Vol.40 番外編 PreferredAI Insight Scanのご紹介
PreferredAI Insight Scanの紹介をさせていただきます。プロダクトマネージャーの河村です。
◆開発背景
インサイトスキャンはテキスト分析を行うツールです。
テキスト分析においては昔から色々ツールがありますが、インサイトスキャンは生成AIを活用して分析します。

テキスト分析って、大量のデータをどういう風に柔軟に分類・分析するかというところが結構難しいタスクなのかなと思っています。
そこで、生成AIを使って良い分析をしましょうというのが、このインサイトスキャンのやりたいことです。
テキスト分析というと、昔から古典的な自然言語処理が行われてきたと思うんですけれども、最近の生成AIだと、より人間的な読み方ができるというのが特長で、インサイトスキャンはまさにその特長を十分に活かしたツールになっています。
◆従来手法との比較

インサイトスキャンの特長としては、「定性データと対話する」と書いてあるんですけれども、まさにチャットのような形式でデータと対話をしながらインサイトを発掘できるというところです。
ただのチャットではなくて、テキストデータ全体の文脈を深く理解した上で、「分類ラベル」というものが提案され、その分類に応じて「データの掘り下げ」とか「分類の修正」を指示して、分布や傾向を見ることができるツールになっています。
非常にシンプルなツールなんですけれど、様々な業務に活用できます。例えばレビューの分析であったり、特許の分析、あるいはコールセンター応答の分析だったり、様々なところでご活用いただいています。
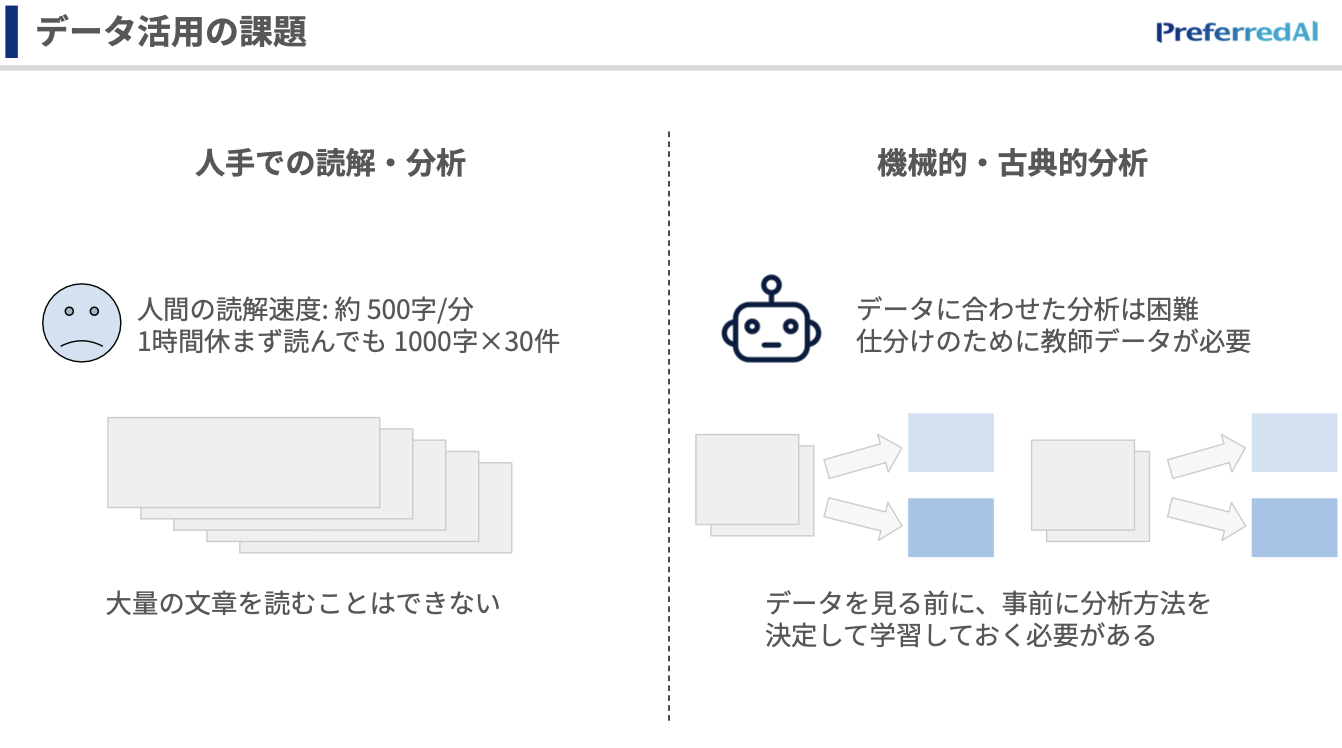
まずはデータ活用でどういった利点があるかといったところから紹介をさせてください。
左側に書いてあるのは、人手での読解・分析で、人が読むとどのくらいの速さで読めるかというと、大体1分あたりに500文字ぐらい読めるという風に言われています。
1分あたり500文字1時間ずっと読み続けられる人ってなかなかすごい人だと思うんですけれども、実際その大量の文章を休まず読むことって難しいのかなと思います。
一方で古典的な分析ですと、分析の内容を事前に決めなければならなかったりします。つまり、例えばセンチメント分析(ポジティブやネガティブに分けるなど)ができたとしても、そのポジティブの中で何に言及してるんだろうっていうのを1つ1つ見ていくみたいなことは、結局最後は人が目で見なきゃいけなかった、というのがこれまでの分析かと思います。

