことが測れるようになります。
これを使うと、一例としては検索みたいなことができるんですね。例えば「入力の文章をGoogleのような検索エンジンに入れて、それにマッチするようなウェブページを取ってくる」みたいなことができます。
Google検索は内部的にこれを使ってるか分からないですけど、類似の文章かどうかを判定して引っ張ってくることで検索をすることができるっていう、そういった役立ち方が考えられます。
最近のLLM関係でいうと、RAG(Retrieval-Augmented Generation)というのが流行ってますが、これも内部的には一つの検索方法として、テキスト埋め込みモデルを使って文章をベクトルに変換して、ユーザーの入力に対して似た文章を持ってきて、その検索結果を反映した上でLLMに回答を書いてもらっています。単に検索なしでChatGPTとかに聞くよりは、より検索結果を反映した良い回答が得られる、そういった技術になっています。
◆テキスト埋め込みモデルの応用
こういうテキスト埋め込みモデルがなるべく性質の良い、よく似た文章を綺麗に引っ張ってくれると嬉しいというところで、そのようなテキスト埋め込みモデルの研究開発が結構前からあるんですけれど、今回はその発展に取り組んだということになります。
流れなんですが、そもそもテキスト埋め込みモデルには実際どういうモデルが使われているかというと、いわゆるトランスフォーマーを使っています。これはChatGPTのようなLLMの背後で動いているモデルと基本的には同じです。
ただ、もともと昔からあるテキスト埋め込みモデルは、ChatGPTみたいなものとはモデルの形式が少しだけ違って、トランスフォーマーの形式が双方向になっているか、それとも一方向になっているかという違いがあります。
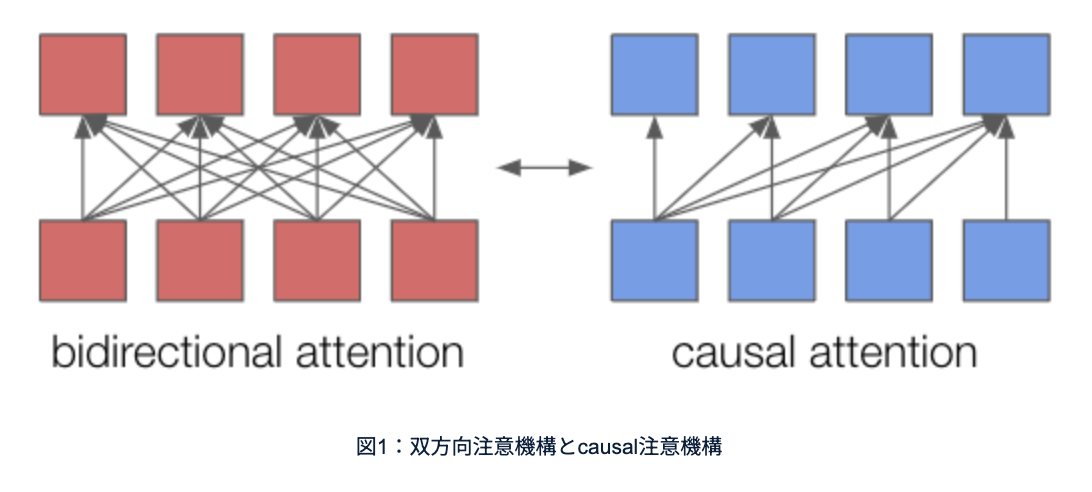
双方向注意機構(bidirection attention)とcausal注意機構(causal attention)というのですが、(細かいところの説明を省くんですけど)ChatGPTみたいな文章を書いていくモデルは順番にトークンを書いていくわけなので、過去に出力したトークンは次のトークンのための計算への入力として反映されるんですけど、逆に未来から過去に向かってのパスは存在しないんですよね。
あるトークンを生成する時に、まだ書いていない未来のトークンは当然知り得ないわけなんで、それは使えないからなんですけれど、テキスト埋め込み数値列を計算する時は別に未来から過去に向かっての情報があってもいいので、双方向の注意機構が使われます。
