Vol.27 GENIAC第2期の速報
◆GENIAC第2期の目標と進捗
経産省とNEDOの生成AI開発支援プロジェクトGENIACの第2期を昨年の後半から今年の4月中旬までにかけて進めています。
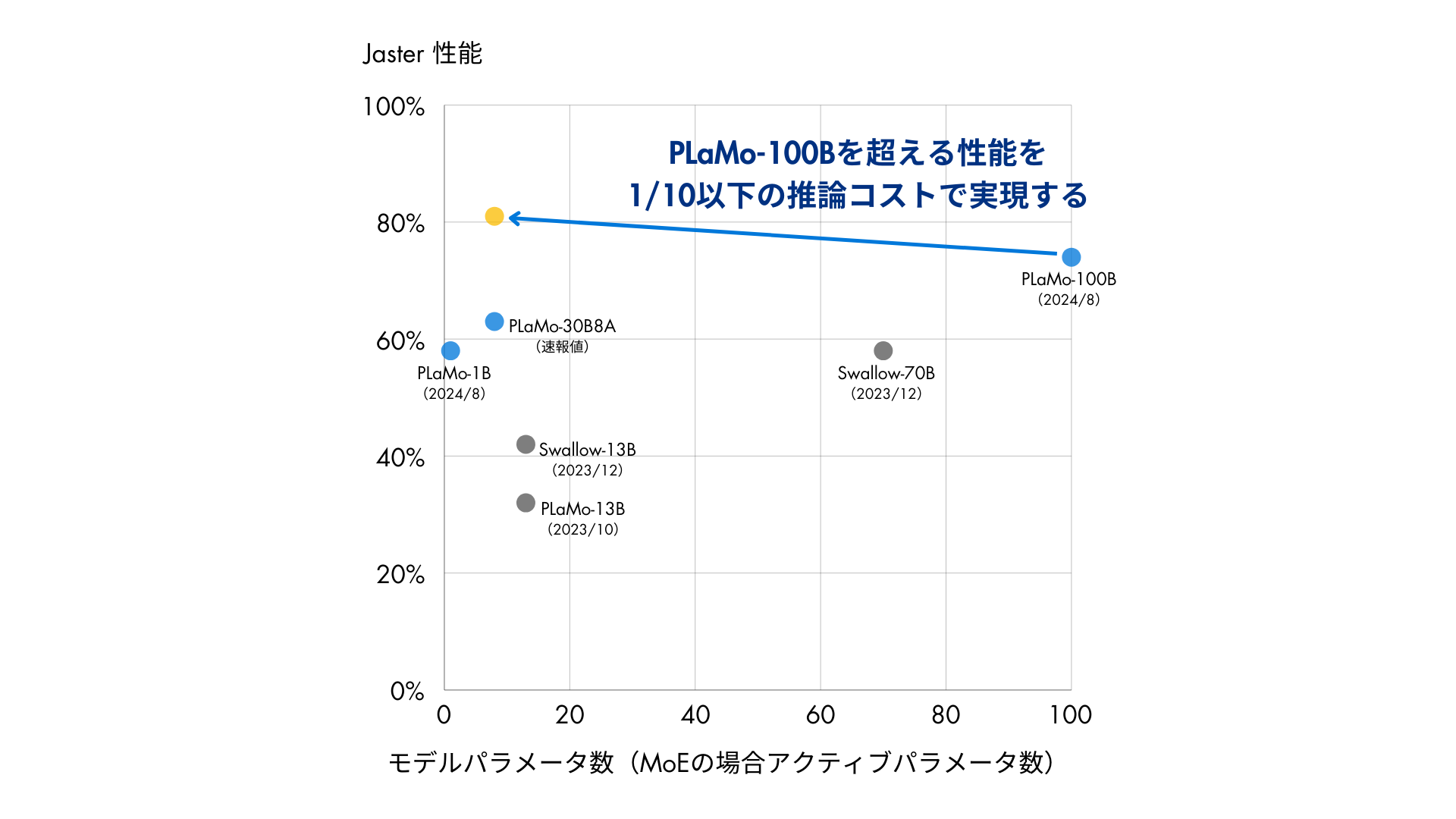
今期の目標はLLMなどを活用して大規模な高品質データを作って、同じサイズのモデルや投入計算量での性能を高くするというのを目標にして進めていました。具体的には2024年に作ったPLaMo-100Bの10分の1以下のサイズのモデルで性能を超えるというのを目標に掲げてやっていました。
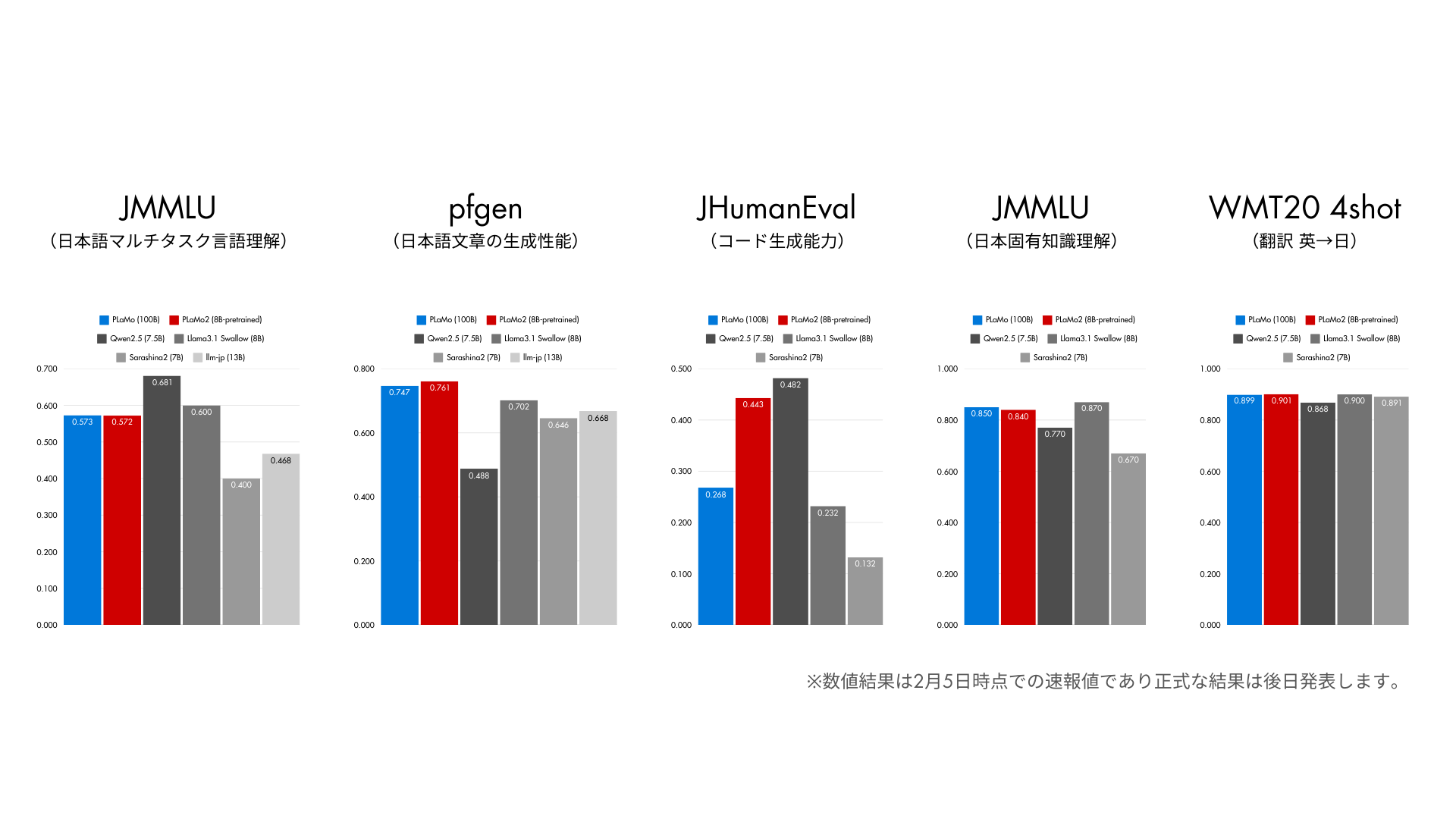
8Bモデルの学習が終わって、結果の速報値をまとめたのがこのグラフです。赤が今回作った8Bモデルで、青がPLaMo-100Bというモデルになります。このグラフが示すように今回作った8Bのモデルは100Bのモデルに全ての性能で同じか大きく改善(特にコード生成能力)しています。
また、今非常に世の中の進展が早くて、最新のモデルが毎週のように出ています。その中でこのモデルサイズ(8B)クラスで一番性能がいい代表としてQwenとGemma、日本で昨年12月に出たLlama3.1 Swallow、あとはSB IntuitionsのSarashinaの最近出たモデルと、llm-jpの最新モデルなどを比較しています。
結論から言うと、まず目標だったPLaMo-100Bのモデルに対して10分の1以下の8Bモデルで高い性能を達成することは、MMLUに関しては達成がほぼできたと言っていいと思います。
◆モデルの競争力
いろんなタスクに関するベンチマークで一番有名なMMLUを日本語に翻訳したのがJMMLUで、日本固有の熟語・公民・地理・日本史のタスクに関して言うと、そこは他のモデルに対して上回るような性能を達成できています。