インサイトスキャンは、この2つのいいところを取れるというのが大きな特長で、「人のように自由な軸で分析をすることができる」というところと、「機械のように休まず高速に分析ができる」というところです。
機械で分析をしているとなかなか人と同じようなインサイトが得られないという課題を、このインサイトスキャンで解決できる、というアプリケーションになっています。
◆インサイトスキャンの活用事例

例えば、こちらは温泉宿のユーザーレビューを分析した例です。
左側のように「体験に絞って分析してください」と指示すると、フィルターで一部のデータに絞ってさらに分析を行うことができます。
また、右側のように、「これは知っているのでそれ以外を挙げてください」という指示で残っているタスクを抽出したりといったことができます。

こちらはコールセンターの例です。
コールセンターのデータを入れて、その中で電話の中で最終的に問題が解決したものと解決しなかったものを抜き出して、例えば解決しなかったものを別の処理につなげたり、あるいは、その処理の結果を使って、大体どのくらいお客さんが満足しているのかを分析したり、そういったことができます。

こちらは特許分析の例です。
様々な知財のデータを入れていただいて、例えば自社が出願予定の特許について、これと該当するもの、関連するものがどのくらいあるかというのを検索したり、あるいは、自社と競合他社の特許を入れて、自社が得意としてるところ、苦手としてるところを一覧で可視化したり、こういったことができます。

実際、この特許分析はNTT西日本さんに既にご活用いただいておりまして、元々人が1つ1つ特許を見て、「自分たちがどういうところで強みを持っているのか」というのを分析していらっしゃったと伺っているんですけれども、それを3時間程度で数1000件単位で分析が行えるということで、大規模のデータを高速に分析できるというところに強く共感をいただい ています。
◆インサイトスキャンのデモンストレーション
ここからは、実際にインサイトスキャンがどのように動作するのかというのを見ていただければと思います。

こちらの画面は、インサイトスキャンの実際のアプリケーションです。例えば、こちらに先ほどお見せした温泉宿のレビューデータを入れてみたいと思います。
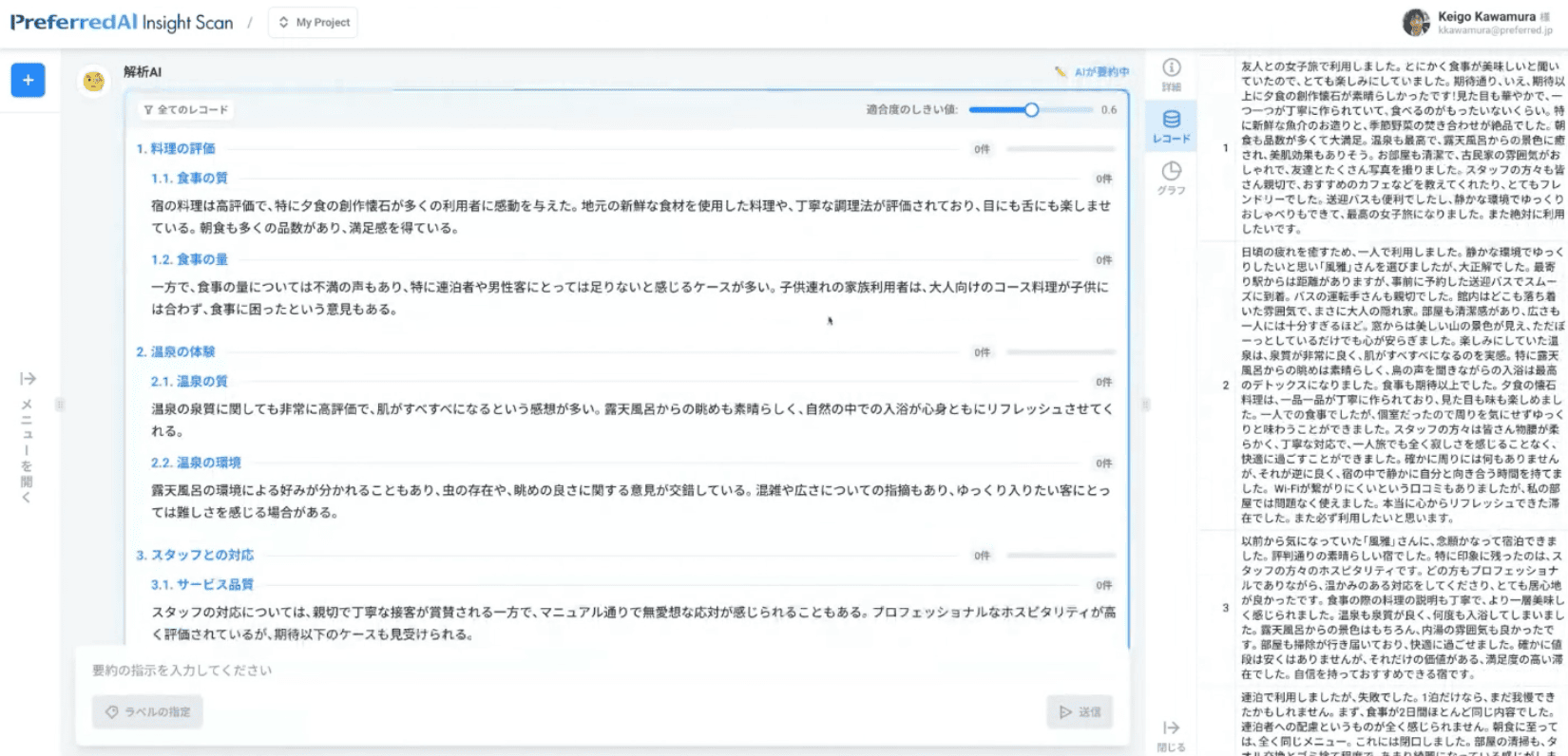
ここに100件のレビューデータが表示されています。100件全部読むのはなかなか大変かなと思うんですが、今実際にインサイトスキャンが高速に読んで中身を分類してくれています。
