Vol.33 2035年までのAI計算資源の予測(2/3)
◆チップレベルの性能限界

4.6倍の成長率が今後も可能かというのを検討します。まずチップあたり1.5倍/年が続けられるかですが、今のチップ、特にNVIDIAのGPUは1枚あたり1kW超の電力が必要です。PFNのチップMN-Coreは省電力をうたっていますが、それでも最高性能を出そうと思うと同様の電力が必要になります。
Blackwell世代(2025年)から次のRubin世代(2027年)でもかなり半導体側の微細化などのいろんな改良とアーキテクチャの改良があって、台当たり1.6倍の性能改善があるんだろうという風に見られます。なので年あたり30%、1.5倍ほどではないですが、30%ぐらいまでは頑張れると。
一方で、この微細化をすることによって、小さくすればするほど純粋に動かす電子の数が少なくなるので電力性能も上がるというムーアの法則が以前はあったわけですが、小さくなりすぎていて何が起こっているかというと、小さくするとしても電力効率が上がらないし、その寄生容量と呼ばれるようなリーク電流の部分の貢献がすごく大きくなるというのがあります。
こうした問題があるので、今この数年というのは、例えばNVIDIAのGPUや他もそうなんですけども、性能を上げようと思った場合には、チップの面積を増やして電力を増やすしかない。これはこれで大変なんですが、それで性能向上を達成しています。
パッケージ内の台数も増やしていますが、ここは物理限界があると。さらにはラック内あたりのパッケージ数を増やして高密度にするというような方法もあります。これはできそう。
これは牧本Waveと呼ばれる、牧本さんという有名な方が結構前に提唱した話で、高密度化とそうじゃない波が来るというやつにはまっているんですけれども、それも高密度化が2027年までは続くだろうと予測しており、それに沿っています。
◆NVIDIAロードマップに基づく計算機性能予測
具体的にどれくらいの性能が2027年までに達成されそうかについては、先日NVIDIAが出したロードマップを元に考えてみると(詳細違っていたらすいません)、2024年時点で出てきたものは、1ラック内にパッケージが72個入っています(NVL72)。
1パッケージごとに2台入っていて、その中に144個の台が入っています。このラック全体だと360ペタフロップスの性能が出て、電力量が120kW。
細かく見る必要はないんですが、2025年に次のUltraが出て、次にRubin世代が出て、Rubin Ultraが2027年に出ると。チップの世代が変わって、基本的には高密度化していくという流れがあります。
Rubin Ultraはパッケージ数144で、1パッケージに4個の台が入って台数が576になります。1ラック(ラックという単位になるのかわからないんですが)に必要な電力量は600kW。
