Vol.26 DeepSeekショックの技術的背景
今日もこの件についていくつか取材依頼もあったのですが非常に注目度の高い話題です。過去何度か話をしましたが改めて説明します。
今回、DeepSeekショックと呼ばれることが起きまして、マーク・アンドリーセン氏という有名な投資家(Netscapeを開発した人)が今回の現象を「スプートニクショック」と言って大きな話題になりました。
実際に経済的なインパクトとしてはNVIDIAさんの株価が90兆円分吹っ飛び、ナスダックの総合指数も3%あまり下落したと。今は戻ってきたらしいんですけど、それくらいの非常に大きなインパクトがあって、報道でもTVニュースで取り上げたりしているので、非常に世の中に興味を持たれている分野なのかなと思います。
◆注目を集める理由
これがなんでこれだけ注目を受けてるかっていう話についてなんですけど、自分が考えるに3つ観点があります。
一つ目はこのDeepSeekが作ったモデルがMoE(mixture of experts)と呼ばれる技術を使って低コストでフロンティアモデルに匹敵するような性能のモデルを作ることができたという点です。
二つ目が、OpenAIのo1がリーズニング(出力する前に考えること)によっていろんなタスクの性能を大きく上げることに成功していたんですけれども、その中身はどうやっているかがわからなかったんですが、それと同じようなことを「こうやったらできるよ」っていうのを発表し、実際に性能が上がった点です。
三つ目がこのDeepSeekという会社が中国の、しかも世の中ではあまり注目されていなかった会社であるという点です。例えば、すでに有名なアリババとかファーウェイなどの会社じゃなくて、(以前から技術者にはよく知られていたが)DeepSeekという一般からは注目されていなかった企業がこういうことができたというところが大きな驚きで、いろんな憶測が出て、今回のショックが起きたのではないかと思います。
今の3点について、解像度を上げてもう少し丁寧に説明していこうと思います。
◆ MoE技術の詳細とその経緯
一つ目のV3がMoEで低コストで実現できた点について言うと、前のランチトークでもまさにそのDeepSeekを紹介したわけですが、V3は670B(6700億)のモデルで非常にパラメーター数が多くて、学習トークン数が14.7テラトークンです。
普通にそれを今までと同じモデル(いわゆるDenseなモデルとよびます)で学習するとしたら、例えばLlama3が400Bで15テラトークンぐらいで、その時大体1万6000台のH100を使って3ヶ月ぐらいで学習していたんですけれども、それに比べてMoEを使うことによって学習コストがだいたい1/20ぐらいでできている。
