Vol.24 科学とAIの接点
今日は、人工知能学セミナーの前日に開催される「AIフェス」で、私が一講演者として話した内容についてです。AIを使った研究成果がノーベル物理学賞とノーベル化学賞という2つの賞を取ったことで、非常に重要な年となったことを記念したイベントです。

この左から2番目の赤い本がちょうど先日発刊されました。この話の中では今回のノーベル賞を取ったホップフィールド先生とヒントン先生、あとはAlphaFold側のディープマインドのデミス・ハサビスさんとジャンパーさんの話をカバーしています。この本を読めば、全ての内容がカバーされているというものです。
雑談として、昨年ノーベル賞が授与された背景や裏話もできればと思っています。
◆ホップフィールド先生とイジング模型
今回ノーベル物理学賞を受賞したホップフィールド先生というのは、元々は物理学者でした。
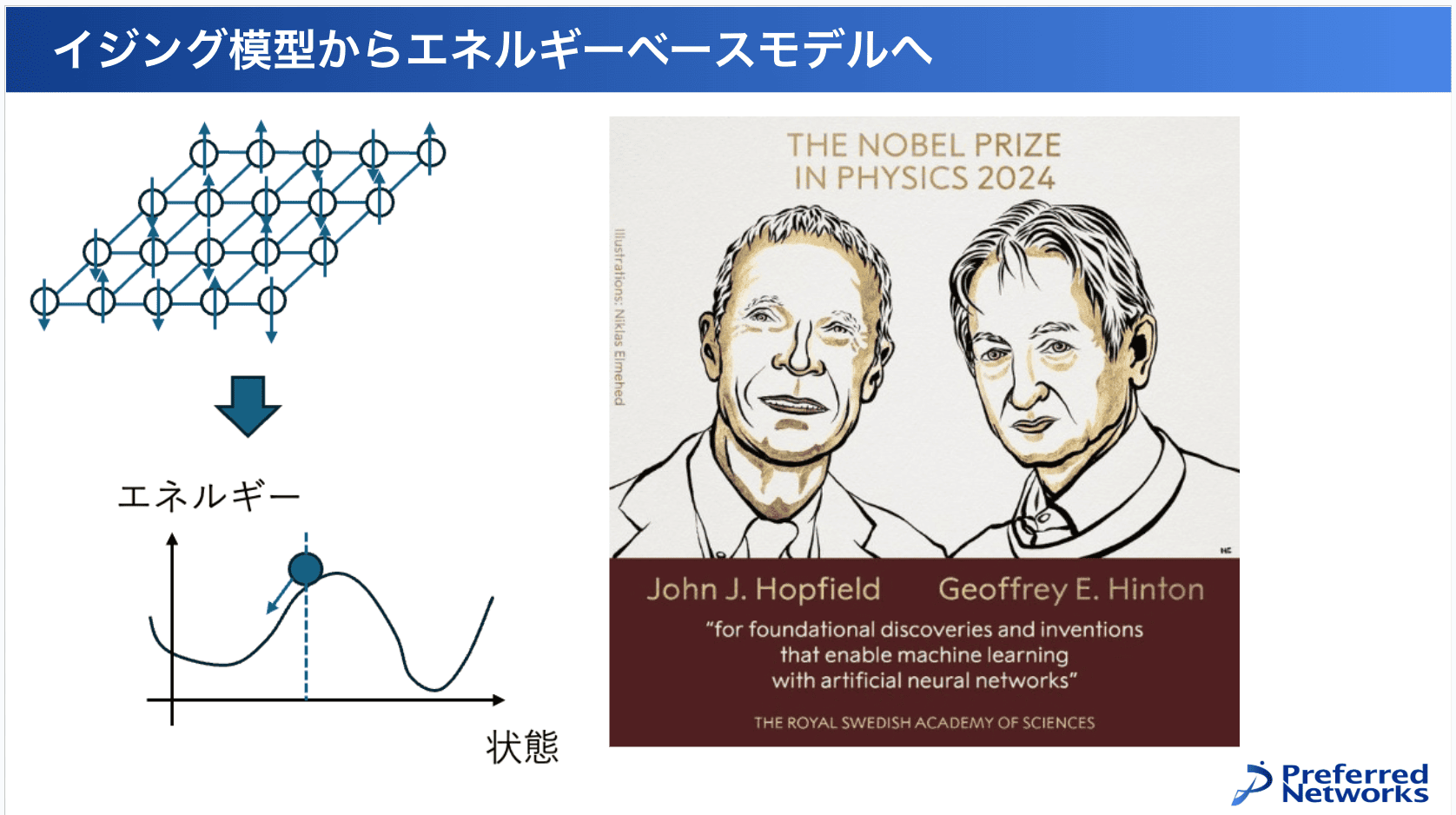
物理の分野で、イジング模型と呼ばれる分野が1820年ぐらいからあって、イジングさんという学生が磁性体や原子が一斉に向きを揃えて、特定の性質を持つ現象を調べるために作った非常に単純化されたモデルです。この模型を使って、様々な物質の特性を調べることができることが分かっていました。
このイジング模型はAIとは全く関係ない分野ですが、非常に研究が進んでいて、特に1940年代にオンサーガさんという物理の天才が二次元の場合の厳密解を解明して、非常に流行りました。
