Vol.25 DeepSeek-V3の技術とその影響
◆フロンティアモデルとオープンモデル
昨年末にDeepSeek-V3というのが発表されて、これがオープンモデルの中では一番性能が高いモデルになっています。フロンティアモデルなどに対して、ベンチマークとしても匹敵するような性能が出ていて注目されています。
実際これが発表された直後に、海外のGAFAMとかの株価が下落しまして、こういうモデルが、そういったリードしている会社じゃなくて、そうじゃない会社からも出てくるというところでインパクトがありました。
◆DeepSeekの技術的背景
このDeepSeekは昔から非常に技術的に尖っている有名な会社で、論文もいっぱい出していました。今回の話も突然出てきた話ではなくて、これまで作っていたDeepSeek-V2、2.5などの後継で最新版を出しました。
このモデルの一番大きい特徴としては学習コストが非常に安いというのがあります。このDeepSeekが使っているのがH800というGPUです。聞いたことが多分ないかと思うんですが、これは米中の輸出規制の影響で、NVIDIAが中国向けにGPUを輸出する際にメモリバンド幅を抑えたものをH800という名前で出荷しているものになります。なのでH100よりも性能は低いものになります。
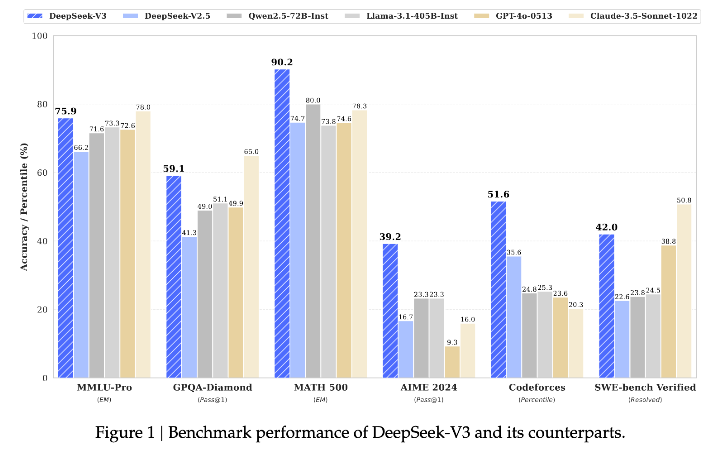
それを使ってだいたい2048GPUで58日の学習ぐらいでこれだけできています。比較するとLlama3-400Bがだいたい16,000GPUで3ヶ月ぐらいなので、純粋に投入した学習の計算コストからすると、10分の1から20分の1ぐらいの計算コストでこれだけの性能が出せているというのが、まず学習側のMoEのメリットです。
もう一つが推論時のメリットです。DeepSeek-V3は600B(6000億パラメータ)のモデルなので非常に大きいモデルなんですが、アクティブになるのは37B(370億パラメータ)のみです。
実質1トークンを生成するときには370億パラメータしか触れないので、あたかも370億パラメータのモデルと同じぐらいのメモリ転送量と計算力で使うことができるというような推論側も非常にエコノミックにできるというものになります。
実際どうかというのは、後で詳しく説明します。(実際そうではないという話をします。)ただ、これだけ非常に効率的に学習したり推論できるものができているというのは、(結構予想はされていたんですが、)ここまでやりきるということを今回示されたのが大きかったと思います。
◆MoEの歴史とDeepSeekMoE-V3の特徴
MoEってそもそも何かという話なんですが、MoEの歴史自体はめちゃくちゃ古くて、2018年ぐらいからいろんなモデルが出ています。最初のGPT-4もMoEではないかといわれています。
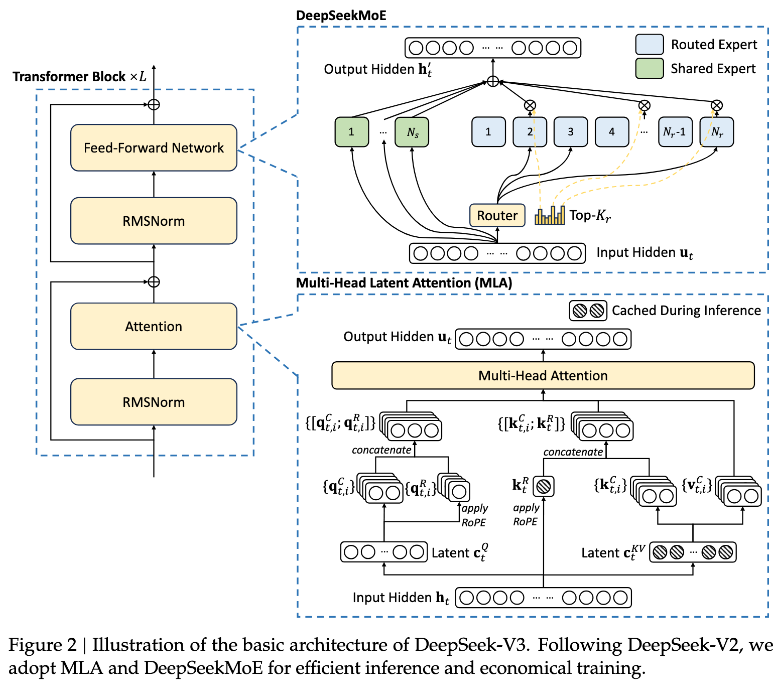
これは何かというと、トークンごとに何か処理するときに、そのトークンをモデル全体で処理するのではなくて、エキスパートがたくさんいて、どのエキスパートで処理するのかをルーターが決めて、一部のエキスパートのみ使って処理する。例えば、このトークンは1番と17番で処理しようと決めて処理する。
こうすることによってモデルを全部使わないので、本当にルーターが賢ければほんの一部のエキスパートしか使わなくても正しい結果を返してくれます。例えば、阪神の話をしているなと思ったら、阪神のエキスパートがいて、その阪神のエキスパートに処理を依頼すると、すごく阪神について詳しいので、処理してその結果を返してくれるというふうになります。
このDeepSeekMoE-V3の場合、まず通常のMoEとの違いで言うと、通常のMoEだとエキスパートの数が8や16なんですが、エキスパートの数が非常に多くて256個あります。ファイングレインドと言われますが、細かくたくさんいます。かつシェアドエキスパートというのがいて、常にオンの人がいる。
なので、毎回ランダムに選ばれるエキスパートとは別に、常に毎回選ばれる共通の知識を持っているようなエキスパートというのがいます。実験の中では1人だけ共有の人がいて、残り8人のエキスパートを256人の中から選ぶという形で動きます。
そうすると257分の9しか発動しないので、さっきの600Bだけども、40Bぐらいしかアクティブじゃないというのが達成されます。
