Vol.15 Meta Movie Genの解説
今日はMetaのムービージェンを紹介したいと思います。(公式サイト)
多分Zoomではちょっとカクカクしているのではないかと思うんですけど、手元で見ていただければすごくスムーズに、かなりリアルに動いていると思います。
今年、動画生成の技術がかなり進展していて、一番最初はOpenAIからSoraというのが出て、その後にいろんな会社や研究機関から動画の生成サービスが出て、先日メタがムービージェンっていうのをリリースしました。
◆ Meta Movie Genの概要
メタムービージェンはオープンではないんですけれども、論文で主張しているところと、出しているクオリティからすると、リアリティとか多様性、あと編集性に関してはトップクラスになっています。

上のように可愛いカバが泳いでる動画が出せたりとか、あと編集ですね。

これは、左側の灯籠を飛ばしているような映像を「シャボン玉に変えて」っていう風にすると変えることができたりします。

これが今回の特に大きなネタなんですが、右上にある写真を条件付けにして動画を生成できるようになっています。
なので、一気に有効な技術になるとともに危険性が増しています。もう実写と見分けがつかなくなります。本当にちょっと危険な技術なので、それもあってオープンにしてないのかなっていう考え方もあります。

あとですね、動画に合わせてサウンドを生成することもできるようになっています。これが今回の特に大きなネタなんですが、右上にある写真を条件付けにして動画を生成できるようになっています。
なので、一気に有効な技術になるとともに危険性が増しています。もう実写と見分けがつかなくなります。本当にちょっと危険な技術なので、それもあってオープンにしてないのかなっていう考え方もあります。

編集のところを見ると、例えばこれ結構難しいと思うんですけど、オリジナルビデオの照明がバンバン当たっているのを外してやるとか、エフェクトをかけさせたりとか。
結構インパクトある動画が作れちゃうっていうものですけど、後で説明しますがすごく簡単な仕組みで実現しています。
◆ 実現している技術の詳細
