Vol.36 番外編 LLMベースのテキスト埋め込みモデル開発
エンジニアの鈴木海渡です。PFNで作っているLLM「PLaMo」をベースとした「テキスト埋め込みモデルPLaMo-Embedding-1B」というのを開発しました。
半年前くらいのメールマガジンでインターンさんにやってもらったPLaMoベースのテキスト埋め込みモデルの話をしたんですが、それを引き続きやって、より強いモデルができたという話になります。
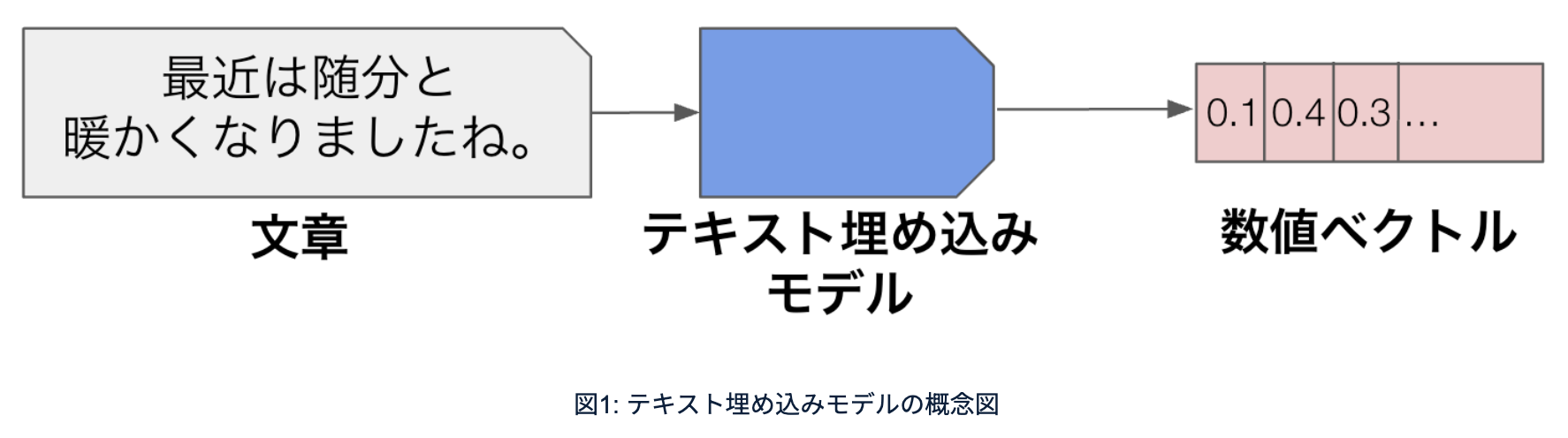
テキスト埋め込みモデルは、文章を数値ベクトル(0.1、0.3、0.4みたいな数字が何十、何百、何千と並んだようなもの)に変換することができるモデルで、これを使うと文章を1回数値ベクトルに変換して、数値ベクトル同士は類似度が計算できるので、「この文章とこの文章は似ています」というのを0.9とか0.3とか、類似度で測れるようになります。
これができると、ある文章に対して類似度が高い文章を引っ張ってきて、情報検索をすることができます。 例えば社内文書で調べたいことがあって、文章を入れた時に必要な情報が入っている文書を持ってくる、みたいな時にも使うことができます。
◆日本語トップクラスの性能達成
今回開発したPLaMo-Embedding-1Bは、日本語に特化したテキスト埋め込みモデルで、情報検索などに使うことができます。
JMTEBっていう日本語のテキスト埋め込みのベンチマークで、OpenAIのtext-embedding-3-largeなどのモデルを上回って、日本語モデルとしてトップクラスの性能を達成しています。
特に検索タスクで優れた性能を示しています。 このモデルの重みをHugging Faceで公開していまして、Apache v2.0ライセンスで公開されているので、商用利用を含めて自由にお使いいただくことができます。
