Vol.41 学習したLLMを直接編集する
ICLRという学会でベストペーパーをとった研究の紹介をしたいと思います。
◆ICLR学会の概要と注目論文
ICLR (International Conference on Learning Representations)とは何かというと、AIの学会です。今AI関連で大きい学会が3つありまして、NeurIPSとICML、そしてもう1つがこのICLRという学会が、多くの人が認める三大学会になります。
それぞれちょっと違う個性を持っていて、ただ大体4ヶ月おきに分散されているので、大体1年間に3回ぐらい、AIの研究者とかがここで採択されるのを目指して研究成果を発表しています。
ICLRという学会は、比較的Deep Learningに寄った学会で、LRの部分がLearning Representation(表現学習)に関する学会って言ってるぐらいなんですが、今年は特にDeep Leanring、特にLLMなど生成AIに寄った特徴がありました。
ちなみに、NeurIPSもそうなんですが、ICLRの大きな特徴は、査読内容が全部公開されているということです。お互い匿名化された上で誰がどのような評価をして論文を採択したか、採択されなかったかが見られるようになっています。論文自体より査読でのやり取りを見るほうが価値がある場合もあるくらいです。
あとは、例えばPaper Copilotっていうサイトで、公開されている学会の情報を誰かが統計情報にして、どれが何点ついてるかっていうランキングがあります。
採択される前の段階から、どういう論文がどう評価されてるのかが見られるし、何点ついたものが落ちているとか受かっているとかも見られます。自分も実際これの上位多分500本ぐらいはAIの力も借りて目を通しています。

例えば、今PFNと共同研究している宮戸さんの研究(蔵本振動ニューロンを使ったもの)がランキング7位に入っているのが見えます。これでわかるとおり、めちゃくちゃ論文が出ていて、大体12,000本の投稿があって、そのうち3,700本が採択されると。
その採択されたものの中でも、ポスター発表できるものがデフォルトなんですけれど、その中でスポットライトっていうもので選ばれるのがそのうちの1/10で、さらに、その中の1/3がオーラルって言って15分くらいの口頭発表ができます。
そして、その中でさらにベストペーパーに選ばれたのが3本で、重要な論文だろうということで読みまして、面白かったのでそれを一部紹介したいと思います。
ちなみに選ばれた論文はほとんどLLM関連で、これでもかっていうくらいLLMばっかりになっています。
◆AlphaEdit:LLMの知識を更新する新手法
ベストペーパーの1本である、AlphaEditという論文に関してです。
LLMって学習が終わった後に何か新しい知識を入れたいということがあります。LLMの知識が古かったりして修正したいなと。
例えば「PFNが設立されたのは2000年です」とか誤って答えていたら、「いやいやそれは2014年だから直したいです」っていう場合、今だと方法としてはコンテキストにくっつけるか、もしくはファインチューニングで覚えさせるみたいなことをする必要がある。
一方、1個ぐらいの知識だったらいいですが、ものすごいたくさん修正する場合、毎回コンテキストに入れると大変だし、ファインチューニングの場合も入れたとしても本当に修正できるかって言うと修正できなかったり、もし修正ができたとしても大抵ファインチューニングすると他に悪影響があって、前あったいろんな知識が壊れてしまうとか、そういう現象が起きちゃうという問題がありました。
このAlphaEditというのは、直接LLMのパラメータをいじって、新しい知識を覚えさせることができるような方法になっています。