で、要約が表示されたんですが、例えば「料理の評価」とか「温泉の質」というところに「いったい何人が言及してるのか」という分析が行われます。全体でも30秒程度で分析が終わります。
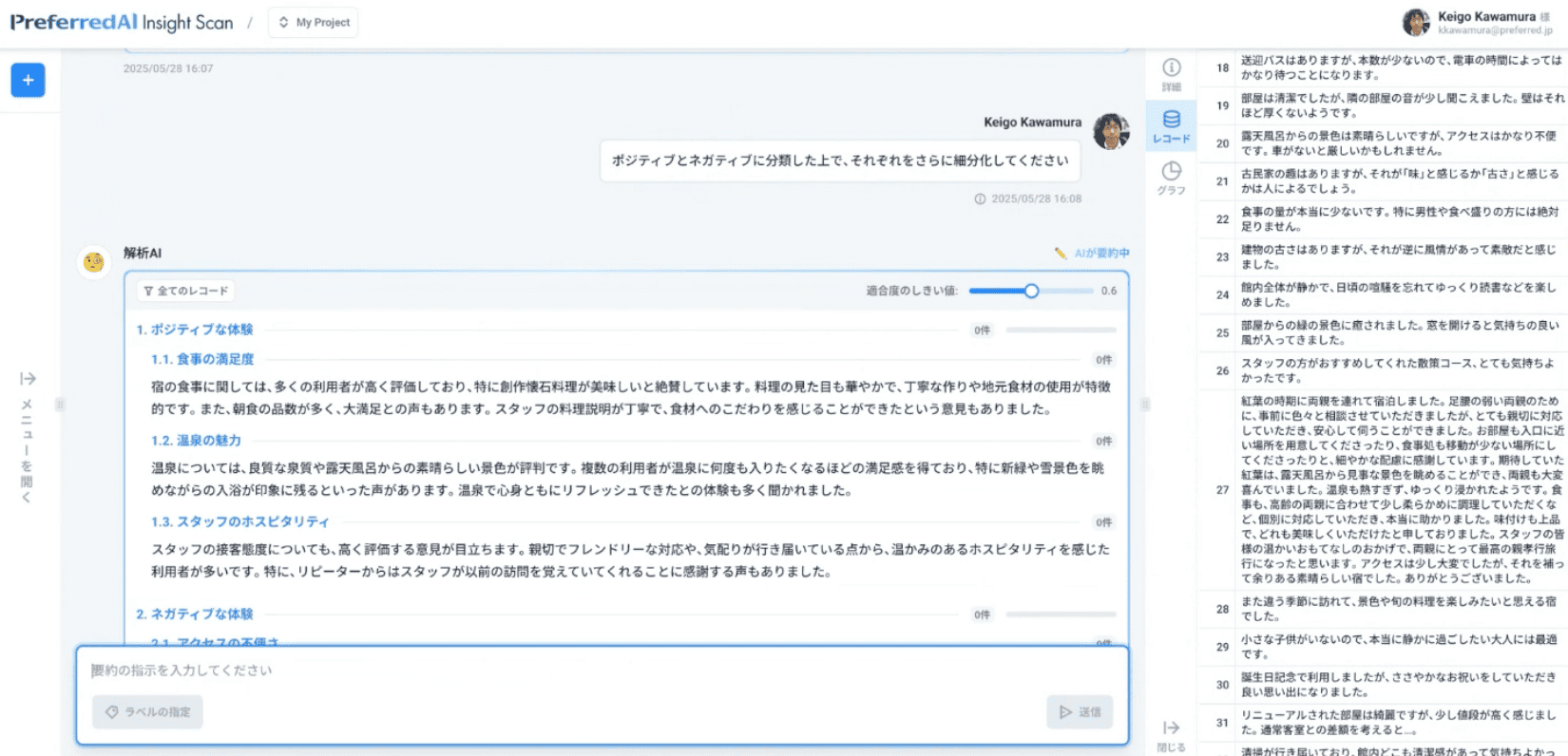
例えばここで「ポジティブとネガティブに分類した上で、それぞれをさらに細分化してください」と、このように事前に決めたものではなくて、今この場で思いついたものなんですけれど、自分がどのようなことを見たいかをそのまま入れていただくと、生成AIがデータを読んで、この内容に即したような結果を出力してくれます。
このように、インサイトスキャンが目指すことというのは、まさにデータと対話をして、データの中に対して「もっとこういうところが見たい」というところをどんどん深掘りできるようになることです。
生成AIというと、生成の部分に目が行きがちかなと思うんですけど、実は読解も得意だというところで、人がこれまでやってるような「データを読む」というところをAIに代替してもらえるのかなと思っています。
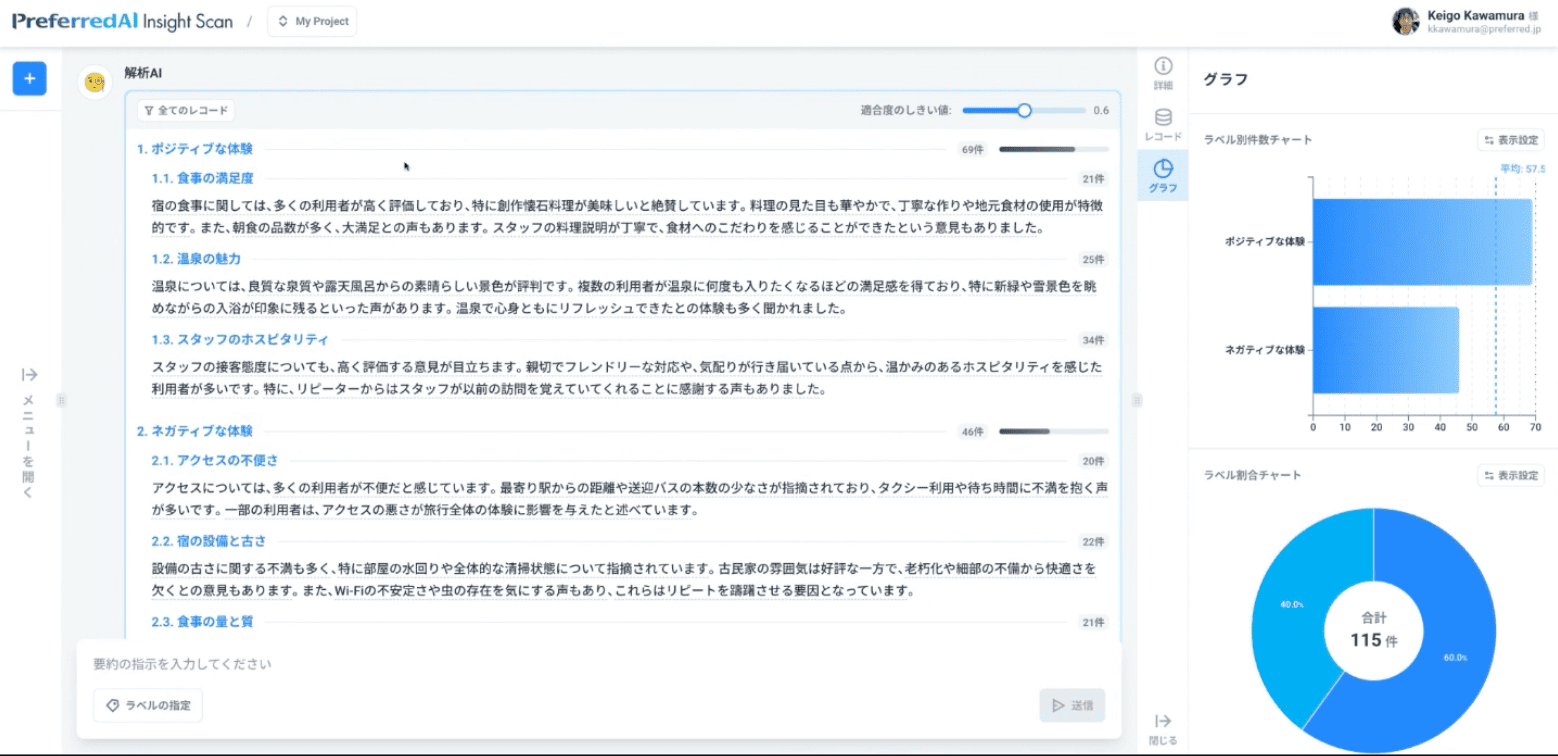