◆学習と推論の課題と解決策
この方法は良さそうなんですけども、じゃあなんでみんなこっちの方向を選ばないかというと、学習も推論もとにかく大変ということがあります。
学習の何が大変かというと、まず安定しないんですね。ルーターが賢ければという話がありましたけれども、ルーターが毎回変なエキスパートを選んで、そのエキスパートがよくわからないと言って、うまく学習できずに終わるという形になります。
これって昔からあるハードアテンションと呼ばれる問題。選ばれなかったものに対しては全く試されないので、バックプロップで誤差も伝搬されずパラメータが更新されないという問題と同じような問題があって、不安定になりやすいというのが一つ。
もう一つが、1台くらいの中でやるんだったらまだいいんですが、実際にはさっきので言えば、2,048台のGPUで分散して動かして、各トークンごとにルーターでいろんなエキスパートにばらまくので、そこでも偏りが出たりします。
またエキスパートでも選ばれない人が出てきて、計算の偏りがものすごく発生をして、結果としてこの学習の実行効率が悪く、たくさん計算機があるものの、ほとんどの計算機が遊んじゃうというような問題が発生すると。
さらには今の計算機ってひたすらB/F比(メモリ転送量と計算量の比)との戦いで、計算ユニットにデータを送る速度の進化に対して計算力が上がるペースが早いために、1回データを送った後にものすごいたくさん計算をしないと、ちゃんとデータを送るペースと計算するペースが釣り合わなくて、計算機が遊んじゃうことになります。
MoEの場合だとその傾向をさらに悪くして、データはそんなに変わらずにスパースになるので、計算の方が減るというようなところでB/F比が悪化するというような問題があります。
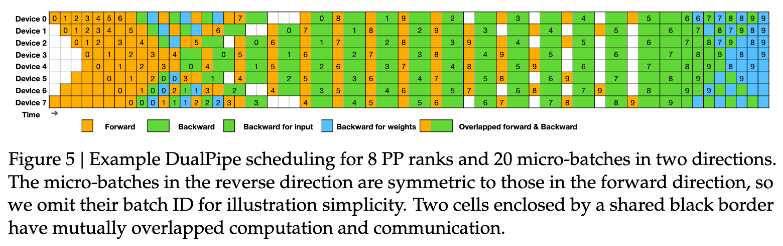
こうした問題を一個一個全部エンジニアリングをして解決しています。例えばデュアルパイプという方法で、いろんなデバイスがあったら、各デバイスごとでフォワードとバックワードをうまくオーバーラップさせて遊んでるやつがないようにするっていうのをやったりします。
あとはそのGPUには計算するのが24個(SM)ぐらい載ってますが、そのうちの6個ぐらいが通信だけに使われていて、送られてきたデータをノード内で他のどのGPUにばらまくかっていうところに使っています。そのカスタムカーネルとかは全部手で書いていると。
あとは「FP8 Training」をできる限りする。量子化すればするほど学習が不安定になるので基本的には難しいんですけども、例えば1×128とか128×128とか細かいブロックごとに量子化する。
そうするとその中では同じような指数部は共通して持てるので、BFのもっと細かい版のところを使ってやるとか。学習全体の実行効率は発表してはいないんですが、そういう細かい工夫をたくさんすることによって、だいたい手で計算したときには実行効率20%ぐらいっていうのを達成しています。これは分かる人だと、そんな出るんかいっていうぐらいの数字が出ている。
さっきの推論効率がいいっていう話で、理論上はそうなんですが、実際にこれを利用しようと思うとどれぐらいの計算機が必要かっていうと、論文に書かれていた推奨構成は最低で320GPUが必要になっています。
これだけ必要なのは非常にスパースなので、その分非常に大きいバッチになるんですけれど、それぞれ各1GPUがエキスパート担当みたいな感じになってばらまくと、結果として秒間60トークンとか、結構早く返ってくることができると。
これより小さい構成になるとスピードが出ないという問題があります。なので、かなり尖った方に思いっきり振っていますが、こういうことができるようになっています。
◆ハードウェアデザインへの提案
普通の論文で見ない面白い章として、ハードウェアデザインに対する提案の章があります。132SMのうち20を通信向けに使ってて無駄遣いしちゃったんで、コミュニケーションのハードウェアをつけてくださいというものです。
あとすごい細かいんですが、FP8でGEMMするときのAccumulation Precisionの話と、ひたすら量子化ですね。量子化するときの細かい要望っていうのが書いてあります。あと転置した行列をそのままGMMできるようにしてほしいといったことが書いてあったりします。