この粒子はそれぞれ上向き下向きになるんですけれども、つながっている場所で両方が同じ向きを向いたらエネルギーが低くなります。
そういう重みがついているのと、あとはそれぞれの粒子ごとに自分は上向きか下向きか、どっちの方がエネルギーが低いかっていう制約がついていて、その両方のトレードオフの中で上か下かを選んでいくと、全体の状態ごとにエネルギーが決まります。
ここで言ってるエネルギーって自由エネルギーの意味で、時間が経てば経つほど低い方向に自発的に変化します。この自由エネルギーが低くなるようにという現象は、高さがあって、勝手にボールを置いたら低い方向に転がるようなものだと思ってもらえばいいです。
このように何か状態があり、状態に応じてエネルギーが定義されており、時間が経つと勝手にエネルギーが低いような状態に収まるというようなことを調べるというのが進んでいました。
◆ホップフィールドモデルと生成AIの関連
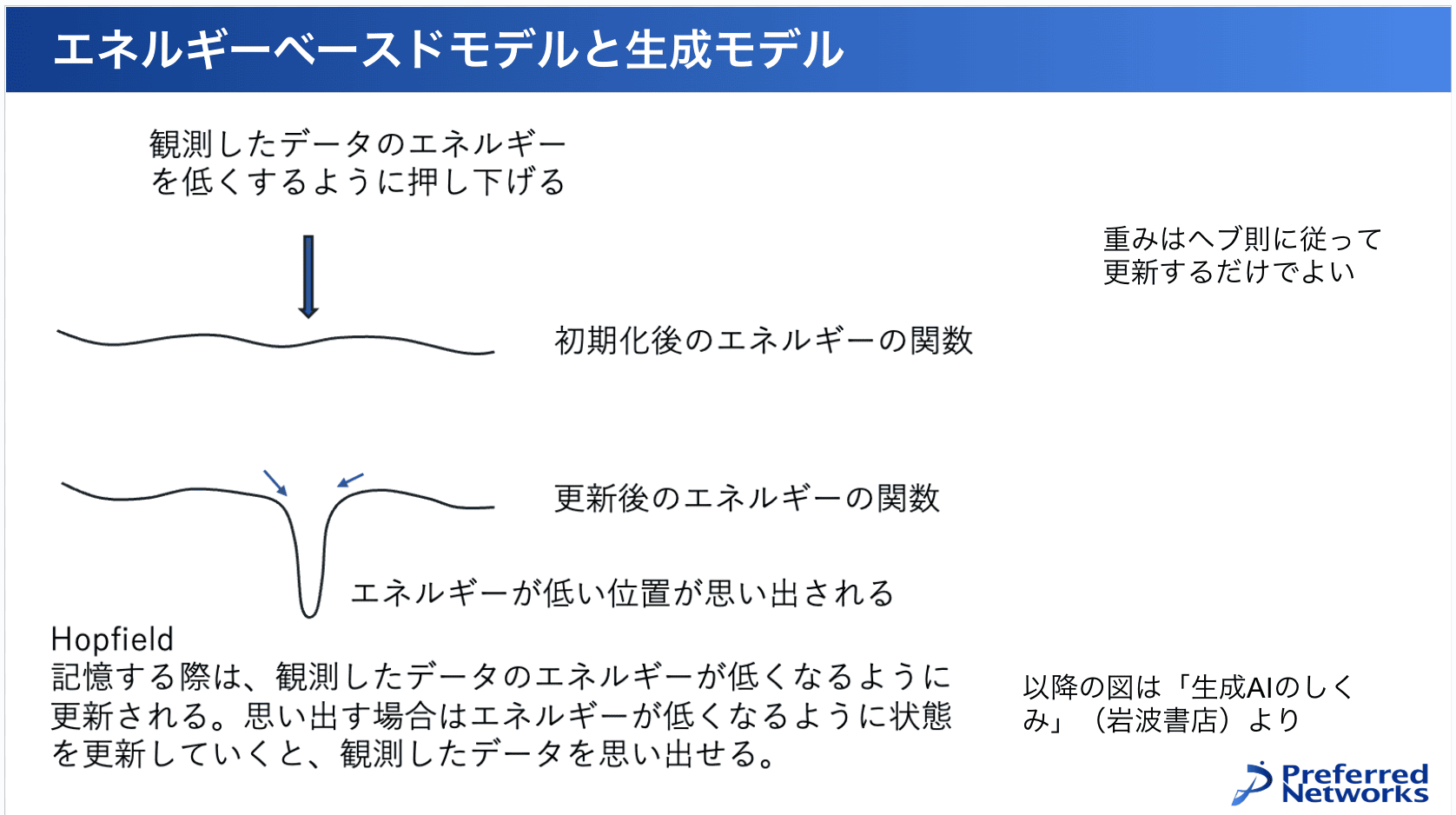
これが生成AIにつながる話として、ホップフィールド先生らが何をしたかというと、エネルギーが低い状態と、記憶したい対象を結びつけるようにしました。
生成で何が重要かっていうと、観測したデータを記憶することができれば、後でそれを思い出して生成ができるということです。例えば、うさぎとか犬とかをたくさん見たら、それをエネルギーが低い状態として記憶しておけば後で犬ってなんだっけと思い出せるということです。記憶する問題を、観測したデータのエネルギーを低くするようにすればいいということになります。
