Vol.18 推論スケーリング則と専門領域での性能向上
◆ 推論スケーリング則への注目
大きな変化として、2020年に学習時のスケーリング則っていうのが見つかってから、よーいドンで世界中で学習時の投入計算量が増えてたんですが、もう一つ、推論スケーリング則っていうのが認知されはじめて、今年に入ってすごく注目されています。
全部の問題に当てはまるわけではないんですけれども、特に数学とかプログラミングとか高度な科学技術の質問などにおいては、推論時に投入する計算量を増やすことで、性能が予測可能な形で改善できることが分かってきています。

これは例えばOpenAI-o1ですが、横軸が「推論時に利用する計算量(対数スケール)」、縦軸が回答の正答率(確か数学オリンピックの予選問題、すごく難しい問題の回答率)で、推論時に計算量をかければかけるほど正答率が上がっていくというのが観測できています。
これはいろんな工夫がされていて、まだこうだってはっきり言えないんですけれども、簡単に言ってしまえば、例えば回答する際に複数の候補回答、数学の解き方もいろんなアプローチがあるので、1通りじゃなくて10通り、100通り、1万通りを生成した上で、検証モデルが良い候補回答を選択をするっていうことができれば、いずれかがちゃんと答えにたどり着いているということで、計算を増やせば増やすほど性能が上げられます。
ここで考え方として、今までは学習時に性能を上げるためにスケールしてた考え方から、例えば今の一番大きいモデル作るのに100億円かかってたとして、これを1000億円にするのってすごい大変なわけですけれども、推論時のコストが前回話したように、1トークンあたりの生成コストがめちゃくちゃ安いわけなんで、それを100万倍することは結構簡単、まだ全然余裕があるわけなんですね。
なので、解きたい問題が難しい問題だったら、推論スケールの方で計算量を上げて、性能を上げるのがよいのでは考え方が増えています。
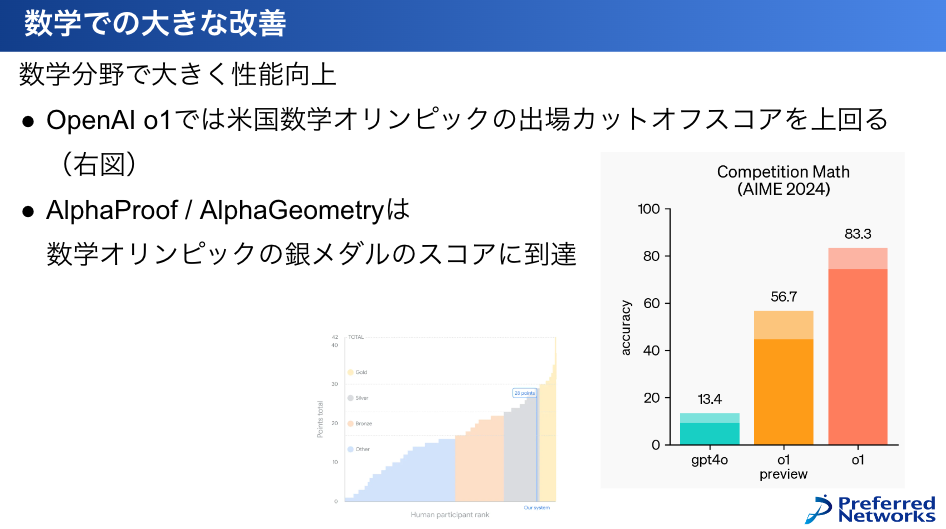
特に数学の性能が今年は目覚ましく上がっているのが印象的で、例えばOpenAI-o1が、米国数学オリンピックの問題の出場カットオフスコアを超えた性能を出すことができています。
今年はじめのGPT-4oで13.4%とか全く解けず、他のモデルでもほとんど解けないので、それが83%まで解けているっていうのはすごいことです。
あとこれは、ちょっとまた違うアプローチなんですけれども、ディープマインドがやっているAlphaProof/AlphaGeometryは、これはもうひたすら問題を人工的に生成してたくさん解かせて、補助線をどこに引くかなどのヒューリスティックを学ばせて問題を解くっていうアプローチで、こっちは数学オリンピックの銀メダルのスコアまで到達しています。