すでにお試しいただいている方が割といて、実際これを使っていろんな検索システムを作ってみたらこういうのがヒットしました、みたいなことを報告してくれている人もいて、大変嬉しく思っています。
◆学習プロセス
ざっくりではありますが、技術的詳細を説明します。
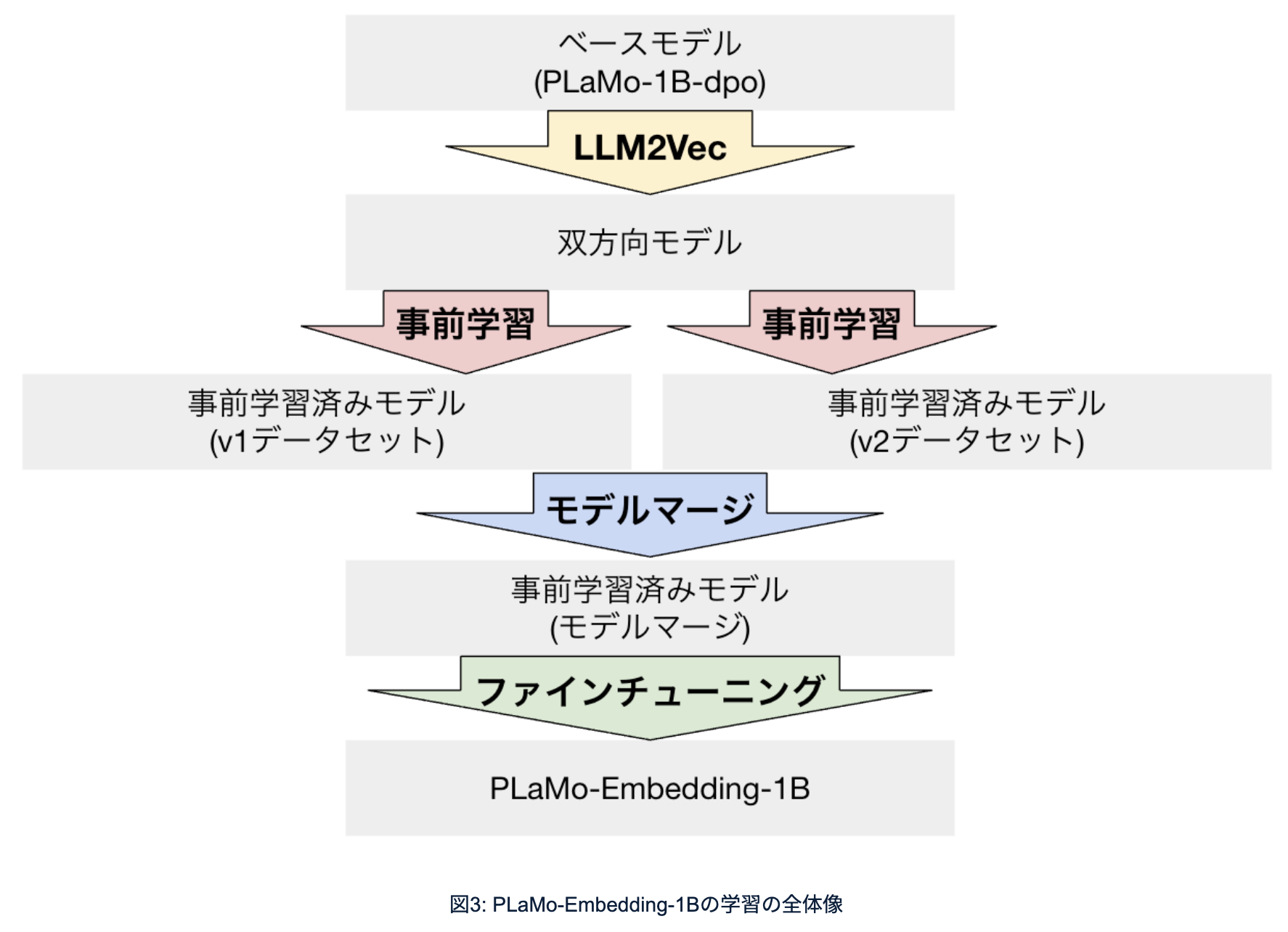
どういう風に学習したかというと、面倒なんですが、LLM2Vec、事前学習、モデルマージ、ファインチューニングという4段階をやっています。
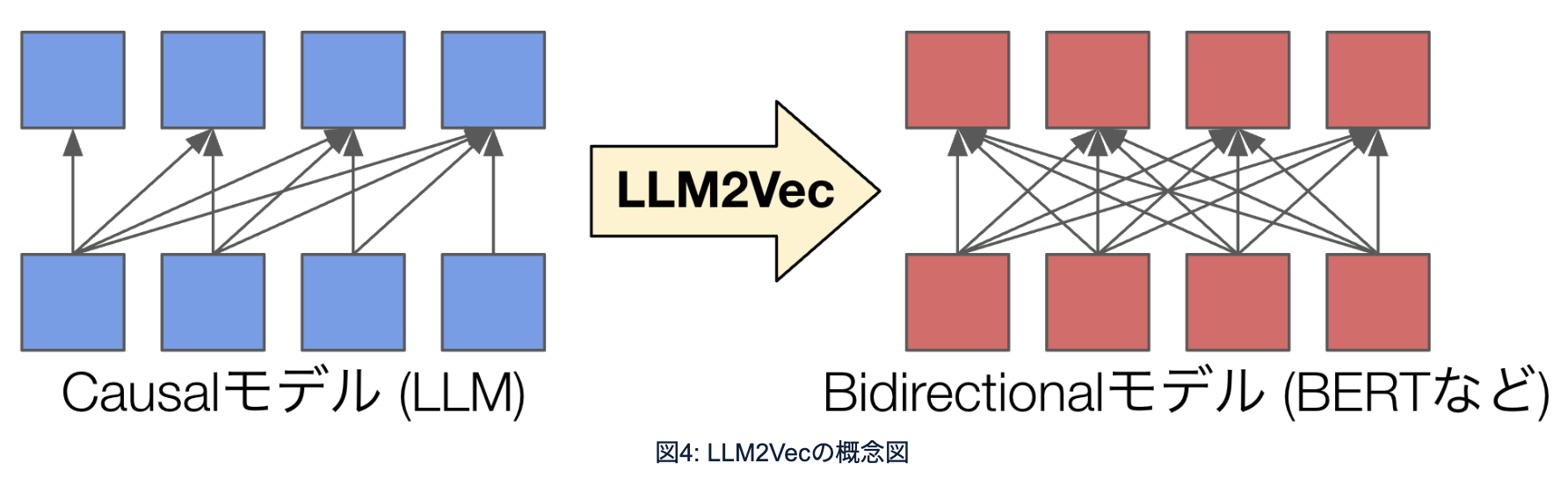
最初にLLM2Vecなんですが、LLMみたいな言語モデルはTransformerによって実装されているんですが、ある文章、ある瞬間の単語、トークンを生成するときに、その時点より過去のトークンしか見ません。
これは未来のトークンはまだ生成されていないから読めないためなのですが、テキスト埋め込みモデルは最初から文章が全部あって、それに対する適切な数値ベクトルを計算したいので、未来のトークンも見て各トークンの瞬間の計算を行ってよいということになります。
未来の情報を見られないLLMをCausalモデルと言って、未来の情報も見ていいものをBidirectionalモデルと言います。最近はBidirectionalモデルの方が使える情報が多いので、同じモデルの大きさだったら強いと言われています。
今回テキスト埋め込みモデルのタスクに限ってはBidirectionalモデルを使うことができるのですが、元のPLaMoがLLMなので、CausalモデルからBidirectionalモデルに変換する処理を最初に入れました。これをLLM2Vecと呼んでいます。
次に事前学習です。テキスト埋め込みモデルの近年の学習においては、大規模なデータセットで事前学習をして、その後に高品質なデータでファインチューニングすることが一般的です。
