Vol.30 高性能・小型化を実現したPLaMo 2
GENIAC第2期で、PLaMoの第2シリーズとなるPLaMo 2を作っています。今回は最初1Bを作って、その1Bの結果をもとにして8Bを作って、その8Bを元にプルーニングして(削って)2Bができています。
また、8Bをもとにして30Bの学習も今していて、その30Bの学習が無事成功したら、それをまたプルーニングして小さいモデルを作ることになります。
◆モデルサイズと性能
小さいモデルから大きいモデルを作るのと、大きいモデルから小さいモデルを作るのはどっちも重要で、それぞれのサイズのものを直接作るよりもずっと品質が高いモデルが作れるということが分かっています。
今日は8Bという大きいモデルを2Bという小さいモデルにすることによって、小さいモデルを直接学習した時よりもずっと良いモデルができたっていう話をします。
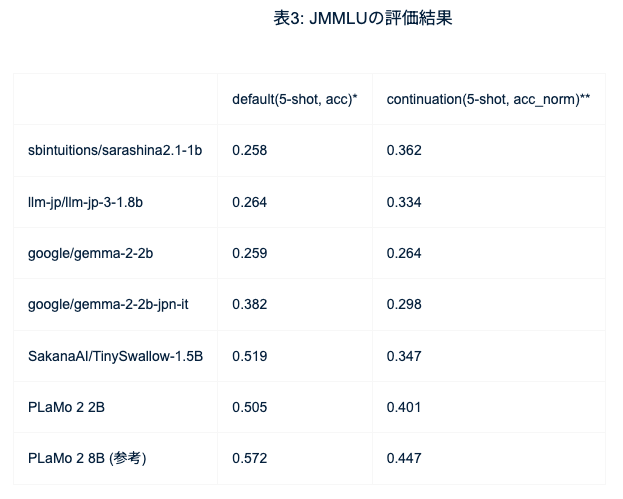
例えば一番分かりやすいのがMMLU(一般的な知識を問うようなタスクでJMMLUは日本語版)の結果です。MMLUは4択の問題になっていて、4択なのでランダムに答えると25%しか当たらない。なので大体の2Bとかの小さいモデルはほぼ回答できていないことになります。
既にPLaMo 2-1Bをリリースしてますが、その時の正答率は0.3くらいでした。で、今回そこから8Bのモデルを作りました。8Bはモデルサイズも大きくて、結果として投入計算量も大きいので、JMMLUのスコアも0.572と高いです。