元々のエネルギーは特にどこが低いとか高いとかないんですけども、観測したデータの状態が低くなるようにイジング模型の重みを更新するという方法をホップフィールド先生らが提案しました。
エネルギーが低い状態を作るには、ヘブ則と呼ばれる方法を使って重みを調整します。ヘブ則とは、ニューロンをつなぐシナプスの端点の両方が発火した時だけそのシナプスの重みを強くするという、人間の脳の神経回路で観察されたような現象です。それと同じ方法を使って更新するとエネルギーを低くすることができます。
ホップフィールドモデルは、ヘブ則を使ってイジング模型の重みを更新して記憶を作るというもので、物理とも脳神経ともつながっているため大ブームとなりました。
ホップフィールド先生がこの論文を出したのが1980年くらいなんですが、1973年に日本の中野馨先生、1974年に甘利先生が同様の提案をしていました。なので、ホップフィールド先生がこのアイデアを最初に出したわけではないですが、それはみんな知っている話です。
ただホップフィールド先生が出した論文は、連想記憶に必要な部分の本質を抽出し、様々な分野との関連性を示したという意味では、論文がすごく読みやすく、その後の波及効果が非常に大きかった。
実際にそこからブームが巻き起こっているという意味では、研究は最初の発見ももちろん重要ですが、それだけじゃなくて波及効果をどれだけ出せたかという部分も重要になっていると私は思います。そういう面では、ホップフィールド先生やヒントン先生は非常に大きな成果を上げていると思います。
