Vol.32 2035年までのAI計算資源の予測(1/3)
今2025年ですが、2035年までにAIが使う計算機のリソースや、計算機自身がどうなるのかという予測を作る機会があったので、今回はその話をしたいと思います。
もちろん予想なので大外れする可能性もありますし、私個人で作ったので会社の見解ではなく、あくまでも私の予想なんですが、とはいえ会社の中の詳しそうな人に聞いたり、いろいろ調べた上での予測なので、全く大外れということではないのかなというふうに思います。
◆2015年時点のAI計算需要予測
ちなみに2015年くらいに、AIを使った計算がどうなるかという予測を経産省に依頼されて作りまして、それが国の会議などで10年間使われていました。
その時の予測からまず紹介しましょう。それを見ると如何に10年後を予測するのが難しいかということが分かると思います。
例えばですね、半導体・デジタル産業戦略検討会議のこういう資料によく入っている、これですね。
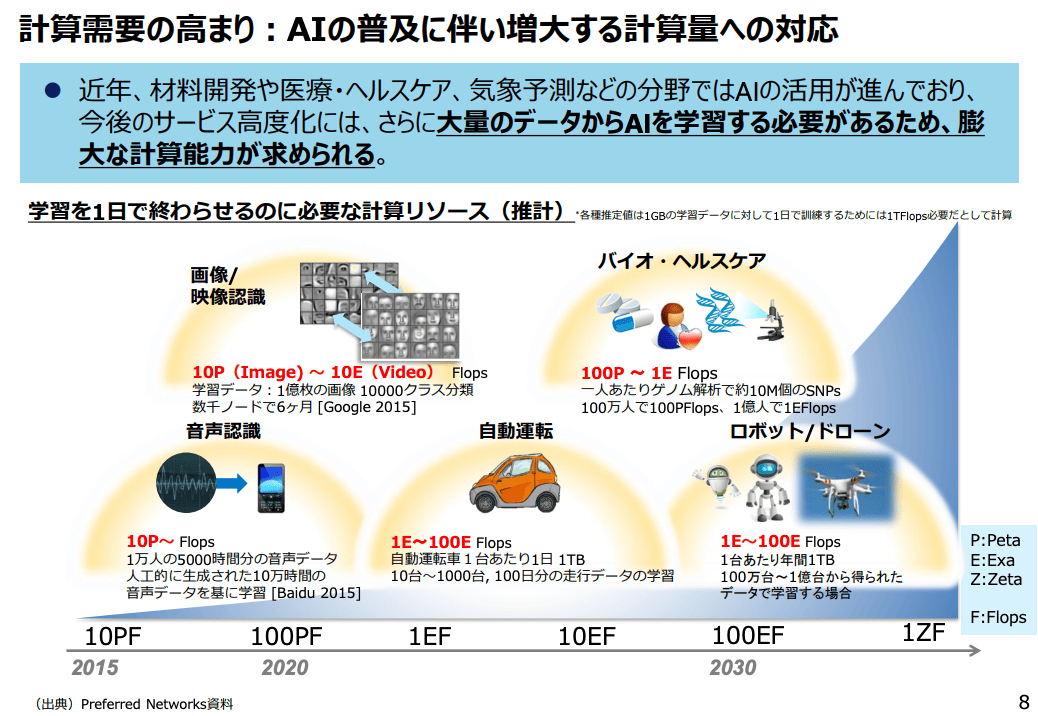
これ僕が作ったもので、手作り感あふれている感じがしますけれども。