そのモデルをプルーニングして小さくした2Bのモデルのスコアが0.505です。Qwenをベースにしているモデルはもともとの性能が高いのでTinySwallowが0.519で一番高いんですけれども、それと同じぐらいの性能がJMMLUの場合には達成できているし、Gemmaなど他のモデルより高い性能が達成できています。
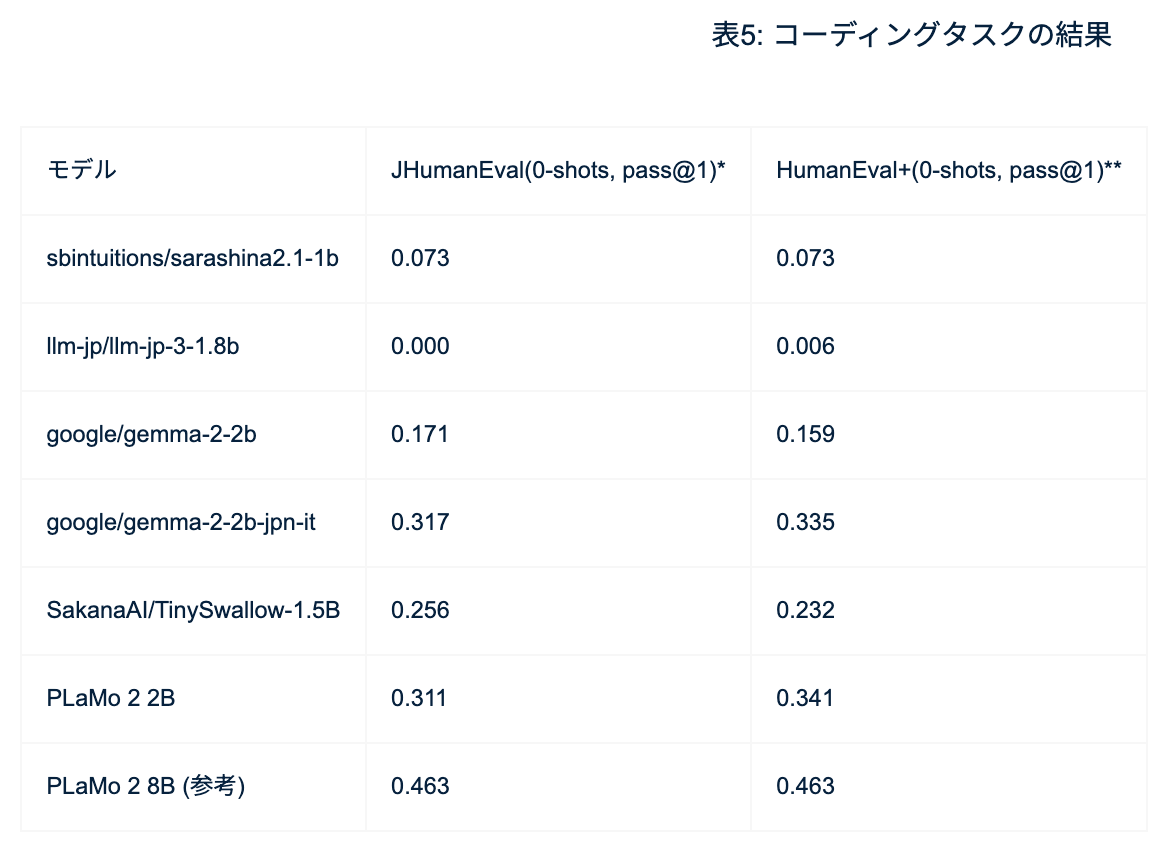
コーディングタスクの結果も似たように8Bが高い性能を持っていて、ちょっと落ちていますけれども2Bは0.311のスコアで、他のモデルでは全く解けないようなタスクが解けていたりします。
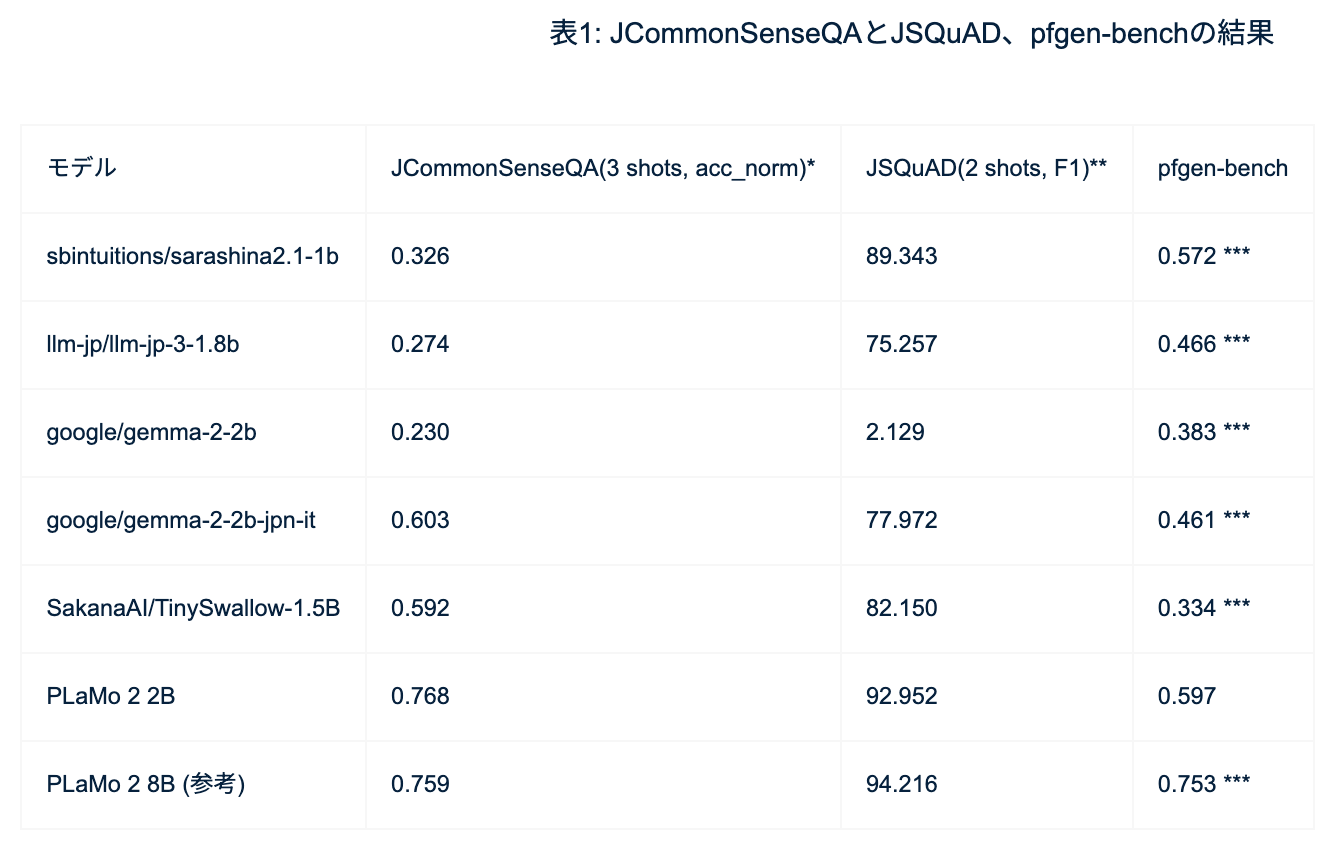
ベンチマークの中ではこれが一番差が出ていますが、日本の常識を問うような問題のJCommonSenseQAとか、JSQuAD、pfgenといったところのベンチマークでは、同サイズクラスの全モデルの中で一番高い性能を達成しています。
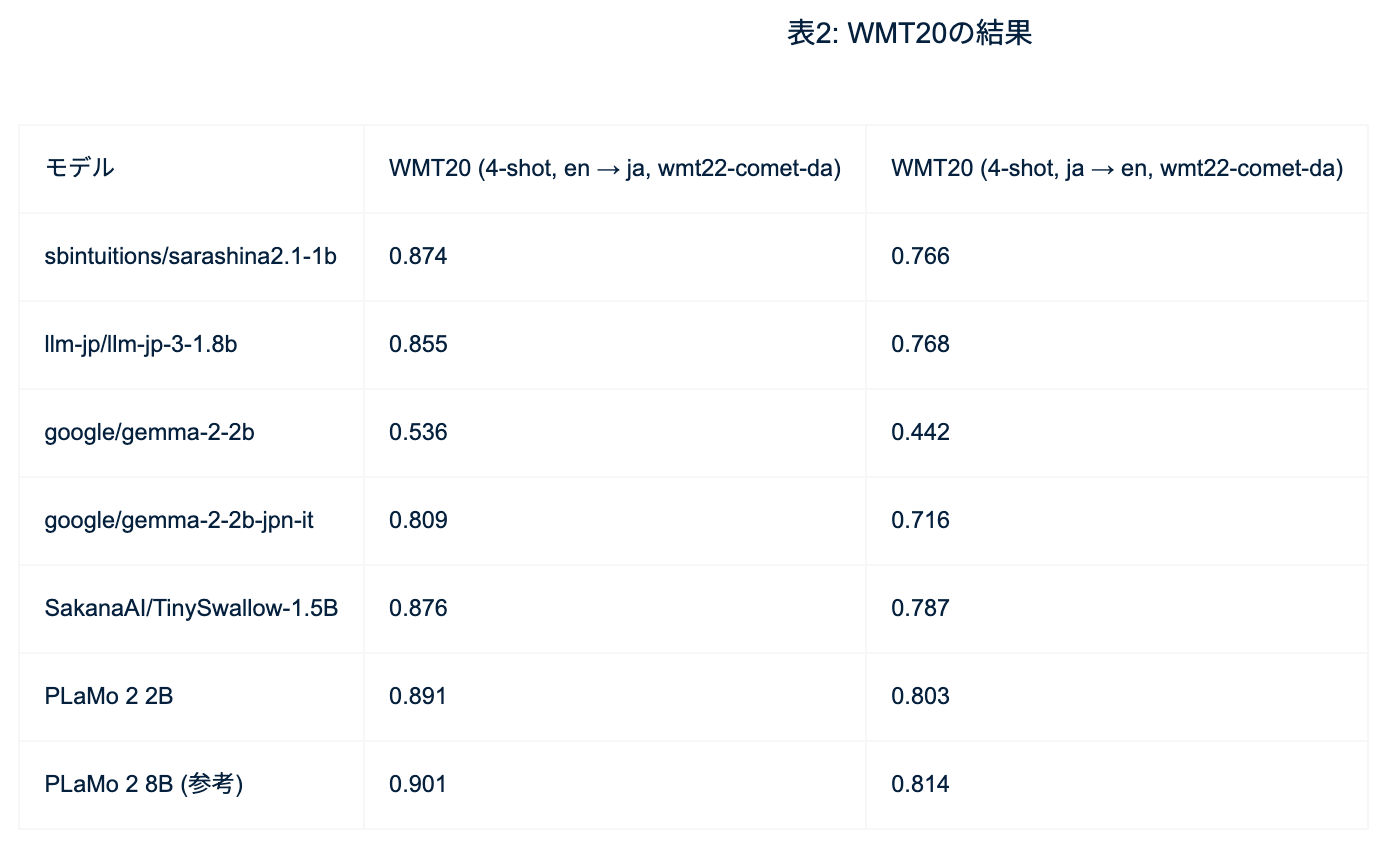
あと翻訳に関してですが、翻訳は性能がほぼ頭打ちなので上限なのですが、PLaMo 2-2Bのサイズで英語から日本語、日本語から英語への翻訳で高い性能が達成できています。
このPLaMo 2の学習データ自身には30言語弱の言語データが入っているので、日本語英語以外のいろんな言語も一通り扱うことができます。試してみると程度の差はありますが、いろんな言語が普通に翻訳できたり、言語理解ができます。社内にいる人はチャットボットチャンネルがあるのでちょっと試してみてもらえたらと思います。
◆プルーニング技術によるモデル軽量化
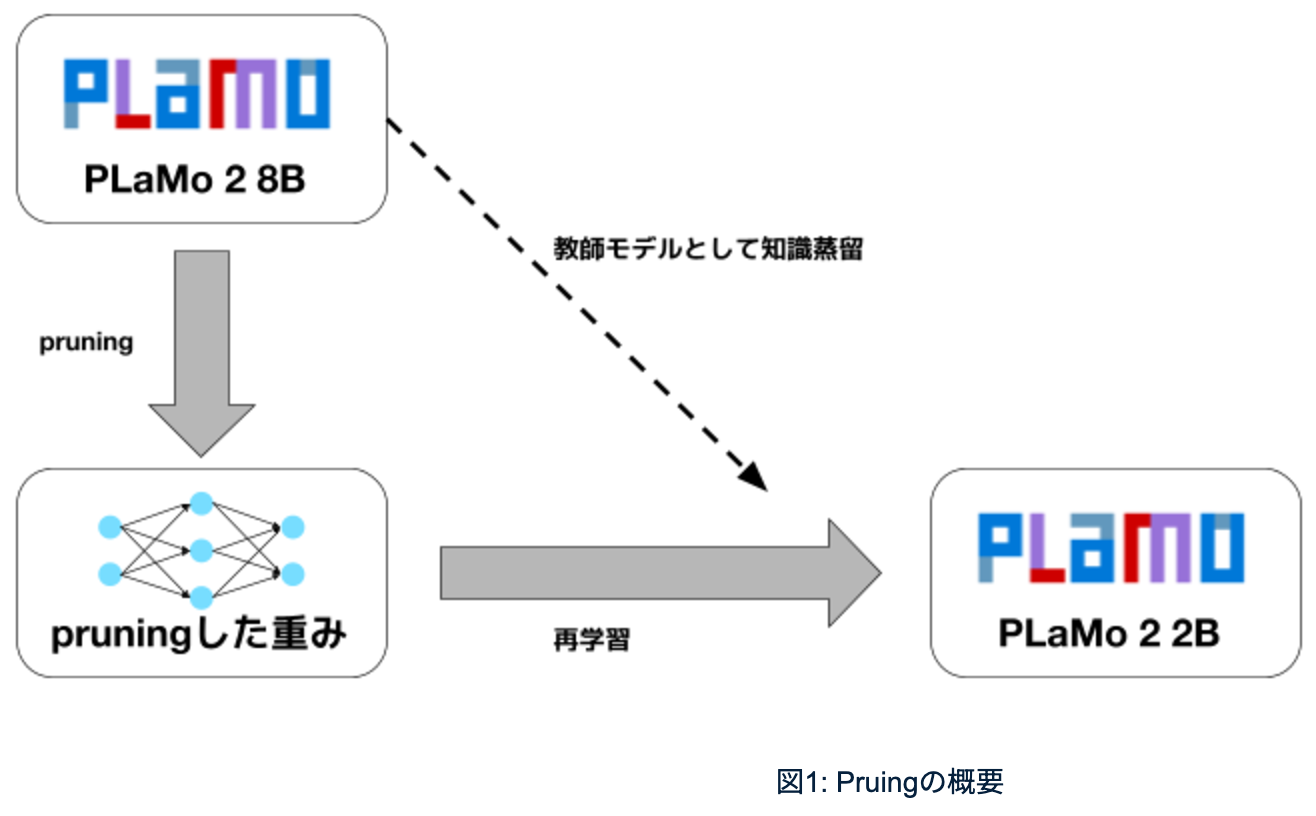
