Vol.16 生成AIはいかに安くなったか
LLMを取り巻く環境で今回はどの程度生成AIを使うためのコストが安くなったのかについて話したいと思います。
◆ 推論コストは1年間で1/400になった
ちょうど1年前はどういう状況だったかっていうと、ChatGPTが出てからちょうど1年後でした。この頃はまだまだモデルが大きくなっていくのかという観測もみられていましたし、Mixture of Expertなど新しい技術も登場していました。
LLMの進化を支えているのは、こうしたスケーリング則は以前として成り立っているんですが、今はそれよりも学習データの質の改良に基づいて同じモデルサイズであっても性能が上がり続けるとともに、小さなモデルであっても性能がでるようになってきています。

この同じ性能あたりの推論コストが劇的に下がり続けているというのに注目してみましょう。
例えば、OpenAIがGPT-4 Turboというのを2023年8月ぐらいに出しました。このときにも既にGPT-4と比べて半額ということで話題になっていましたが、11月ぐらいのときの値段が、入力で1メガトークンあたり30ドルかかっていました。
それが現在ではベンチマーク上では同じぐらいの性能かほぼ超えているようなGPT-4o Miniというのが、1メガトークンあたり0.075ドルでできていて、価格でみれば1年間で400分の1になっています。
わかりやすいようにこれはOpenAIの例なんですけど、他企業とかOSS、またPFNが開発しているモデルに関しても同じように同じ性能あたりに必要な推論コストが1年でこれだけ下がっています。
理由としては、実際にLLMを本格活用しようという需要が出てきて、結局本格活用するとなると、推論コストが問題だよねということで、それを小さくしていくというプレシャーが非常に大きくかかっています。現在の推論コストの大部分は計算コストであり、計算コストはモデルサイズに大体比例しますから、小さいモデルを使おうというプレッシャーがかかっています。
モデルサイズというのが、おそらく推定だと最初に登場したGPT-4自体は1.8Tぐらいで、そのあたりはモデルサイズは公開されていないのですが2023年最初ぐらいは3Tぐらいまで増えたのではないかなとは思いますが、現在のモデルの主流はおそらく数十から数百ではないかなと思います。モデルサイズだけでもコストは20分の1ぐらいになりました。
あとは推論時のコストを実際に大きく占めているのは、KVキャッシュと呼ばれる「過去に処理した結果」を、毎回1トークン出力するごとに全部読み出さなきゃいけないというところが非常にボトルネックになっているんですけれども、そこも層をマージして圧縮したり、KVキャッシュ自体を圧縮したりいろんな減らす技術が出ていて、それが10分の1ぐらいです。