◆エネルギーベースドモデルとその応用
エネルギーベースドモデルは連想記憶に役に立つという話があります。その例として、エネルギーが低いところが記憶されていますよという話なんですけれども、この仕組みを使って結構難しい問題がいっぱい解けます。

例えば上のような画像(書籍から引用)があって、上半分は犬の画像にして、下半分はランダムに初期化したような砂嵐のようなものを作ります。これは、上半分は犬なのでエネルギーが低いけれども、下半分は別の動物で、上と下が調和が取れていないからエネルギーが高い状態にあるわけです。
上半分を固定した上で、下半分の状態をエネルギーの低い方向にどんどん変化させるだけで、上の画像と調和が取れているような下半分の画像が勝手に生成される。つまり上をトリガーにして、下の記憶を産み出すことができます。
例えば、下側が猫のような画像だと上と下の調和が取れていないので、エネルギーで言えば高い、これよりももっとエネルギーが低い方向があってそちらに行くという意味で、連想記憶というのが難しい仕組みを必要とせずに、単なるエネルギー関数とその中での自発的にエネルギーが下っていくように変化することで思い出すというのが実現される。
これは非常にシンプルな方法でできているのが強みになります。逆に下半分を犬にして上を砂嵐にしても、同じように簡単にできます。
◆ホップフィールドモデルの発展と現代のAIモデル