具体例を出すと、GPTみたいなcausal注意機構が使われているモデルは、「decoder only model」みたいな文章を出す時、「only」を出すときは「decoder」が入力に入っているが、「model」は入っていなくて、「model」を出す時は「decoder only」が入っていて、と言うように、LLMだとトークンを出す時に後ろの方のトークンは入ってないんですね。
ただ双方向注意機構だとどっちの方向も反映していいということになります。さっきの例でいえば、「only」の埋め込みを計算する際に「decoder」「model」両方考えてよくて、双方向に埋め込みを作ってその結果を平均して1つの文章全体のテキスト埋め込みを作る、そういう機構になっています。
双方向の注意機構の方が基本的にはテキスト埋め込みにおいては強力だと言われているんですが、最近のLLMのような言語を生成するモデルは一方向のアテンションになっています。
ここに違いがあるんですけれど、最近海外で、一方向のアテンションしか使われていないLLMモデルを双方向のモデルにコンバートしたら実は良いテキスト埋め込みモデルになるんじゃないかっていう研究が出てきました。
もともとテキスト埋め込みモデルって双方向のモデルの中で研究されてきたんですけど、LLMの時代になってcausalな制約があるモデル、その中で結構大きなモデルとかがどんどん登場してきたので、LLMを双方向に変換した上で、テキスト埋め込みとしてチューニングすれば、その強力なパワー活かせるんじゃないかという文脈でこういう話が出てきたことになります。
◆研究開発の内容と結果
ちょっと前置きが長くなりましたが、こういう文脈でPLaMo(PLaMoはcausalなアテンションが入っているLLM)を双方向に変換してテキスト埋め込みモデルにしたらどれくらい強くなるだろうっていうのが今回の研究になります。
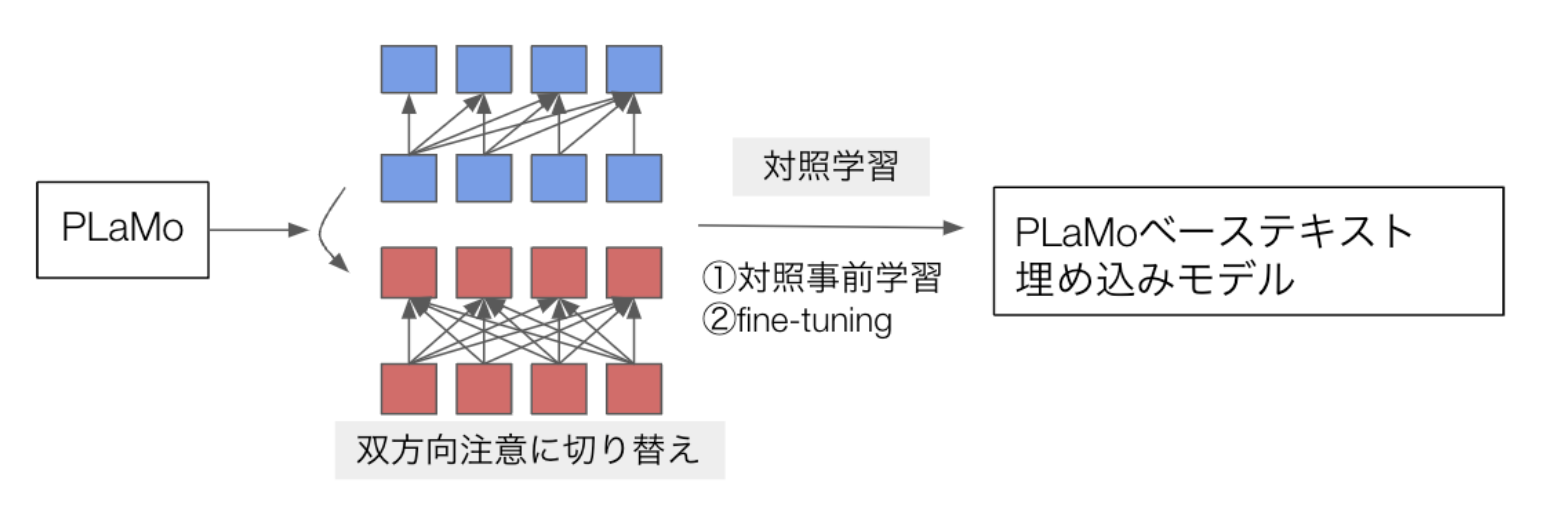
まずざっくり手法を話すと、まずPLaMoの1Bモデルを双方向注意に変換して、対照事前学習した後にファインチューニングするという学習方法を取りました。これは結構細かい話なので詳細を省くんですけど、こういうテキスト埋め込みモデルを作るときの典型的な学習方法の一つです。
もっと分かりやすく結果みたいなところを喋ってしまうと、結構がっつり性能が上がって良い結果が出ています。