これはまた推論スケーリング則とは違う話ですが、数学など、今までAIが苦手としていた問題が解けるようになってきたということです。
◆ 専門領域での改善
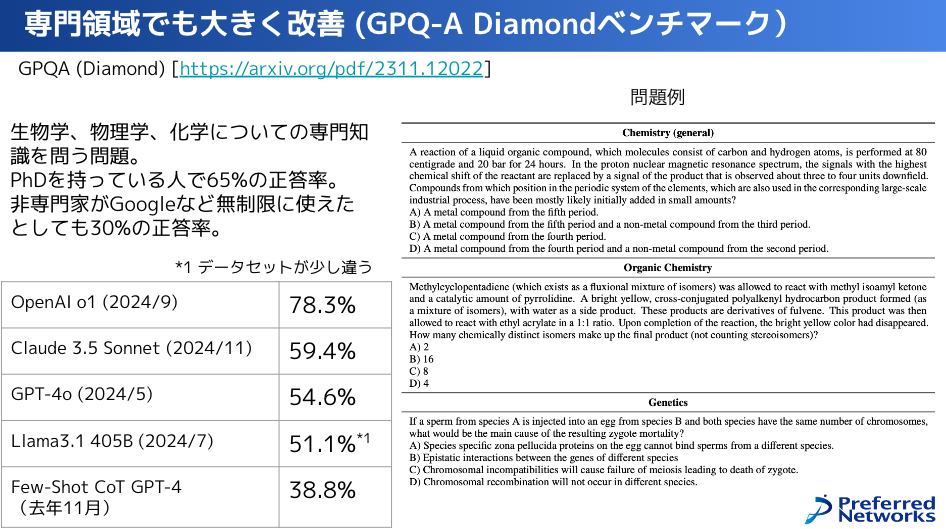
他の性能の点で言うと、GPQAと呼ばれるベンチマークで見た場合を紹介します。
よくLLMの評価で使われるMMLUというベンチマークがあって、これに対策ができているLLMについてはもう8割9割ぐらいの正答率になってしまい差がなくなっています。
これに対し、GPQAと呼ばれる「これは解くのが難しいでしょう」という問題が、ちょうど去年の2023年11月に出まして、これは生物学、物理学、化学の専門知識を問うような問題で、博士を持っている、もしくは博士課程の人が解くと65%ぐらいの正答率。で、非専門家がGoogleなどを無制限に使えたときの正答率が30%ぐらいで、MMLUよりも難しいとされている問題です。
このGPQAの正答率は登場したときには去年の11月は38.8%だったんですけども、この1年で80%ぐらいまで上がってきているということで、大体ベンチマークが年末に新しく出て、その次の年にはそれが大体解けるようになっているという感じで伸びています。

このようにベンチマーク上はすごい性能がでていますが、これを本当に研究で使えますかっていう話の観点で言うと、さっき数学の性能がめちゃくちゃ上がっている、高校数学オリンピックも超えるぐらいの性能が出ているよっていう話なんですけれども、じゃあ本当の数学のプロフェッショナルの意見はどうかっていうと。
テレンスタオさんっていう、数学のめちゃくちゃ超天才中の天才がいるんですが、この方は結構昔からLLMを初期から積極的にバリバリ試して使いこなしている、最近では証明系でも使いこなしているんですけども、最近言ってたのが、OpenAI-o1については、最先端の数学研究に使用するのはまだ難しいというふうに言っています。
複雑な分析とか、このテレンスタオさんが数学の研究で使うような場面だと、多くのヒントや補助を使える場面もあるが、依然として多くの誤りがあって、現時点では「完全に無能ではない大学院生に助言しているような感覚」に近いと。
テレンスタオさんが言う無能が相当レベル高い可能性はあるんですけども、そういう感覚なのでまだ使えないという話があります。
一方で、以前のモデルが「完全に無能な大学院生」に近いレベルだったのに対して、OpenAI-o1は明らかに改善していて、あと1、2回能力向上があれば「有用な大学院生」レベルに達して研究レベルのタスクでも大いに役立つようになると予想しています。