他にも半導体自身もコストあたりのパフォーマンス(特にメモリ帯域)は改善されているのでこれらをあわせて400分の1になります。
この1年でこれだけ下がったわけですが、未だにコストを下げるプレッシャーはかかっているので、今後しばらくは同じ性能だったら毎年数分の1から数十分の1になるというのは続くのかなと思います(一方、最高性能に関しては同じか高くなるとかはありえる)。
◆ 小さなモデルでも高性能:学習データ品質の改善
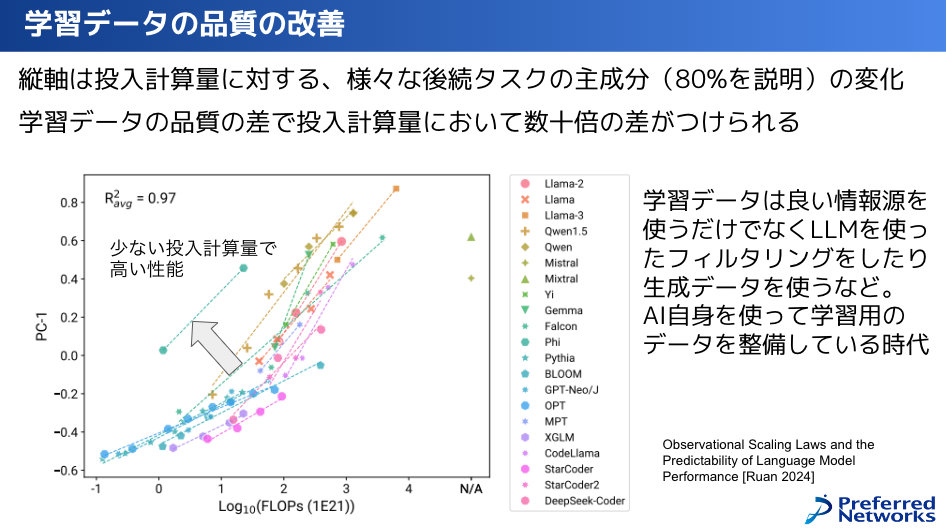
この変化を支えている重要な変化で、スケーリング則じゃないような変化について説明すると、何が起きてきているかというと、学習データの品質の改善の部分になります。
これはよく私が引用する論文なんですけども、いろんなLLMを比較して、それらのLLMが「どれぐらいの投入計算量の時にどれぐらいのスコアを達成できたか」というものです。
いろんなベンチマークスコアがあるんですけれども、そのベンチマークスコアというのをPCA(主成分分析)すると、大体80%ぐらい相関して、あるやつが高ければ他のやつも高い。
80%ぐらい説明できる一番主成分のPC-1(大体これがLLMの性能)の時に、そのスコアは同じ投入計算量だけれども、結構差があるというのが分かっています。
第1世代、2022年ぐらいまで登場していたようなモデルというのは、グラフ下側に寝そべっているような群です。これ、2023年ぐらいからだんだん上がってきて、傾きが上がっているということは、投入計算量あたりで性能が上がりやすくなっているということです。
さらにこれがどんどん左上に行って、より少ないデータ量で高いスコアが出ています。これを比較しますと、同じスコアを達成するのに、横軸が10倍のスケールなので、同じスコアを達成するのにデータの質と呼んでいる部分で数十倍ぐらいの投入計算量の差が生じているとなっています。
この学習データの質と言っている部分ですが、まだまだ発掘されていない良い情報源というのがありますので、それを使っているだけではなくて、まさにLLM自身を使ってデータをきれいにしてフィルタリングしたり、もしくは生成データを使うというようなことが行われています。
我々自身も今、せっせとデータをきれいにするのに、ものすごい労力をかけていて、質を上げて、投入計算量が少なくてもちゃんと良いものができるようにしています。
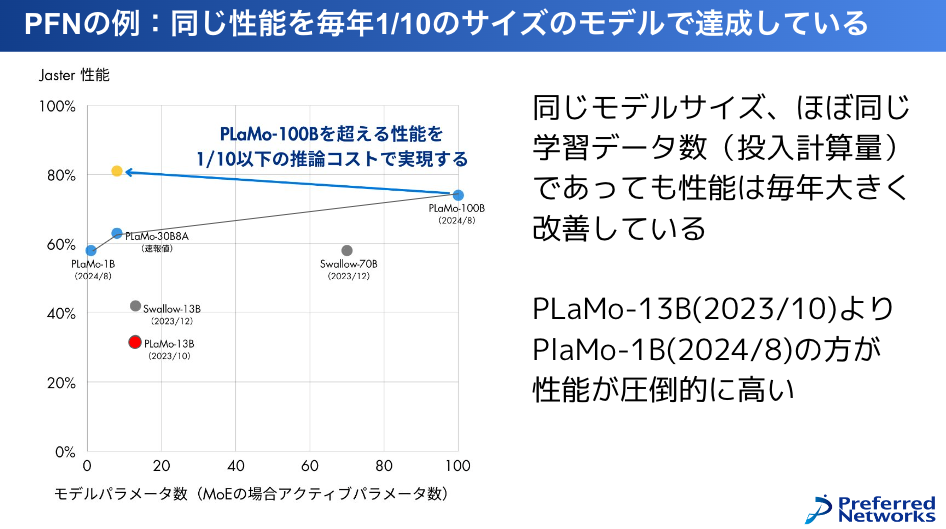
PLaMoにおいても、PLaMo-13Bは1年前の2023年10月に作ったものですが、その時に作ったモデルに比べて、その次の世代のPLaMo-100Bだとか、もっと小さいPLaMo-1Bとか、PLaMo-13Bに性能が勝っているんですけども、これはデータの質が良いからという風に説明できます。
今さらにこれを超える性能を、グラフの黄色いところを目指してやっています。