基本的にはこの事前学習もファインチューニングも同じような学習方式ではあって、ある文章を用意して、その文章と意味的に近い文章と遠い文章を用意して、近い文章同士は近づけて遠い文章同士は遠ざける、という学習をしています。
今回はバージョン1とバージョン2の2種類のデータセットを作って、大規模な事前学習を最初に行いました。
◆性能向上の工夫
加えて、追加で3段階目に行った工夫がモデルマージで、複数のモデルを複合する、パラメータを平均するみたいなことをすることで性能が上がるという手法です。
今回、事前学習の時に2種類データセットを用意してそれぞれで学習したので、これをモデルマージしてマージ済みモデルというのを作りました。実はこれがビックリするくらい効いて、ガッと性能が上がっています。
正直、技術者的には深層学習みたいな複雑なモデルのパラメータを平均するというのは、めちゃくちゃなことをやっているようにしか思えないんですが、ものすごい上がるということで非常に面白い結果になったと思っています。
最後にファインチューニングをしました。これも基本的にやっていることは同じで、近い文章と遠い文章を用意して、近い文章は近づける、遠い文章は遠ざける、というのをやったんですが、より高品質なデータを利用して学習するというところで違いがあります。
これはちゃんと結構効いていて、特に検索タスクでさらに性能が向上しました。
その他細かい話ですが、追加の工夫として、データフィルタリングとprefixの導入というのをやっています。
データフィルタリングは、リランカーというモデルを使って品質の低いデータをカットすることによってデータ量を落としているというものになります。品質の低いデータだけをカットしているので、学習のために必要なデータ量を減らしつつ、より高品質なデータに絞っているという処理になっています。
もう一つはprefixの導入というもので、モチベーションから説明すると、何かしら文章を検索しようというときに、ウェブページでも社内文書でもいいですが、ユーザーが書く検索のときのクエリ文章と、実際にヒットして出てくるような文章というのは結構傾向が違うと考えられます。