ここからは中身、今みたいな動画生成がどうやって実現されているかっていう話を一般の人でも分かりつつも、とはいえ技術者もちゃんとご満足いただけるような粒度でちょっと頑張って説明しようと思います。
中でやっている技術は、基本的にはOpenAIのSoraとかと同じような技術で「拡散モデル」をベースにしているんですけれども、拡散モデルではなくて拡散モデルの親戚の「フローマッチング」と呼ばれる技術を全面的に採用しています。
フローマッチングっていう技術はメタが提案者でもあるので、メタが大規模に使っているんですけど、今回この動画生成においてはフローマッチングを使って本格的に成功したということで、もっと注目を集めることになります。
フローマッチングと呼ばれるアプローチは拡散モデルに比べて単純なだけじゃなくて、特に動画の生成においては生成品質にかなりの違いが出ると報告されています。
なんでかというのをわかる人向けに説明すると、拡散モデルっていうのは画像にノイズを加えていって完全なノイズにして、そうなる過程を逆向きに辿ることでノイズからデータを生成します。
実際には今の話には嘘がありまして、ノイズを加えていったとしても生成の時にスタートとなるガウシアンからのサンプルと見分けがつかなくなるようになるまでには無限大の時間が必要となります。ずーっとノイズを加えても、絶対にデータの成分がちょっと残っちゃうという問題があります。
それに対してフローマッチングの場合には、強制的にそのデータを狙ったスケジュール、例えば100ステップ後に完全に壊して生成の時のスタートの分布に変えることができます。
なので、機械学習の言葉で言うと、事後分布と事前分布のギャップがないようなモデルになっているし、そこが最近の理論解析とかでも結構クリティカルだねっていうような論文が出てたりします。
画像だとこのギャップがあってもそんなに目立たなかったんですけど、動画だとそこがクリティカルなようで、いろんな人がそこを解決する工夫をしてたんですけど、フローマッチングはそれを解決している。
◆ 動画生成の具体的な方法
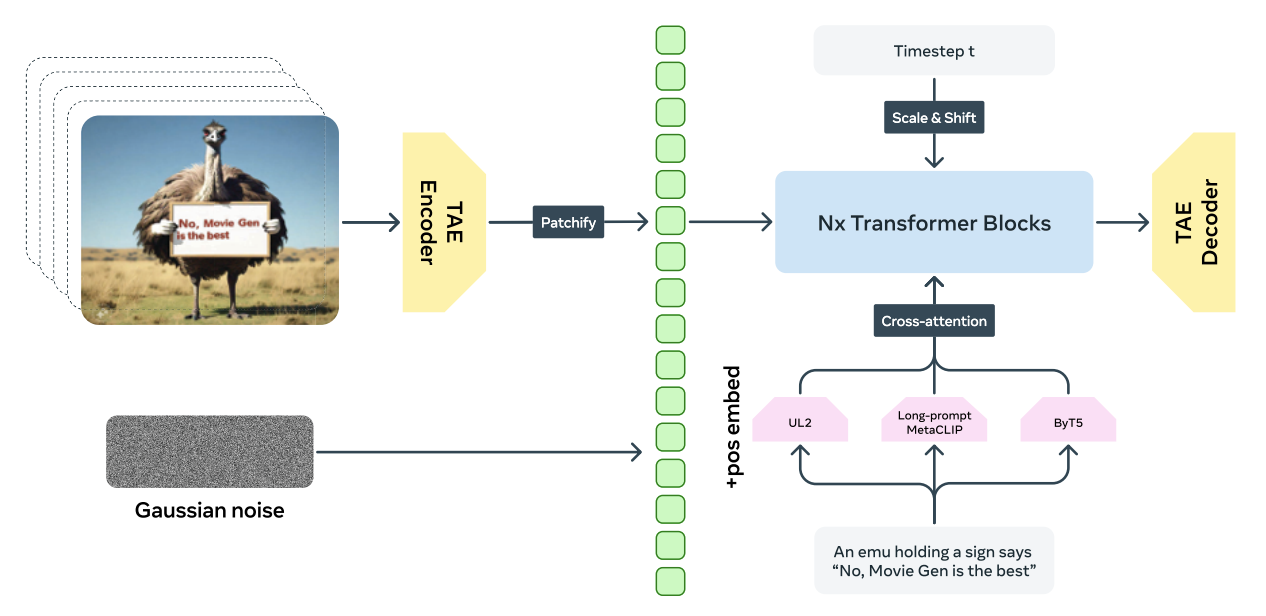