600kWというのは、新幹線1両分に必要な電力と一緒らしいです。おそらくお値段は今のチップが600枚近く集まると考えると、これ1個で数十億円というような規模で、1ラックFP8で5エクサが出るような性能になっています。これをたくさん並べるようなデータセンターが登場してくると。
こんな感じで2027年までは頑張っていくと思うんですが、じゃあその後も同じ感じで進められるかっていうと、この中でいうと特に電力量や電力密度に限界があるだろうと思います。

チップあたりの使用電力量を大きく改善しない限り、1ラックあたりとかチップあたりの電力量が指数的に上がっていくことになりますのでかなり難しいです。
チップあたりの使用電力量を今と変えずに10年間で1.5倍/年の性能改善し続けるとしたら、電力あたりの性能が100倍出る必要があります。今のチップは、大雑把に半分ぐらいの電力が計算に使われていて、もう半分がデータ転送に使われています。
計算に関して言うと、先ほど話したように微細化を続けてももうこれ以上電力を下げることはできないと。消費電力Pは式「P=CV2f」(Cは容量、Vは電圧, fは周波数)で、こういう形で見ると電力を下げようと思った場合には、電圧を思いっきり下げて、周波数を思いっきり下げるっていうようなことが必要になります。
これは、今とっているようなアプローチとはかなり違うアプローチが必要になる、ということになります。なので、計算機はこのように思いっきり違うアプローチを取ったら実現できるかもしれない。
次にメモリに関して言うと、現在HBM3っていうのが、1bitあたり大体5pJぐらい使っているものを、100倍(0.05pJに)改善する必要があります。
これにあたっては新しいメモリインターフェースや新材料が必要になるかもしれないし、HBM自身がものすごく改善を続けて達成していくのを目指す必要があります。
◆データセンターの規模拡大は可能か
次に、残りの3倍/年の成長に貢献しているデータセンターの規模拡大できるのかという話をさせてもらいます。

Grok3を作るときに使ったデータセンターは、20万台のクラスタで300MWの電力が必要になります。
これがどれぐらいの規模かというと、原発の4分の1基分になり、東京都の消費電力量の4%の規模になります。ものすごい規模なんですが、これを1モデル学習するためだけに半年間占有するということです。
これより大きいデータセンターを作るのかという話でいうと、報道では例えばGoogleは1ギガワット級のデータセンターを作るとか、あとは電力会社としては数年あとには数ギガワット級のデータセンターを稼働できるように準備しているというような記事が出ています。
データセンターを作ろうとしたら簡単に作れる話じゃなく電力を供給できる場所だとか用地とかいろんな問題があるので、1ギガワット級だとか数ギガワット級やるとしたら情報が出ていていないとおかしいというので大体分かってきています。