さらに使ったハードウェアがH800っていう中国への輸出規制の関係でH100の性能をちょっと下げたものを2000台使って2ヶ月で学習することができたというのがあります。コストはいろんな言い方がありますが10億円はしない程度と言えると思います。
このMoEっていう技術自体は、新しい技術というわけではなく、2017年ぐらいにGoogleが最初に大規模なニューラルネットワークに利用して、OpenAIがGPT-4でMoEを採用したとほぼ見られていて、その後もいろんなところで採用されていました。
一方で、全てがMoEを採用していくかと言うとそうではなくて難しい部分があります。MoEは中で何をやっているかと言うと、モデル内部をエキスパートに分割して各トークンごとに一部のエキスパートに割り振る、つまりモデルの一部しか使わないということをやるので、結果として計算はかなり削れます。
しかし、計算量は減るんですがデータ転送量はそれほど減らない。そのため、1回の計算あたりのメモリバンド幅の比率、いわゆるB/F(byte per FLOPS)比が悪化するアプローチです。(計算する部分にデータを送るのが間に合わず、計算部分が遊んでいる状態になって実効効率が低くなる)。
ここ最近や今後みられる計算機の進化のトレンドは、計算の性能はどんどん上がる一方で、メモリバンド幅やネットワーク帯域の性能の進化はそれに追いつかないので、B/F比が悪化していきます。
そのため、MoEのようなアプローチはかなり厳しいんじゃないかと言われていましたが、DeepSeekは逆張りしてそこに賭けて、それを600Bぐらいのスケールまでやりきり、エンジニアリングの部分を頑張ってちゃんと動くようにしたというところがあります。そのへんは前の回でも紹介しています。
じゃあ今後MoEをみんな採用していくかですが、計算資源がボトルネックになっていない限りはMoEを積極的に採用するインセンティブはないのかなと今のところ思っています。
事前学習で学習規模を拡大していくことによる性能向上は、パラメータサイズが数百Bから1T、学習トークン数が20テラトークンでサチっていて、もちろんこれより拡大して性能向上も少しはありえますが、それよりもデータの質を改善したり、学習方法を工夫したり(後述)する方が改善幅が大きくなっています。
特にデータ枯渇問題、高品質なデータが足りないというところ(OpenAI共同創業者のサツキバー氏の言葉を借りれば「インターネットは一つしかない」)が拡大による性能向上が簡単ではないことを示しています。
一方、学習コストや推論コストを下げる方はあるかもしれません。今回DeepSeekが実現したMoEはかなりスパースなもので、全体の256エキスパートのうち8つだけ使ったものでした(通常は8エキスパートで1つだけ使ったり、16エキスパートで2つだけ使うなど)。