で、実際に要約が終わりまして、ポジティブな体験、ネガティブな体験というところでデータの分類が行われました。これを見ると、ポジティブとネガティブそれぞれありつつもポジティブの方が若干優位かなというのが、このグラフを見ても一目瞭然です、というのが分かります。
ちょっと別の例も試してみたいと思います。
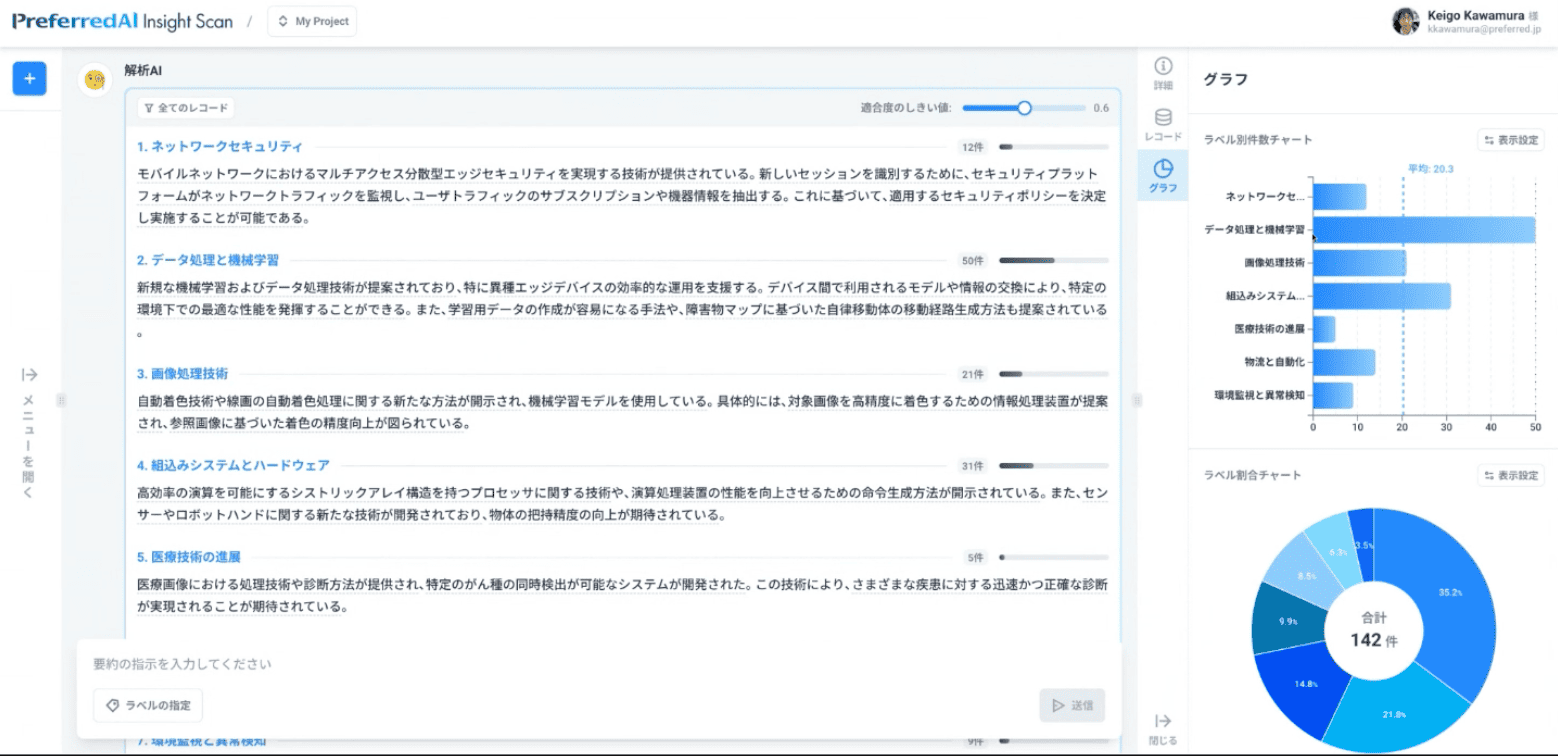
知財の例を入れてみたいと思います。今こちらに入力したデータは、弊社Preferred Networksの特許一覧なのですが、私たちがどういうところに取り組んでいるかがこちらに出ております。
かなり多いデータを入れているんですけれども、素早く全体の分析が行われます。弊社は機械学習をやっている会社なので、機械学習のデータが多くなっていますが、実はそれ以外のところも色々とやっています。
例えば「画像処理技術」や「組み込みシステム」など、こういったとこも実はやってるんですね、というのが分かったりします。
◆まとめ
私たちの作っているインサイトスキャンというアプリケーションは、様々なテキスト分析が行えます。
「分類ラベルを提案してそこに分類する」という基本的な機能の中で、例えばデータの掘り下げや、分類の修正、結果の一覧表示であったり、あるいは非常に長い文章であっても全体を高速に分析ができます。
加えて、その生成結果の共有、入出力のAPIの対応などもしています。