この資料を作ったのがどういう時だったかというと、「Googleの猫がオートエンコーダでできるようになったよ」みたいなその後くらいのタイミングで、じゃあこれからAIで計算機がどんどん必要になるんじゃないか、どれぐらい必要になるんでしょうねっていうのを考えてください、というところで作ったものです。
考え方としては、1ギガデータの学習に対して1日で学習させるためには、1テラフロップス必要だとして、画像データだったらこれくらい増えるだろうという感じで、それぞれで見積もりを出しました。
今はペタフロップスって1GPUのTensorCoreで普通に2ペタとか出るんですが、当時はこのペタっていうのが数千ノードで実現するという感じのオーダーだった世界なんですね。
そんな中で自分の予想としては、自動運転はこれぐらいたくさんデータが集まるだろうから、100日分データを集めたらこのくらいかかるだろうと。バイオ・ヘルスケアもゲノムがいっぱいあるから、SNPsって呼ばれる変異情報を集めたらこのくらいだろうと。さらに、ロボット・ドローンが一番大きくなるだろう、というような感じで作っていました。
これを2015年に作っていて、学習には数エクサフロップスぐらい、という予測を立てていました。
◆2015年予測の結果
結論から言うと、計算量のオーダーは大体合ってた。今の一番大きいモデルはもうちょっと大きいんですが、普通のモデルを学習するときのオーダーっていうのは大体このくらいのオーダーの計算機を使います。
一方で、例えばGPUはPFNだとLLMの学習に500枚とか300枚ぐらい使うので、1GPUが先ほど言ったように1ペタぐらいなんで、1エクサとか10エクサのオーダーが使われると。
それを1日ではなく、普通は100日ぐらいかけて学習させるので、そこはオーダーがもうちょっと大きくなります。あと世の中のLLMの最大規模っていうのはもっと桁が違って大きくなります。
大きく外れたのは、需要として来るのは画像だと思っていたんですが、ご存知の通りLLMが来まして、LLMが圧倒的に一番使われたということになります。
私自身が大学時代言語モデルを研究していたわけですけれど、2015年当時は言語モデルがこんなに使われるようになるとは思っていなかったです。
◆2035年までの成長シナリオ
そんな中で今回作ったのが今後10年の予測資料になります。