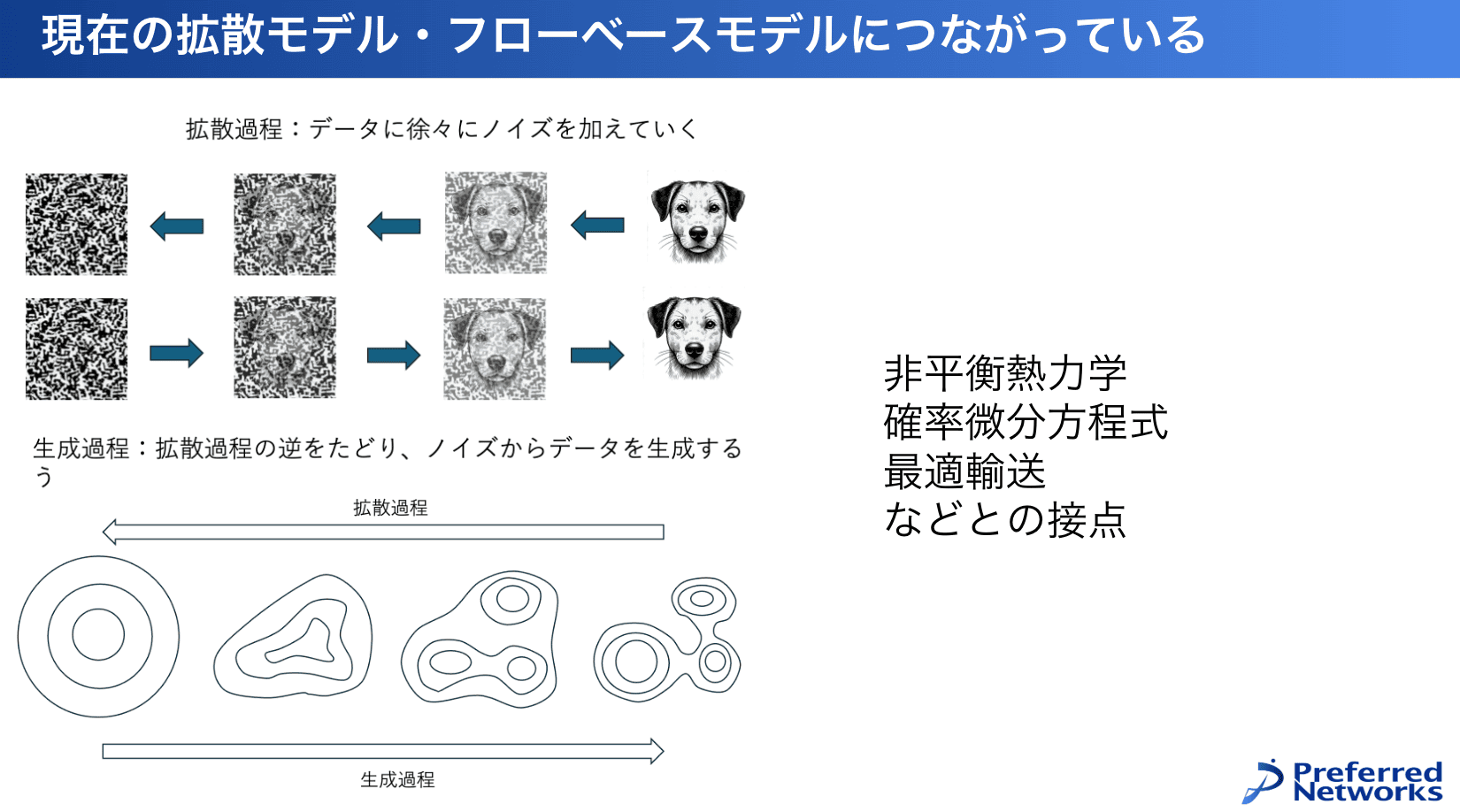
ホップフィールドモデルがそのまま使われているわけじゃないんですけども、これが発展していって、例えば今の画像生成や動画生成などで使われる拡散モデルとフローベースモデルにつながっています。
今の拡散モデルは、何か画像があった時にデータに徐々にノイズを加えていくことで完全なノイズになる。そして、各時刻でノイズを加えていった時に起きていた平均的な流れを再現して、この逆をたどっていくことでノイズからデータを生成するというところに対応します。
これは今、画像という観点で見た場合ですけれども、データの集合の分布で見ると、ありえそうなデータの集合の分布にノイズが加わっていくと崩れてガウシアンみたいになって、それが戻っていくとデータ分布になってデータが生成できるというものになっています。
なので、拡散モデルはエネルギーベースモデルの一種ということはできて、エネルギーに従ってデータはどんどん下がっているんですけれども、もともとあったエネルギーベースモデルのいろんな問題点を拡散モデルは改善しています。
例えばエネルギーベースモデルで下がっていけばいいという話だったのですが、途中で止まっちゃったり、もっと深いところがあるのに行けないという致命的な問題があります。こうした問題は拡散モデルでは時刻ごとにエネルギーを変えていくことで、こうした問題を解決しています。