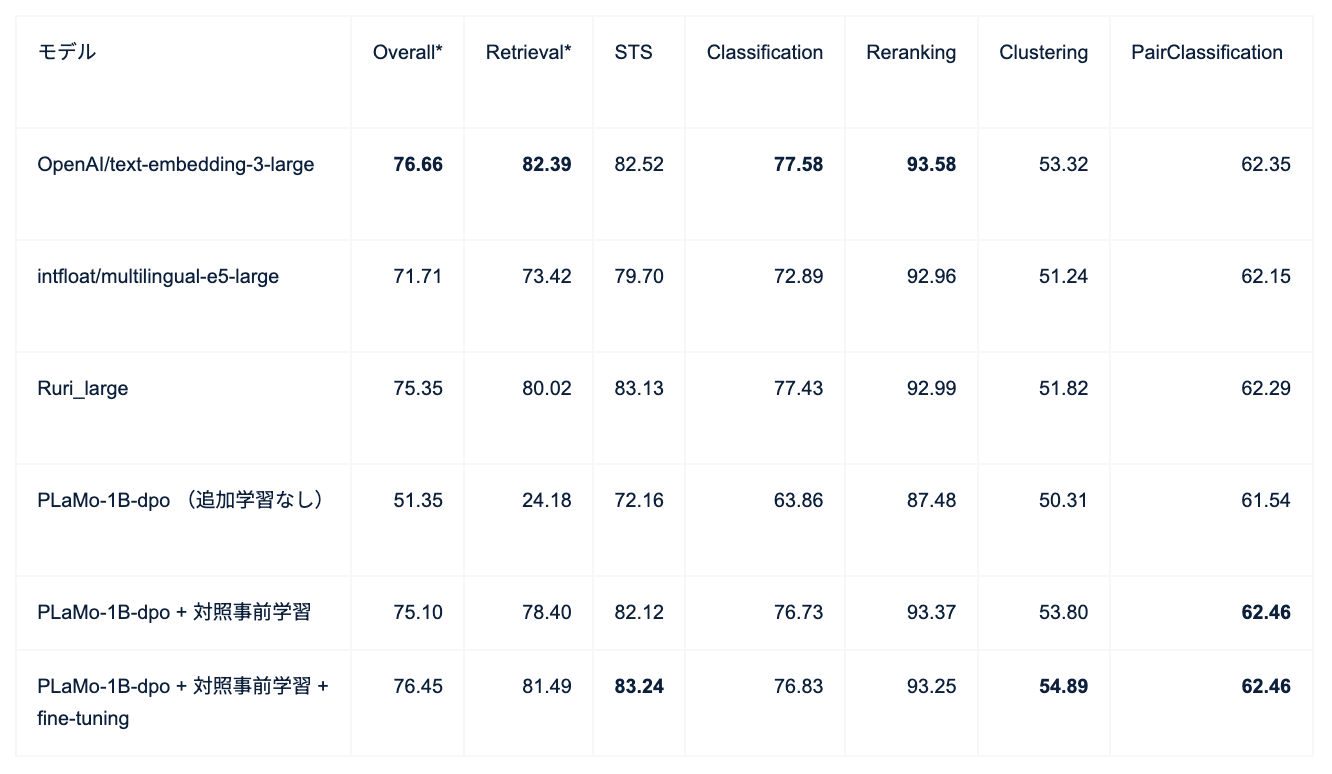
PLaMoのモデルをベースにしてさっきの二段階の学習を入れた結果として、JMTEB(日本語テキスト埋め込みベンチマーク)で性能を測りました。
全部のベンチマークに含まれているデータセットの平均値で、「OpenAI/text-embedding-3-large」というのが一応一番強いモデルなんですけど、その76.66というスコアに対して76.45っていうかなり近い、もうちょい上手くいったら勝てるんじゃないかくらいのスコアが達成できています。
◆まとめと今後の展望
これがなんでこんなに上手くいったのかってところなんですけれど、一つは元々PLaMo-1Bモデルをベースにして学習したんですが、この1Bモデルに対して、単に事前学習しただけのモデルと、それにSFT(Supervised Fine-Tuning)っていう追加学習みたいなことをやって人間の視点に従いやすくしたモデル、あともう一個DPO(Direct Preference Optimization)っていう強化学習のような学習をしてより人間の視点に従いやすくしたモデル、この3つを比較してみると、学習とかチューニングする前段階の時点で、DPOを使った方が、特に検索タスクで事前学習とかSFTより良かったという結果が得られています。
テキスト埋め込みの学習はDPOとかで目指しているような、普通の人間と対話するための学習とは違うんですけれど、検索タスクに関しては結構がっつり上がるというのが見られたっていうのが一つの理由だと思います。
あとはそうですね、「Ruri_large」というモデルが最近出た非常に強力なテキスト埋め込みモデルの手法がありまして、今回の学習の流れとしてはこれにかなり倣ってるんですが、PLaMoのチューニングはこのモデルよりもかなり少ないデータでもうまくいったというところで、元々のPLaMoの能力をうまく活用して、比較的少ないデータで良い結果を出せたというのがもう一つの理由かなと思います。
まとめると、PLaMoをベースにして、もともと双方向なアテンションで研究されてたテキスト埋め込みの文脈から、単方向のLLMを双方向に変換した上でテキスト埋め込みに変換するっていうパイプラインでうまく学習して、日本トップクラスの性能を得ることができたということになります。
今後、こういうところをベースにうまく追加開発とかをして、例えばより強力なPLaMoベースのエンべディングモデルみたいなものを出せていくと面白いんじゃないかと思っています。