では具体的にどういうふうに動画を生成するかっていうと、OpenAIのSoraや他のアプローチと同じで、動画があったらそのフレームをパッチに区切って、そのパッチごとにそれをトークンに変換して、拡散モデルの言い方で言うとノイズを徐々に加えていって、完全なノイズにしていきます。そしてその過程を逆向きに辿れるような予測をできるモデルを作ります。
次に、ムービージェンがやった違いっていうのは、このアーキテクチャが今まではいろんな人がいろんな工夫して拡散モデル専用のユーネットだとか、最近でも拡散モデル向けのトランスフォーマーとか使ってたんですけど、今回はLLaMAと全く同じアーキテクチャを使っています。
ちょっとハイパーパラメータ変えますが、あのLLMで使っていたLLaMAのアーキテクチャをほぼそのままそのまま使ってやると、利点としてはいろいろあると思うんですけど、一つはLLaMA向けに分散学習のフレームワークも出来上がっているので、それをそのまま使えるっていうエンジニアリング的な利点が大きい。
まあこれが多分一番大きいと思うんですけど、あとはLLaMAのがいろんな研究者がこういうハイパーパラメータいいよねとか、そういう研究が進んでいるので、その辺が使えているのが大きいんだろうなと思います。
◆ LLMの学習との違い
一方で、普通のLLMの学習と大きく違うのが、LLMの学習をする場合は、コンテキストって呼ばれる「どれくらい前の文章トークンを見て次の単語を予測するのか」っていうのがだいたい4K(4000トークン)が標準なんですけれども、動画だとたくさんのフレームがあって、そのフレームがそれぞれたくさんのトークンになります。
動画ってすごく複雑で、数10フレーム前のある場所にあったものが影響を与えてたりするので、ずっと前のトークンも見ないといけないというのがあります。見なきゃいけないコンテキストとしては、73Kトークンにもなります。
LLMの20倍程度です。普通のLLMの場合は、こういうロングコンテキストの学習っていうのは一番最後の時だけちょこっとやればいいんですけども、動画の場合は73Kだし、もっとチャレンジングな動画生成をやる場合にはこれが増えていくと思います。