プルーニングなんですが、図1にある通りで、大きいモデル(左上)があって、パラメータがたくさんあるので、そのパラメータを間引いていきます。
今のGPUとかうちが作っているMN-Coreは連続したメモリ領域にあるようなものとの行列計算だとか掛け算は非常に性能が出るんですが、ランダムに飛び飛びの位置にあるデータにアクセスして計算すると全く性能が出ないので、基本的に適当にプルーニングすると性能が出ないという問題がありました。
そうした問題があるので、今使われているプルーニングは「structural pruning」と呼ばれているような手法で、連続した領域をプルーニングするという制約付き問題の中でプルーニングすることによって、プルーニングした後も連続した塊として残るようになっています。
具体的には、例えば一つのレイヤーを丸ごとプルーニングするっていうのは一番わかりやすいですが、あとはニューラルネットワークのMLPとかだったら中間層のどっかの一層のニューロンをプルーニングしたら、そこに繋がっている重みが全部同時にプルーニングされて残ったモデルは密なままっていうような、そういう形で制約付きの中でプルーニングをします。
ランダムに間引くだけだとそこでいろんな問題が起きるので、学習し調整しながらプルーニングするんですが、その際に親モデルを教師モデルとして知識蒸留を行います。
ここも結構大事になっていて、最近いろんな研究が出ているんですが、必ずしも本当の正解じゃなくて、自分と近いようなモデルを教師モデルとして使うっていうのが重要だということが分かっています。