分かる人は分かる、分かんない人は分かんないっていうレベルでちょっと1回詳細を説明します。
知識を入れようという場合、ここで言ってる知識はキーと値のペアで表されます。一種の連想記憶です。
例えば先ほどの「PFNが設立されたのは2014年です」っていうのは、キーが「PFN設立」で値が「2014」っていうのを入れたい。
で、それをパラメータのところにバコっと「PFNの設立」を入れたら「2014」というのがポンと出てくるようにLLMのパラメータ(MLP層のパラメータ)を修正するんですが、その際に先ほど言ったように問題になるのは、入れること自体は簡単なんですけど、入れてそのパラメータが変わると、無数の過去覚えたところに影響が出ちゃって、それらも干渉して他の記憶が間違ったり、忘れたり、最悪壊れちゃうっていうことが起きます。
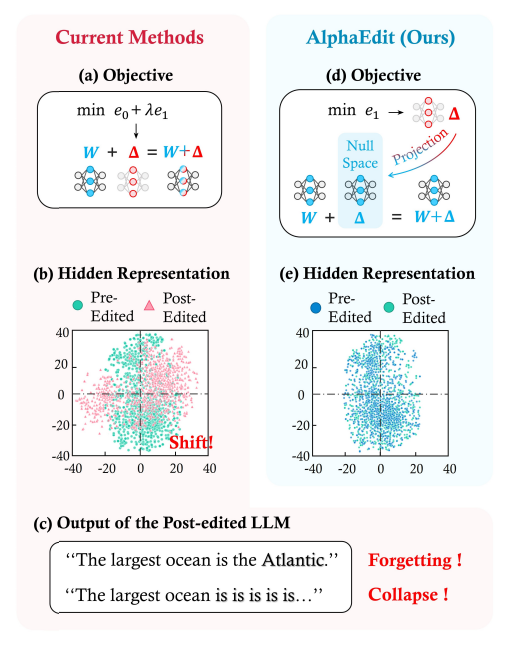
それを防ぐためにどうやるかっていうと、このAlphaEditでは、元々のニューラルネットワークのパラメータが表す線形関数には、零空間とよばれるような入力の部分空間があることを利用します。
これはある行列に対し、その行列と掛けたときに0となってしまうようなベクトルの集合となるような部分空間です。
そこで記憶としては壊したくない「これは重要だね」って思った記憶の集合を100万個ぐらい用意しておいて(大抵Wikipediaだとか自分が覚えておきたいもの)、そこのキーと値のペアから構成される行列を作ります。
そして、それに関する零空間を求めておいて、新しい情報を入れたいなと思った場合には、その情報を入れるために必要なパラメータの更新分をこの零空間に射影したものを計算して、その射影した空間の中だけでアップデートするということをやります。
そうすると、既存の重要な知識を全く(「全く」は言い過ぎなんですが)影響しないで、知識を直接入れることができる、というのがこのAlphaEditという方法になります。
今言った零空間とか、アップデートする式は全部、行列演算を計算するだけで解けますので(ニューラルネットワーク全体を使ってバックプロップして何か計算するとかしないで、1回計算して重みに書き込む形で解ける)、簡易に処理することができます。
新しい知識をちゃんと入れられて、今までの知識を壊さないでできますよっていうのがこのAlphaEditです。
◆補足コメント
これは実用的にも興味深いんですが、一方で、これは各MLPブロックの特に最後の層だけをいじっていて、他のパラメータを全くいじっていません。そして零空間として調整可能な領域っていうのはたかが知れているんですね。
本当は複数層とか非線形の部分を活かして、値が潰れる零空間っていうのはもっとあるはずで、そういった制約を考えると、もっとたくさん情報を入れても、過去の記憶を壊さずに済むとかはできるだろうっていう話はあります。
あと、既存の情報を入れた時に出力が全く変わらないっていう保証付きのところで、他の値を変えるっていうような話は、実は対称性とよばれる数学の概念とも通じます。
対称性とは変換をかけた後でも前後でも値や性質が変わらないというように定義されるのですが、今回も、記憶を追加した後でも既存の記憶は変わらずに保ってほしい問題を解く問題です。そういったところでは、対称性で使われている技術が応用できるかもしれない、と思います。
これもある程度分かる人だけ向けにちょっと話す、例えばニューラルネットワーク全体の対称性としてある入力に対して不変な部分空間を求めることができることがわかっています(リー代数微分)。そうした方法を応用することはできるのではないかと思っています。