あとは、今回のベンチマークで一番頑張ったのがコードの部分と数学の部分で、数学の部分はここに載せていませんが、コード(JHumanEval)のところは実際かなり上がって、8Bサイズで0.443まで上がってQwenに匹敵するぐらいになってます。
あとpfgenっていうベンチマークですが、これは日本語のいいベンチマークがなかなかないよねという話からimosさんが独自に作ったベンチマークで、いろんな日本固有の知識を問うような問題になっています。社外からはこれ向けにチューニングしたんじゃないかって言われるかもしれないですが、開発中にpfgenに向けた対策はしていません。
このpfgenで評価するとQwenに対して勝っていて、PLaMo-100BにもLlamaに対しても勝っています。なので、この8Bクラスに関して言うと、日本固有のタスクのところでは一番と言えます。
MMLUに関して言うと、ここは非常に競争の激しい領域で、GemmaとQwenが2つだけ抜けていて、あとは同じくらいという感じです。一応8Bはまだ事前学習の段階なので、ここから指示事後学習して、CoT(Chain of Thought)したりとかでまだ伸びる可能性はあるかなと思います。
◆今後の展望
PLaMoが今後どうなっていくかという話ですが、まず8Bモデルの学習は途中でして、この後に事後学習を行います。また、30Bモデルの学習もすでに開始しています。これらの成果を元に、高性能な小さなモデルを作ろうとしています。
あとは、もともと話をしていたようにモデルのアーキテクチャ自体がSamba(サンバ、Sliding Window AttentionとMambaの組み合わせ)という普通とは違うアーキテクチャを採用しています。それに伴う問題もいろいろあるんですが、従来のモデルでは扱えない、入力が連続的にずっと来ても対応できることが一つのウリになっています。
これぐらいの小さいモデルになれば、いろいろ工夫もしやすいと思うので、これからいろんな工夫を試してみようと思っています。