例えばモデル差がすごくありすぎると知識蒸留が失敗することが分かっています。今回も例えば2Bサイズのモデルが8Bを先生だと思って、自分よりもちょっと賢い、真似できそうだなっていうぐらいのところと同じような出力を出すように学習すると、うまく自分のモデルパラメータを微調整して、少ないパラメータでもできるようになっています。
◆性能向上と商用化へ
こういう形でモデルを小さくしながらも性能を上げるということができるようになっています。それこそ半年前にPLaMo Liteっていうモデルを出したときと比べると性能が格段に上がっています。当時はMMLUとかも全く解けなかったんですが、今は解けるようになっているし、コードも分かるようになっています。
あと、これくらいのモデルサイズだとまだまだ伸びしろがあって、今世の中で一番小さいモデルサイズのところで進んでいるのってQwenとかそういったモデルになるんですが、そういったモデルに対してもタスクによってはそれを超えるような性能のモデルになっています。
特に容量が限られているので、例えば今回は日本語のベンチマークでかなり勝っていますが、これは学習データに日本語をたくさん入れられていて、その分他のデータは少なくなっていますが、ある種そういう日本語に寄ったようなところで強みを出しているっていうのがあると思います。
今まで作ったPLaMo-100B pretrainedなどのモデルはオープンにリリースしていましたが、商用には使えないという縛りを付けていました。今回リリースしたPLaMo 2の8Bのモデルに関しては、条件付きで商用利用可能な新しいライセンスの下で使えるようにしました。
PLaMo Community Licenseと呼ばれるモデルになっています。開発の計算資源に関しては一部ご支援をいただいているっていうのはあるんですが、会社としては、私たちは事業会社であり、実際かなりの人的、計算資源の金銭的な投資もし続けている状態なので、何らかの形でこれを事業として回収していくのが必要になります。