相当常識から外れて考えないと指数的な変化なので当たらないと思います。とはいえ完全に吹っ飛んで考えると行き過ぎてしまうのでバランスが必要になります。
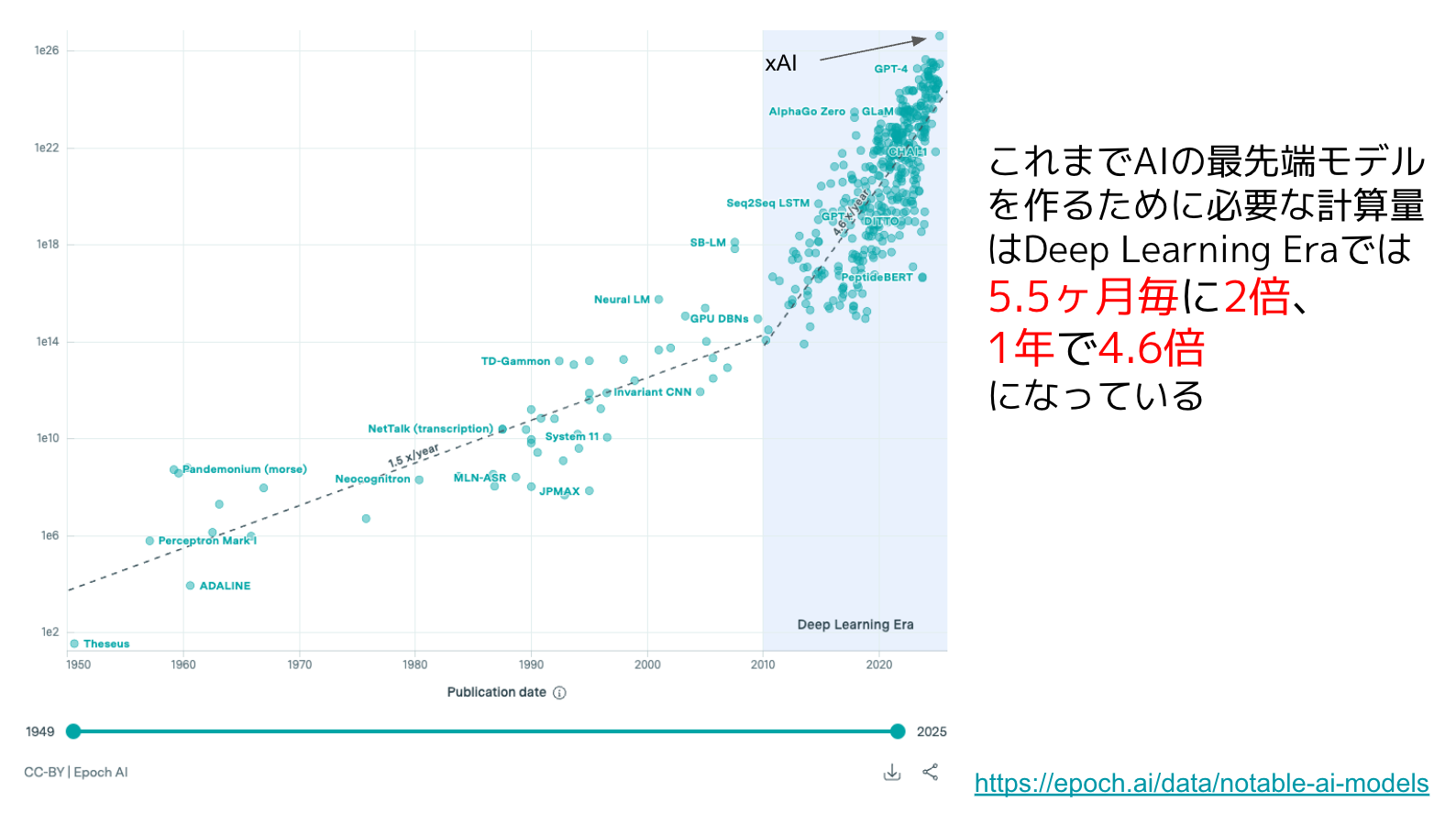
まず考え方ですが、今どうなっているかと言うと、上のグラフはEPOCH AIが作っている有名なグラフです。これは最先端AIを作るためにどれだけの計算力が使われているのかを表したグラフです。
横軸が1950年、60年、70年と大きくなっていて、グレーの帯に入るタイミングが2010年です。縦軸がその時に使っている計算資源になっています。
計算資源は2010年まではいろんなモデルがあり、一番最初はパーセプトロンとかネオコグニトロンなどありますけれども、だいたい1年あたりで1.5倍のペースで進んでいました。
それが2010年ぐらいからディープラーニング時代に入りまして、1年あたり4.6倍のペースで必要な計算資源がガーッと増えていったというのがこの15年間続いています。
現時点の一番上の点がxAIのモデルなんですが、発表していないだけでOpenAIとかAnthropicも多分同じぐらいの計算資源を使っていると思います。