この2つに非対称性を導入することが重要というのは結構昔から議論としてあって、今回は非対称性を導入するために、クエリに対してだけ「次の文章に対して関連する文章を検索してください」というprefixを付与しています。
これを入れることで、検索タスクにおいてクエリの方だけちょっと違う埋め込みの傾向が生成されると思っていて、この非対称性の導入によって、クエリと検索対象のドキュメントの間の傾向の違いが吸収できると考えています。
実際、このprefixを入れた方が検索タスクの性能が上がりました。 ちなみに今回はベースモデルがLLMなので、自然言語でprefixを書いています。
◆まとめ
ここまでLLM2Vec、事前学習、モデルマージ、ファインチューニングという、ちょっと複雑なことを説明してきましたが、それらを使ってPLaMoのモデルを優れたテキスト埋め込みモデルとしてチューニングすることができて、日本語埋め込みとしてトップクラスの性能を達成しました。細かい部分はTech Blogを読んでいただけると幸いです。
特に検索タスクで優れた性能を示しています。 それに関するブログを書いてくれている人も結構いて、その辺はよく見ていてすごい嬉しいなと思っています。
これ自体はオープンモデルなんですが、PFNではこのPLaMo-Embedding-1Bをいろんなお客さまにご紹介して、社内データを使ってチューニングするとか、そういったことも含めて今後ビジネス的にやっていきたいと思っているので、ご興味があればぜひご連絡いただければと思います。
https://www.preferred.jp/ja/contact/
また、PFNでは、LLMやその周辺分野の研究開発を引き続き進めていきます。テキスト埋め込みモデルだけでなく、こういうLLM全般に興味がある方がいたら、一緒に開発する仲間も募集していますのでぜひ応募していただけたらと思います。

