Vol.20 生成AI向けプロセッサーMN-Core L1000
今日は11月中旬に発表したMN-Core L1000についての紹介です。
◆ PFNのチップ開発とポジショニング
今PFNのチップ開発では、学習向けに非常に高い計算力をもったチップ、今回発表した推論向けのチップ「MN-Core L1000」の2ラインの開発が進んでいます。
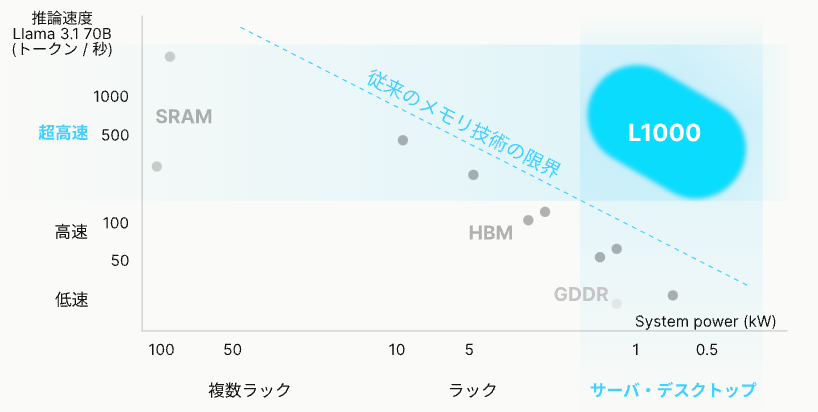
このL1000がどういうポジショニングを目指していくかというと、ここに表で書いてある位置です。この表は横軸がLLMを推論させようと思った時、必要な計算資源の最小単位はどの程度か、縦軸はLlama3.1 70Bの1秒あたりの生成トークンとなります。
LLMを推論させようと思うと、例えばLlama 3.1 70Bや、PLaMo Primeとかを想定した場合、データセンターで使われるような複数ラックの場合と、個人だとか部署毎とかもしくは企業でもオンプレミスで持つ場合のようなサーバ・デスクトップ向けのものがあります。
横軸がシステムパワーで、1kWっていうのが今のNVIDIA H100とかB200ってシステム全体で1kWぐらいなので1枚で済むくらいで、それより左は複数枚のチップを繋げたものになります。
この場合、左上にあるのがSRAMに全部データを載せたようなものです。最近リリースされているようなCerebrasやGroqなどの新興企業といったところが、SRAMにモデルパラメーターとかを載せています。
◆ メモリ技術の進化
ただそれぞれで強み弱みがあって、例えば基本的にメモリはDRAMっていう比較的安価で大量の記憶ができるものがよく使われています。
この場合、DRAMとチップの間をつなげる部分がすごくボトルネックになっていて、そこの部分をGDDRっていう方法でつないでるタイプが今まであったところに、HBMっていうタイプのメモリが出てきた。
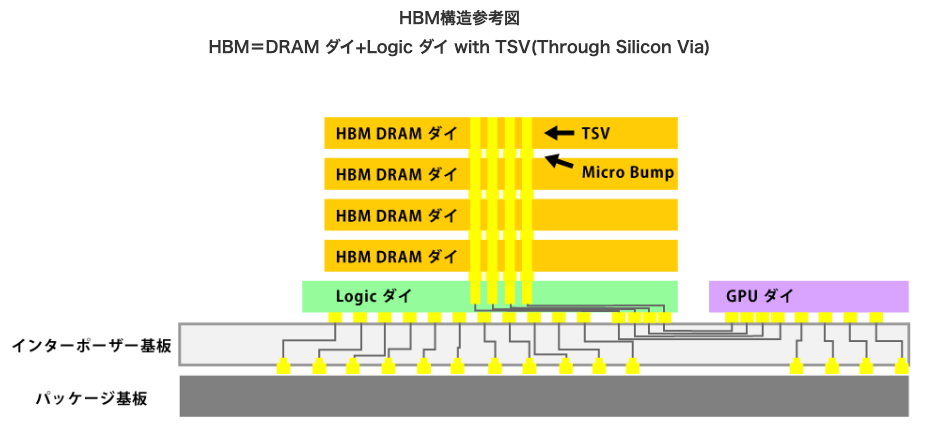
参考:https://www.inrevium.com/pickup/hbm/
HBMは、GPUがあって隣にメモリDRAMがあって、その下がインターポーザーっていう基板があって、GPUとメモリのところにピンがあって、そのピンがインターポーザーとつながっていて、ここでものすごいピン数を稼いで、これまでにないようなメモリ帯域を実現しています。
ちなみにこれは非常に作るのが難しい技術で、何が難しいかっていうと、GPUとDRAMをそれぞれ作って持ってきて、インターポーザー基板にめちゃくちゃ正確に載せるというのをクリーンルームでやらなきゃいけないので、こういうのができる会社は少ないです。
一方でSRAMっていうのは、チップ内に入っているメモリなんですけど容量がすごく小さいんですね。
なのでこのSRAM上にモデルのパラメータを乗っけようと思うと、何十枚何百枚のチップを組み合わせて、その上で全体で一つのモデルを使う、としないといけない問題があります。