一方で、今LLMが社会で広がっていく中で、いろいろな形で試されたり、まだ想定していないような使われ方をしたり、あとは我々だけでは解決できないような技術的な課題も無数にありまして、そういったところに関しては、やはりコミュニティで解決をしていかなければいけないし、オープンにしていく部分をちゃんとしないといけないねっていうような話があり、今回このPLaMo Community Licenseを新しく設定をしました。
これによって、PLaMo 2-8Bは個人や中小規模の企業は有償無償問わず自由に使うことができます。例えば、既にユーザーの中にはこのモデルをベースにファインチューニングをして喋るようにして使っているユースケースが出ていたり、あとは、先ほど示したように翻訳でも十分な性能が出ているので、そういったところで使うだとかができるようになっています。
◆なぜPFNが大規模言語モデルを開発するのか
そもそも、なぜ私たちが大規模言語モデルを開発していることに関して言うと、いろんな理由があるんですが、まずは一つは、大規模言語モデルは単なるアプリケーションを超えてかなりインフラに近い、いろんな技術の中核になるというところがあると思っています。
その技術ノウハウを獲得して、ここから出てくるようないろんなアプリケーションサービスやインフラっていうのを作っていきたいというのがあります。
もう一つは、日本発の企業としての話なんですけれども、こうした基盤モデルを今それぞれの国だとか地域の企業が作っていますが、それぞれがモデルを作れるような技術力を保持しておかないといけないっていうようなことがあります。