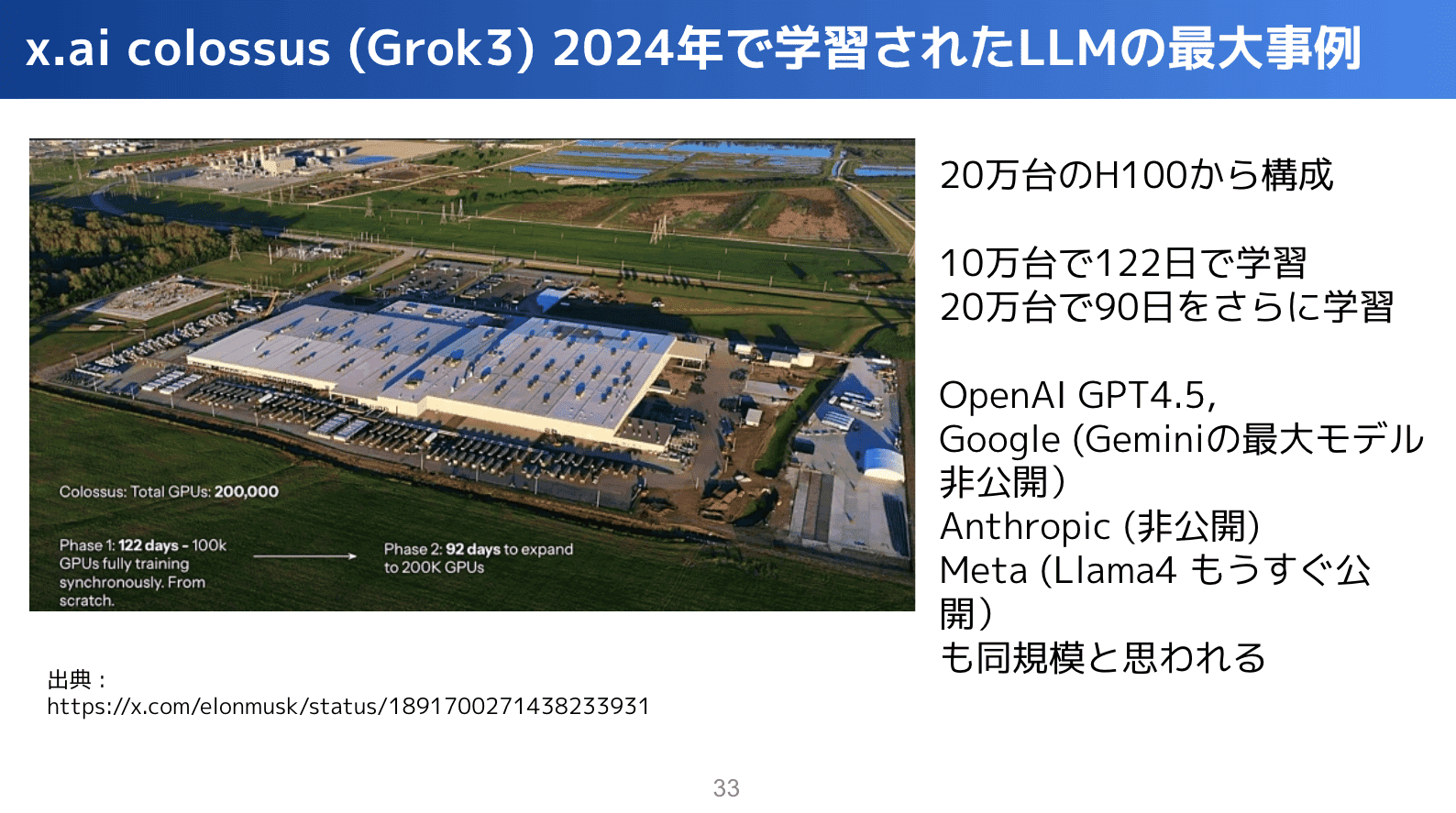
公開情報がすごく少ない中で、xAIだけがこのくらい計算資源使ったよって公開しているので、それを元に書きますと、xAIがGrok3を学習するために作ったデータセンターが20万台のH100から作られていて、10万台で4ヶ月学習して、20万台で3ヶ月さらに学習したモデルがGrok3です。
他のモデルも、買っているGPUの枚数からしても大体同じぐらいの枚数を使って作っているのではないかと推測できます。
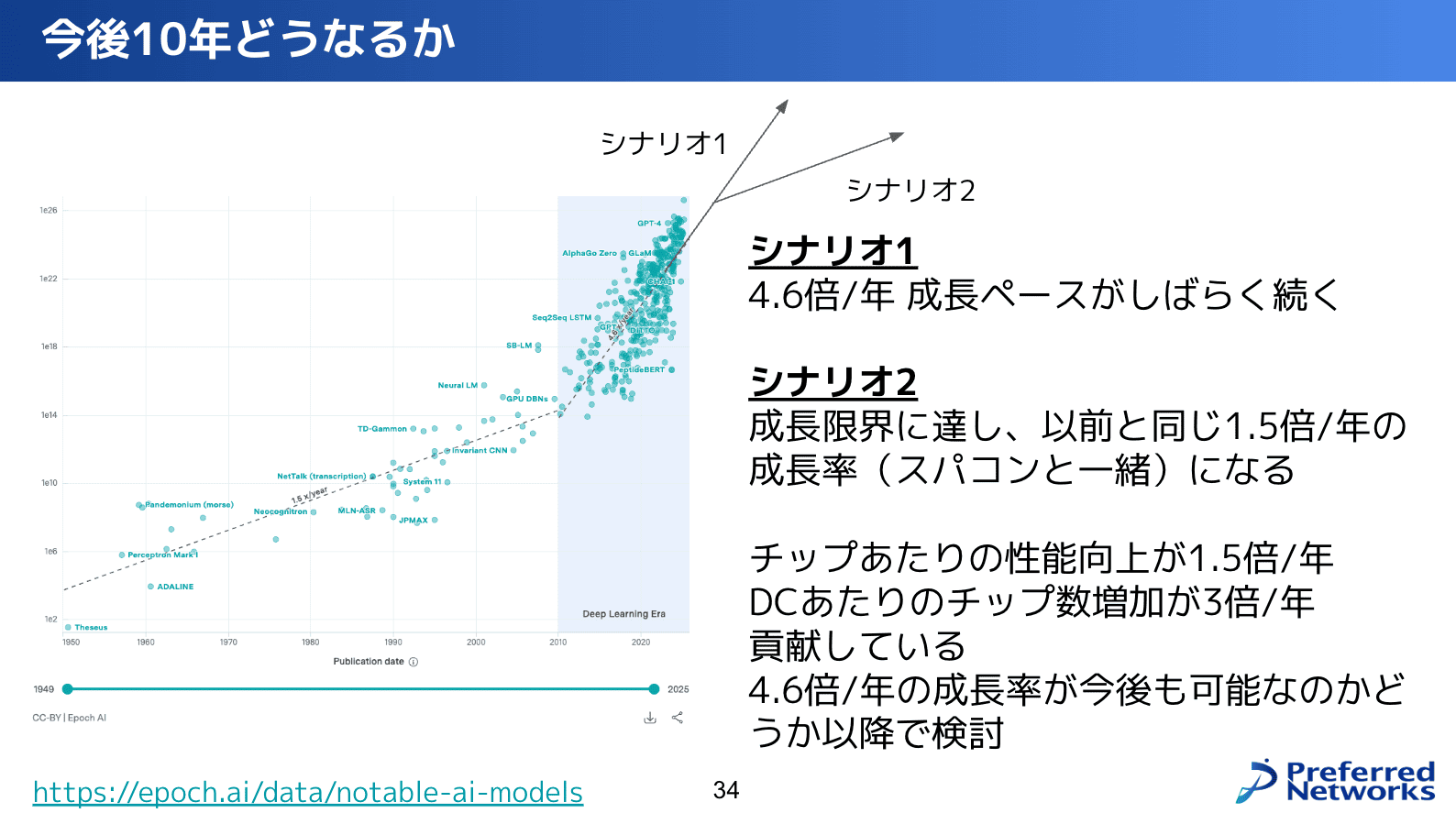
今後は、このペースがどうなるのかを考えるにあたって、シナリオ1としてはこの4.6倍っていう成長がしばらくまだ続く。シナリオ2は成長限界に達して以前と同じような1.5倍/年の成長率になるのかなと。どっちになるだろうということを考えます。
4.6倍を具体的にどのように達成しているかを分解してみると、チップあたりの性能向上が1年あたり1.5倍、データセンターあたりのチップ数増加が1年あたり3倍貢献しています。
次回、第2回は成長シナリオ詳細についての説明と結論についてのトークです