あとは学習するときも、エネルギーベースモデルは綺麗な理論ですが、学習効率が悪かった。でも今の拡散モデルとかフローベースモデルはそれを効率的に学習できるような工夫が入っています。
1980年ぐらいの連想記憶の時にはせいぜい10個ぐらい覚えられるみたいなものだったのが、それがとんでもなくスケールして、生成できるものが増えました。
◆アルファフォールドとAIの科学分野への応用
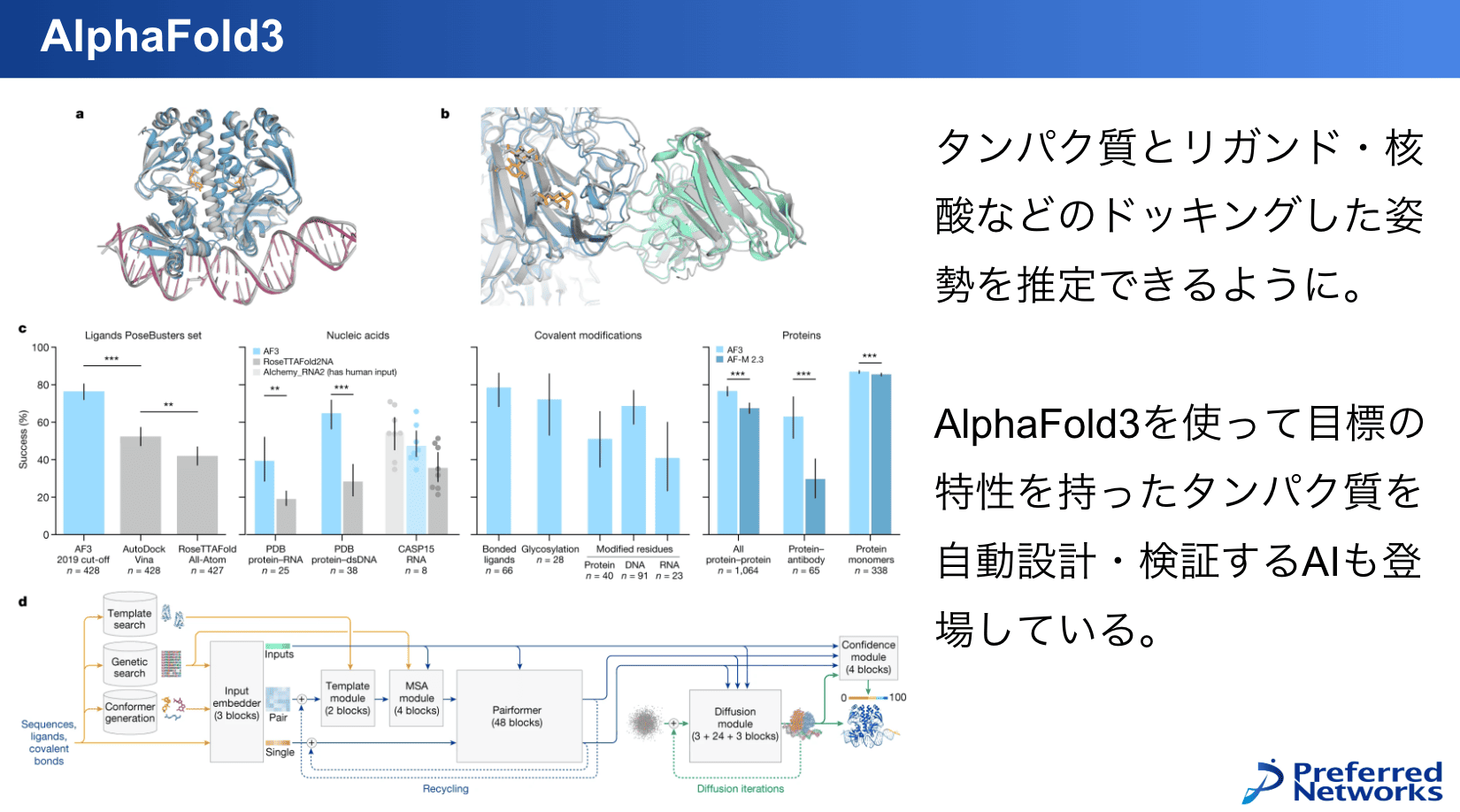
もう一つ、ノーベル化学賞を取った「AlphaFold」についても説明します。最新のAlphaFold3は拡散モデルベースで、構造が与えられたらその姿勢を生成するようになっています。
従来のようにタンパク質の構造を推定できるし、さらに核酸やリガンド(薬の候補)とドッキングした姿勢とかも推定できるようになっています。
AIが科学を進展させるという意味でいうと、今一番成功しているアプローチはシミュレーションの加速の部分です。AlphaFoldは実験データから学習して、普通に計算したらとても出せないようなタンパク質の折りたたみを、実験データを教師ありデータとして学習して推定しています。
こうした実験データではなく弊社が提供しているMatlantisのように第一原理計算(つまり実験データを使わず、量子化学計算の結果)を学習データとして利用しシミュレーションを高速化するアプローチは成功しています。
このように、AIがサイエンス分野においても重要になっていて、それを代表するものとして昨年度のノーベル物理/化学賞があったのかなと思います。