一方で、今日本の大規模言語モデルは正直まだ世の中でたくさん使われている状況ではなく、大部分が海外サービスが提供する言語モデルであったり、あとはOSSを使っているような状況です。
それらを使ってサービス開発をするのも重要なんですが、大規模言語モデルを含む基盤モデルの開発ノウハウであったり、モデルを作れるような状態を残しておくということが重要だと考えています。
それによって、日本の価値観や文化的背景、考え方を反映したようなモデルを作れる状態にしておくことが重要じゃないかなというふうに考えています。
念のため言っておくと、PLaMoはそういう日本のためっていうのもあるんですが、ただそれだけではとてもビジネスとしても、我々の目標としてもダメで、基本的にはこのモデルを使って、最終的にはどこかの領域などでは世界中の人に使ってもらえるような製品サービスを作っていくのが目標になっています。
また、ライセンスに関してはいろいろ難しい話がありまして、例えばPLaMoを使って作ったデータを、再度学習データにして使っていいかっていうような問題があります。
Llamaライセンスの場合、Llamaで生成したデータに関しては、そのLlamaライセンスがどんどん波及していきます。それが利用を制限することがあります。
私たちとしては、公開するデータセットについては事前に申請して個別判断が入りますが、PLaMo Community Licenseからもっと制限なしで使えるような、Apache Licenseなどのライセンスに切り替えて公開する手続きができるような工夫をしています。
こういった試行錯誤をしながら今後もモデルをリリースしていきたいとおもっています。