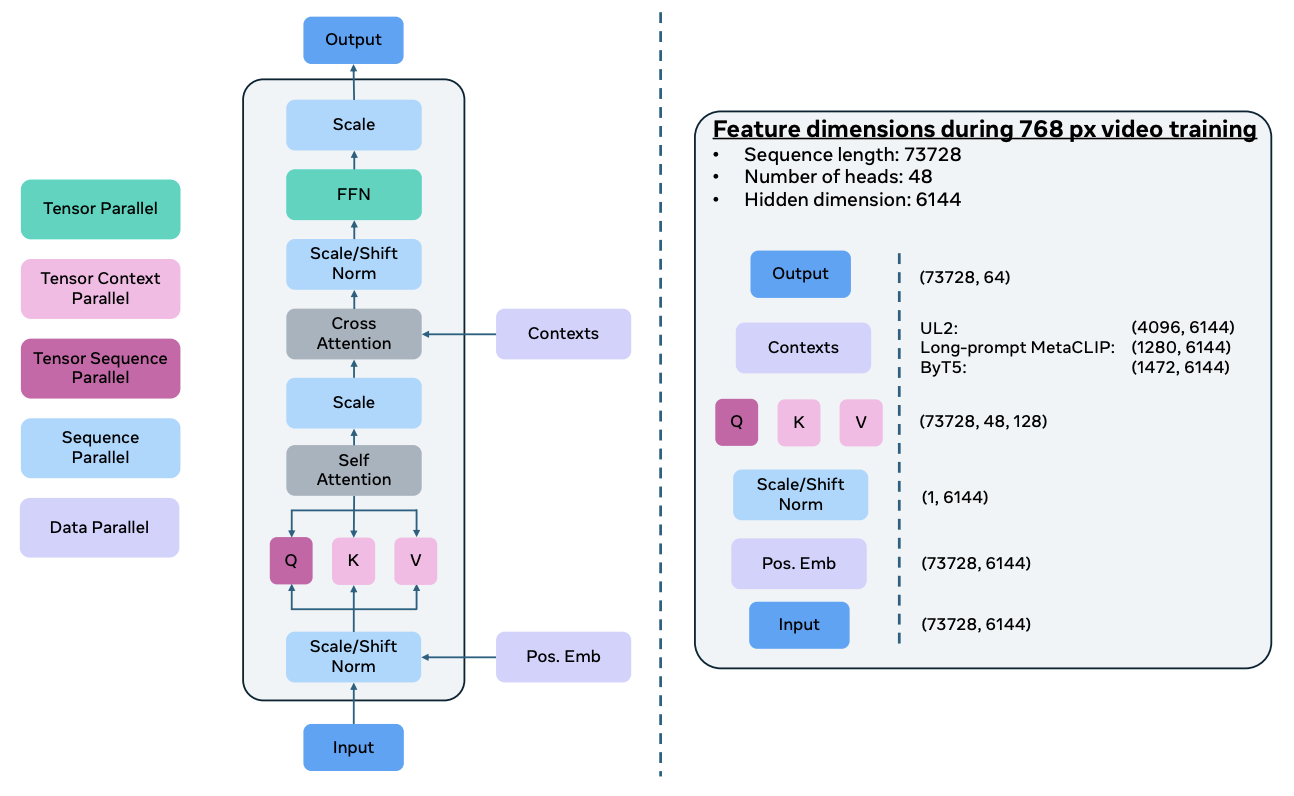
あとは、これ非常に単純な仕組みでできてるって言われてますが、この図の色分けしてるのが全部違う仕組みの並列化の手法を使って、6000台のGPUで分散学習できるようにしています。
「Tensor Parallel」「Tensor Context Parallel」これはコンテキスト長いので、コンテキスト方向の並列、あと「Tensor Sequence Parallel」「Sequence Parallel」「Data Parallel」これらを組み合わせてやっています。
計算の実行効率は私が見た限りは書いてなかったと思うんですけれど、こういうのを頑張らないとちゃんと学習できない。
これで6000台のGPUを使って、学習データが数10億枚の画像、数億の動画(各動画は4秒から2分)を30Bのモデルで学習するとこういうことができます。
◆ ファインチューニングの利点
さっき色んな編集のモデルっていう話ありましたけども、あれらのモデルっていうのは基本の動画予測のモデルを作った後に、ちょっとしたファインチューニングだけで実現しています。
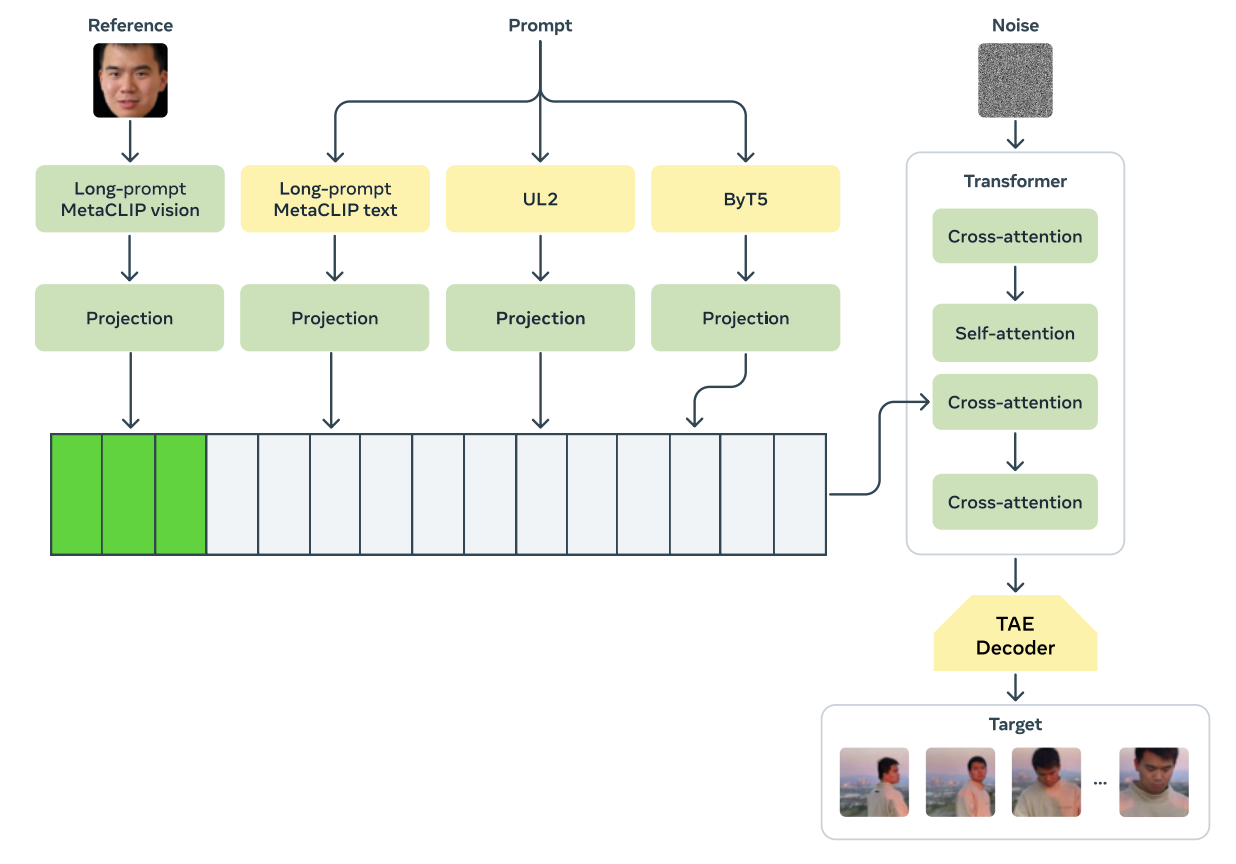
LLMがちょっとのファインチューニングでいろんなタスクが出来ているのと同じように、例えばこのビデオパーソナライゼーション(個人写真から動画生成)の場合も実現できています。
いくつかの人の顔写真からこの人の動画っていうようなタスクを全部トランスフォーマーに載せて、クロスアテンションでチューニングに乗っけて、「こういう写真を見せた時はその人の顔を使った動画を生成してね」っていうふうにファインチューニングさせてあげるだけで、たくさんの学習データを必要とせずに学習することができています。
なので、動画の方でもこういう基盤モデルとして、まず動画の生成モデルがあり、プロンプトってほどじゃないけどファインチューニングで比較的少量の学習データで色んなタスクができているというふうに思います。
こういうカタチでメタは動画生成を出していて、手法も公開されているので、みんなこれくらいはこれからできるようになっていくと思います。