ただチップ内にメモリがあるので、スピード自体はめちゃくちゃ速くできます。
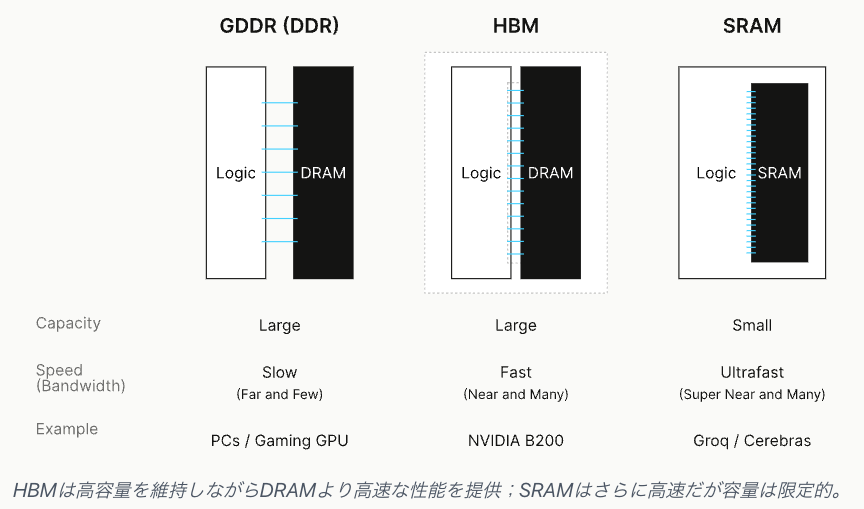
こういう流れで、もともとあったDRAMに、HBMで繋ぐ技術が登場してきていて、新興のチップメーカーが提供しているSRAMベースのアプローチが出てきています。従来のDRAMは容量が大きいけれどもスピードが遅い。
◆ MN-Core L1000の性能と今後の展望
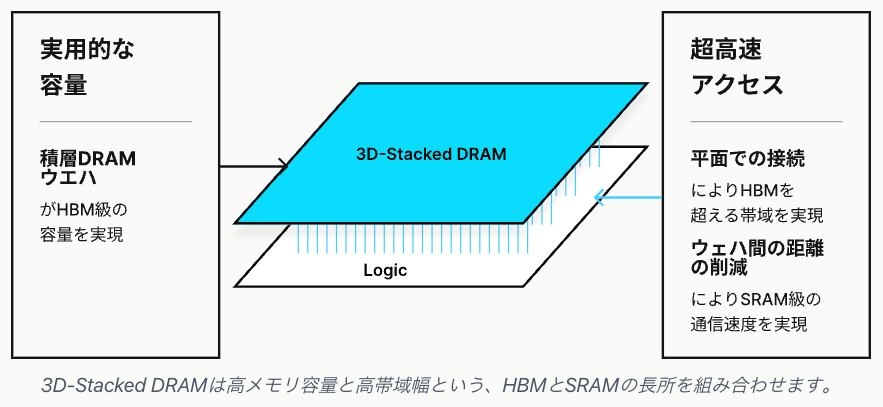
これらに対して今回我々が作るMN-Core L1000っていうのは、SRAMの速度とHBMの容量を両方実現するものになります。
これを実現できる理由は、まずDRAMは容量が非常に大容量でできて、これをチップの上に積層するわけですね。
さっきのHBMはチップの横に置いてたので、何かデータ欲しいなと思ったらインターポーザーの中を通って処理するんですけれども、(MN-Core L100の場合)3D-Stacked DRAMと純粋に距離が短いので速いし、電力量も抑えられるしってところが実現される、非常に単純な話です。
なので、これを使えばいいんじゃないかっていうことはみんな思ってるんですけれど、じゃあ何が難しかったかっていうと、積層させるのでチップの上に違うチップを乗っけて、しかもそれが密着するので、熱の制御が非常に難しいというのが問題になります。
DRAMは非常に温度に敏感で、くっつけた場合熱がこもっちゃう。しかも下のチップ自身がもうめちゃくちゃ発熱してるところで、そこに密着させるので、ちゃんと動くかっていうのが難しいわけです。
ここが我々MN-Coreを使って作ってるところで競争力があると考えています。
まず、MN-Coreが高いエネルギー効率があるっていうのは皆さんご存知の通りで、あとは完全にデータがどう流れるのかっていうのを制御できると。
それこそ今まではハードウェア側がデータがどこからどこに移るかっていうのを非常に複雑にコントロールしてたのを、MN-Coreの場合は全部それをソフトウェア側でデータがどこからどこへ移動するっていうのを制御するようになっています。
今まではこのソフトウェア側で制御するってのがプログラムする上では大変だっていう欠点でもあったんですが、データをどこに置いたらいいかだとか、熱の問題でどこをたくさん計算させなきゃいけないかとか、そういったことを制御したいっていう場合には、全部制御できるっていうことがアドバンテージになります。
熱の制御がしやすいという利点があるというところから、3D-Stacked DRAMを採用して、これまでにないようなメモリ帯域を実現したものを使って作られるのがこのMN-Core L1000になります。これによって例えば単一ノードで128Kコンテキスト長の70Bモデル推論を、約500トークン/秒の速度で実現できますよっていうことを考えています。