さらに理論上はもっとエキスパートを細かく数を増やしてスパースにしたほうが性能がよくなると予想されています(B/F比はさらに悪化するが)。研究や実装、アルゴリズム、ハードウェアなどの進化によって、エキスパート数を数千から数万に増やした上で、学習や推論時計算コストがさらに1/10とかになるということもあるかもしれません。
上記のような計算上の工夫があると計算需要が減るのではないかという話がありますが、企業間の競争が存在している以上、そのような工夫を取り入れた上で、「より投入計算量が大きい方が性能が高い」という状況は続いており、後述する強化学習などが登場するとまた違う種類の計算需要が生まれるのではないかと思います。
◆DeepSeek-R1による強化学習の成功
二つ目は、自分としても興味がある強化学習の方で、今回初めて紹介するR1の強化学習について説明します。
もともとLLMが出力する前に「考える」というのをどうやるんだろうというのは、いろんな人たちがいろんなアプローチで、こうやったらできるんじゃないかと提案していました。
ある程度うまくいくけど、OpenAIのo1ぐらいの性能まではいかないという話だったんですが、このR1が初めてo1と同等の性能が出るところまでいきました。
DeepSeekはシンプルな強化学習を使ってこうした思考過程が獲得できることを示しました。数学とかコードなど、正解が評価できるようなタスクにおいて(数学だったら正解があっているか、コードだったらテストに通っているかなど)うまくいったら外部から報酬を与えるというモデルで成功しました。
アプローチは、例えば数学の問題だったら数学の指示を出して、回答させます。回答は16個ぐらい出して、その16個それぞれを評価し報酬を与えます。
次に16個の集団の平均を計算して、それぞれの回答からその平均を引いて、標準偏差で割って正規化したものをスコアにして、このスコアに応じて次からはスコアが高かったような行動をとるように、低かったような行動はとらないようにモデルを更新します。
強化学習なので、自分自身に答えを試しに出させてみて、それを評価し、良かったものを次から採用するようにモデルを更新するというのを答えさせます。
なおこの強化学習手法はGRPOというもので2024年4月に提案されていますが、これ自体が重要というわけではなく、別の強化学習手法でもよいと思います。
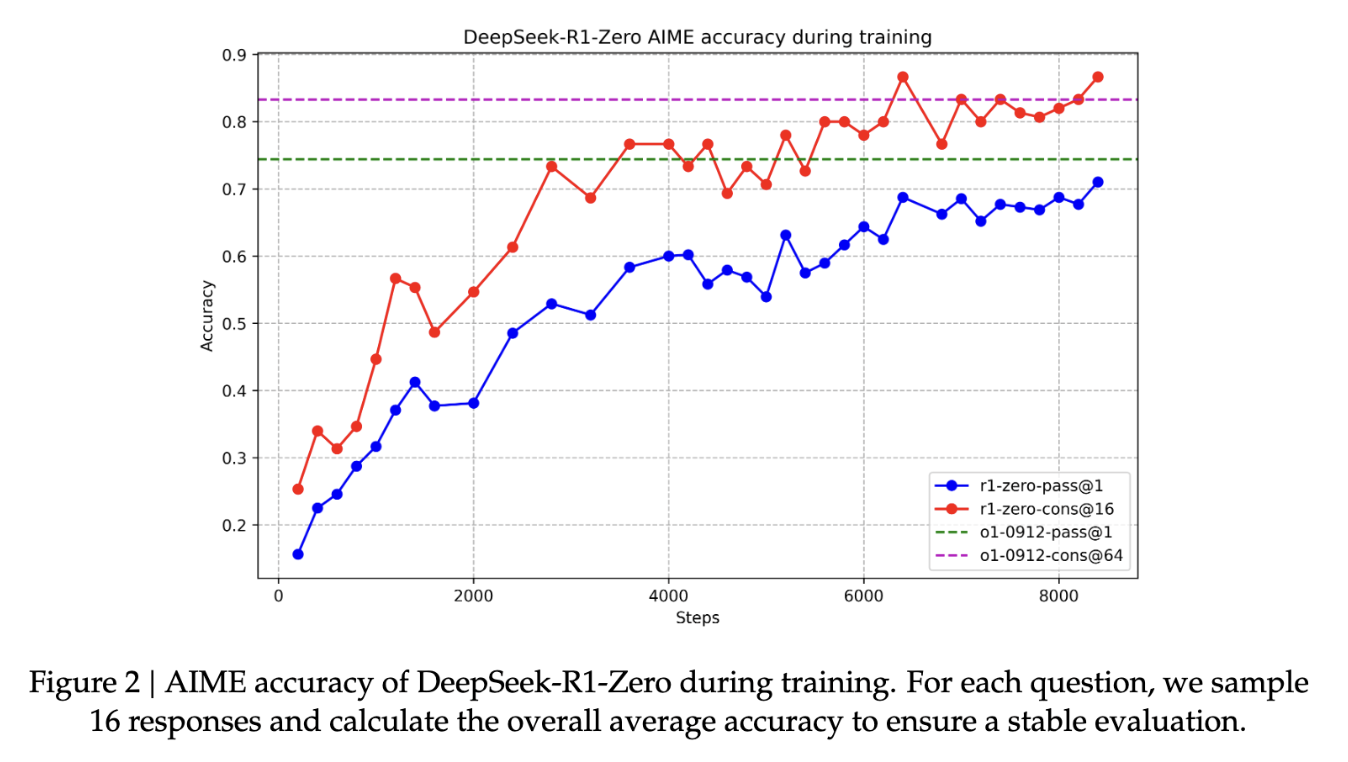
これが非常に成功し、AIMEと呼ばれる数学の難しいテストでも高いスコアを出すことができて、1万ステップぐらいでo1と同じぐらいの性能まで達することができました。
論文ではDeepSeekMathという強化学習でバッチサイズが1000ぐらいを利用していました。また今回の各回答のトークン数が1000から5000、1万ぐらいの長さのトークンとなっています。ですので、ここからは論文にかかれてなく、あくまで私の推測ですが、強化学習全体の試行錯誤で生成しているテキスト量が1ギガトークンぐらいになるのではないかと思います。これは本(20万字)でいえば1万冊分ぐらいに相当します。
