Vol.44 ProRL(長期強化学習)によるLLM推論能力の強化
ProRLという、強化学習を使ってLLMの推論能力を改善する研究についての紹介です。
◆LLMにおける強化学習の現状とProRLの位置付け
LLMを学習する際に、まず人間が書いたたくさんのテキストデータを元に事前学習をして、その後にLLM自身が、強化学習と呼ばれる、自分で試行錯誤をして、その結果が良いかどうかを外から「あ、これいいですよ」や「これだめ」っていうフィードバック(報酬)をもらったら、それを元に改善していくことができます。
このアプローチでやると、人が作ったデータなしに自分で勝手に賢くなっていくぞというのを、去年OpenAIのo1とか、DeepSeekのR1が初めて成功させて、その後いろんな人が追加実験をたくさんやったんですけど、なかなか結果が安定していません。
最近でもかなり否定的な結果がたくさん出てきています。例えば、ランダムな報酬を入れても(LLMが出した結果に対してでたらめな判定をフィードバックしても)性能が上がるという論文が出たりして。
その場合だと、強化学習が能力を引き延ばしてるんじゃなくて、事前学習の時点で獲得していた能力を引き出してるだけじゃないか、しかも引き出すには別に正確な報酬が必要ないんじゃないか、というようなことが出たりしています。
毎週、いいんじゃないか悪いんじゃないかって揉めているんですけれど、5月30日の時点で出たこのProRLの論文は、ポジティブな方向でいいんじゃないかと言ってるものの最新結果です。
◆従来を超える大規模な強化学習
具体的にProRLでは何をやったかというと、まず、強化学習をする際には外から報酬が必要なんですが、検証可能な報酬ということで、基本的には数学だとかプログラム、例えばプログラムだったら「書いたコードが作ってあるテストを全部通るか」とか、数学だったら「ちゃんと数学の答えが出るか」だとか、そういったもので評価します。
ProRLの場合、5種類のかなり大規模な問題設定を用意します。それを使ってこれまでにない規模の学習をしています。
具体的には、(モデル自体は小さくて1.5Bなんですが)1.5Bモデルを2000ステップ学習します。
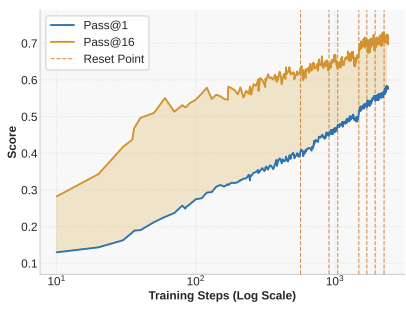
この2000ステップがどれぐらい大きいかというと、従来の研究だと数百ステップくらい。
そもそも全体の学習規模がどれくらいかって言うと、事前学習で2T(テラ)トークン、1.5Bで学習した場合に比べて、この2000ステップで強化学習した場合は、その半分ぐらいの規模になります。
つまり事前学習にかけている計算量の半分ぐらいの計算量を投入して強化学習が実行されています。
そして、上記のグラフはトレーニングステップ数を示していて、学習すればするほど性能が順当に上がってスコアも上がり続けます、という結果になっています。
◆ProRLの技術的工夫
これだけ長い時間学習させると、たくさん工夫しないといけなくなります。
例えば、通常強化学習をする場合、事前学習の時に得られている元のモデルから離れていってしまうと事前学習のモデルを忘れたりするし、最悪完全に壊れたりするので、できるだけ元のモデルから離れないようにする、というような正則化を入れて学習するんですが、それがあると、逆に結局元のモデルからそんなに離れられないという話があります。
上記のモデルでは、縦の点線がリセットポイントで、ここまでは元のモデルと同じだけれど、リセットポイントの時点を新しい基準にして、そこからまた一定の距離で学習するという風に、基準となるモデルを一定間隔ごとにリセットする。そして、ここで最適化の状態もリセットしています。
◆多様性と創造性:性質向上の鍵
あとは、結局強化学習が何をやってるかと言うと、モデルが複数個の解を出して、その中でたまたま正解にたどり着いたものがあれば、それが「良かったね」ということで、次からそれを選んでくださいっていうアップデートをするので、そのたまたま正解を選べるような出力を出せる多様性が必要になります。
このたまたま出るようにする部分が、生成の際の確率温度(温度を高くすると一様分布に近づく)を高くする必要もあるし、さらにはモデル自体が事前学習時に見たデータとは違うデータも出せるようにするっていうのもあって、そういうのを促進します。
うまく事前学習のデータとは違うデータをちゃんと自分で出せるようになっていると、性能が上がるっていうのも測れます。
それを、彼らは前の研究で「創造性指数」と言ってるんですが、つまり事前学習で見たデータじゃないようなデータをモデル自身が出せる能力っていうのが、強化学習でどれだけ伸びるかと強い相関があるということも分かっています。
これぐらいのところまで来ると、結構もう人間っぽい話になってきます。
この場合だと、LLMがどれぐらい変な考え方も許容できるかっていうところになっていて、その変な考え方の中でいいやつがあったらそれをちゃんとピックできる仕組みがあれば能力はガンガン上がっていくし、いくら賢くても、あまり多様性がなくて常に同じ答えしか出さないやつだったら能力が伸びないっていうことで、そういったところは直感的にもかなり人間とか人間社会とか組織でも同じだなってことを思いました。
◆感想と考察
この辺が論文の結果なんですけど、感想としては、まず、これがまだ限界が見えていないので、もっとモデルとかデータを増やしたらさらに賢くなっているし、実際のフロンティアモデルではこれがもっと進んでるのかもしれない。
2つ目は、(これをやってるのはNVIDIAなんですが、)事前学習がデータ量がもう枯渇してこれ以上大きくならないって言われている中、一方で、この強化学習でまだまだ性能伸びることが示されて、しかも事前学習と同じぐらいの規模の計算力を使うことになると、まだまだ計算力が学習の方でも、能力伸ばせるんだろうなと思いました。
あとは、先ほどあった「創造性」って言ってる部分、その多様性みたいなものをどうやって狙って起こせるのかっていうのはかなり難しい話で、今は単純に温度上げるぐらいですが、もうちょっと狙って起こせるのかなとかは気になりました。
違う複数のたくさんのモデルを抱えていて、それで遺伝的アルゴリズム的に改善するとかは一つ簡単に思いつきますが、他にも色々あるのかなと思いました。