今どれくらい分かっているかというと、EPOCH AIは2030年までには1から5ギガワットのデータセンターはできるんじゃないかと言っています。
ちなみにここまでお金の話は全く無視して話していますので、お金の問題で全く出来ないみたいな可能性はあると思います。ここまではあくまで技術的な話です。
先ほど紹介したRubin Ultraは1ラック600kWと説明しましたが、それが2000ラックで1.2GWなので、それで10ゼタフロップスになります。
これが2026年に稼働するなら、12.5倍で、1年あたりの4倍改善ぐらいになります。まとめると、2026年にRubin Ultraを2000ラック使った1GW長級のデータセンターが稼働するのであれば年あたり4倍の改善は達成可能だし、その次の年はまたこれの4倍なので2027年に5GWのデータセンターが稼働するんだったらさらにもう1年可能です。
なので2027年ぐらいまでは達成できるのですが、その次に同じようにやるとしたら、単純に考えたら更にこの4倍なので、20GWクラスタになるわけですね。20GWクラスタだと原発5基分です。
発電所は建てるのに10年ぐらいかかりますので、2027年より先は、電力がそもそもないとか、排熱の問題だとか、いろんなことを考えると難しいよねってなります。
◆LLMのデータ枯渇問題
お金はなんとかなるとしても、もう一つ厄介な問題としては、今のLLMは大規模化することで賢くなるっていう方法論がありますが、一方で、今までと同じような事前学習は良質なデータが元になっています。
少なくとも今はあるかもしれないけれど、これが毎年指数的に増えるかっていうとそうではないかもしれないと。

Ilya Sutskever氏は去年のNeurIPSでの講演で「インターネットは一つしかないし、データはもう増えない化石燃料のようなものだ」と言っていて、今の私たちが知っている事前学習は終わるだろう、というような講演をしています。なので、今の事前学習のスケーリング則による改善はおそらく現在のサイズ、先ほどのようなxAIとかそれぐらいのサイズで終わるかもしれない。
私は終わると思うんですけれども、一方で、AIのこれまでの研究歴史が示してきたのは、とにかく計算性能さえ上がればいい方法が見つかって改善する別方式見つかるということなので、多分いい方法が見つかって計算機を使って賢くなるというのは今後もできるのかなとは思います。
◆予測の結論
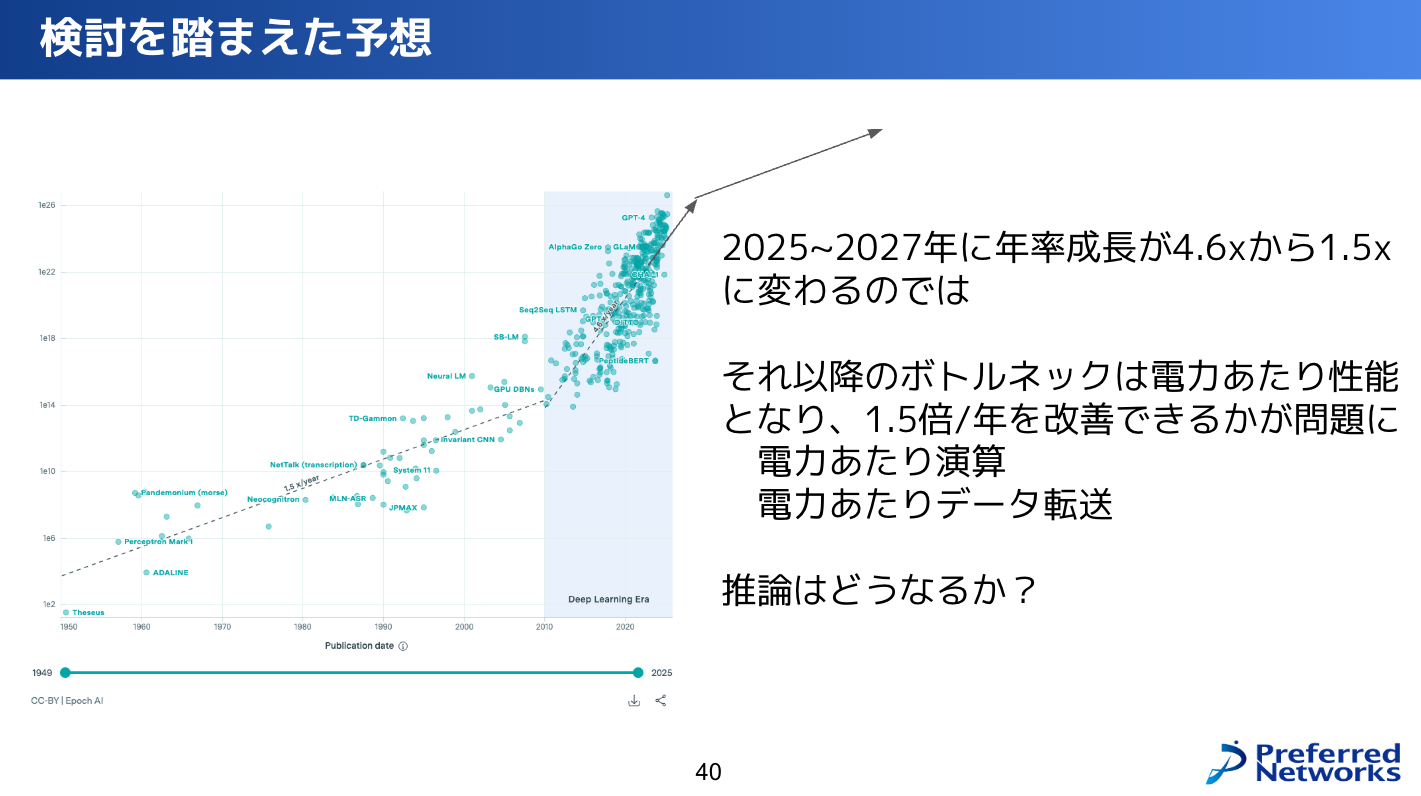
以上の検討を踏まえると結論はこんな感じかなと。2027年くらいまでは年率成長4倍くらいはいけるだろうと思います。それ以降は、電力あたりの性能がボトルネックになるかなっていうのが予想したことです。
ただ1.5倍/年で成長し続けるので、それをうまい形で使ってAI自身が賢くなるというのはあると思います。
次回、最終回は推論需要の予測についてのトークです