これにより、様々な思考過程を獲得することができていました。例えば、途中で生成しながら間違えたかなと思ったらバックトラックしたり、今まで考えていたことと違うアプローチを取るなどの試行過程が自動的に出現し、性能が上がるという結果が得られました。
囲碁においても様々な戦略などを強化学習で獲得したAlphaZeroというのがありましたが、思考においてもそれが実現されることが示されたことになります。
これがR1-Zeroと呼ばれているもので、DeepSeek-V3に強化学習で思考能力を加えたものです。ただR1-Zeroだと英語と中国語が思考過程で混じってしまったり、人間が読めないものになっていたりするので、これを改良したのがR1です。
一番最初にコールドスタートで少なくとも人間が読めるようなところまでSFT(supervised fine-tuning、教師ありファインチューニング)を行い、その後に強化学習を行うことで、思考過程で一貫性を持たせるようにしました。その後通常のSFTと強化学習を行います。
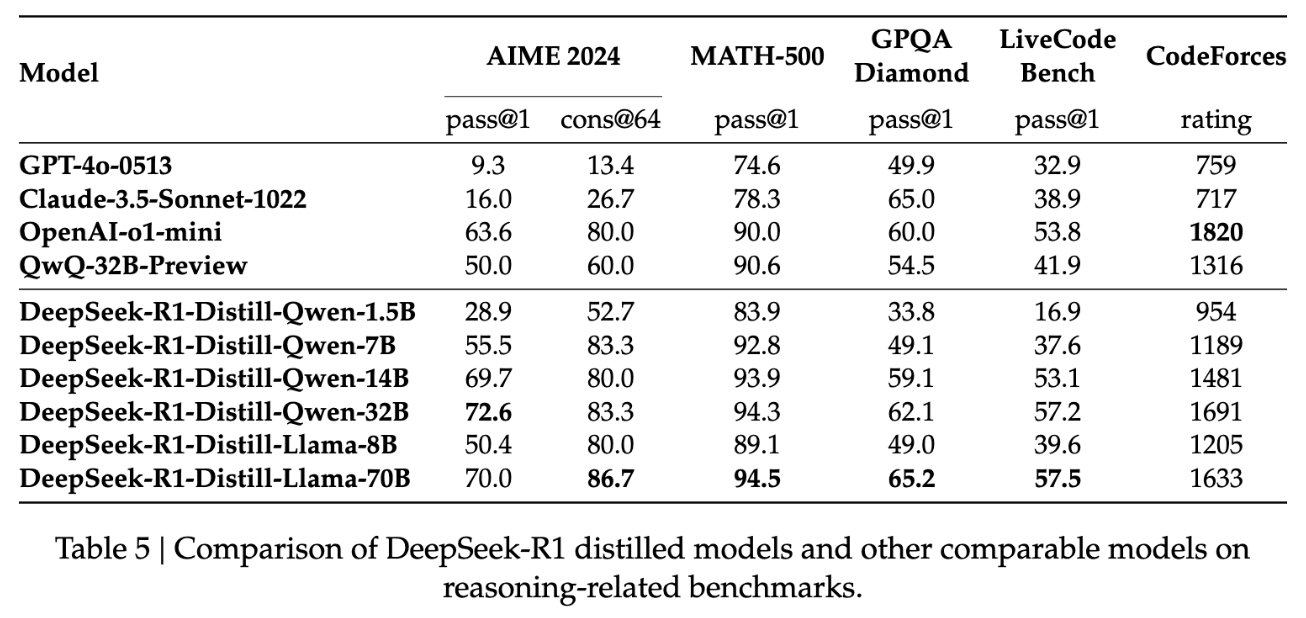
R1自体は元のV3と同じサイズのモデルですが思考過程を加えることで性能を大きく改善できています。ただR1ってめちゃくちゃ大きいですし、MoEも標準的な推論サービスではすごく扱いづらいので、これを蒸留して小さなサイズで標準的なモデル、QwenやLlamaにうつしています。
この場合、それぞれのサイズのモデルでも、それぞれのサイズで一番高い性能を出すことができたと報告しています。
この中で興味深かったのが、強化学習するときに小さなモデルだと性能が上がってこず、一定のサイズ以上のモデルからしか性能が上がらないという報告があります。おそらくこれまでの取り組みでも成功してこなかったのはある程度ベースモデルが能力を持っていないと、強化学習で性能があがってこないのだと思われます。
また、小さいベースモデルで、簡単な強化学習でも性能があがることはわかっています(TinyZero)。ベースモデルが賢いほど、強化学習の結果もよくなることがわかっています。
まとめると、強化学習で高い能力を獲得するにはベースモデルも賢くなくてはいけない。一度強化学習で能力を獲得できればそれを小さなモデルに蒸留などで移すことができる。
こうしたことからベースモデル自体の性能をあげる、そのあと強化学習で学習データにもないような能力を獲得できる(今回は思考過程でしたが他の環境と報酬を設定できる問題には広く適用できます)、一度できたらそれを小さなモデルに蒸留するというのが今後しばらく続いていくと思われます。

