Vol.49 画像特徴量計算の最新モデル DINOv3 解説
今日のトピックは「DINOv3」で、これは何かというと、「画像の密な特徴量計算の最新モデルの話」です。
言語モデルは、言語に関する基盤モデルとして、テキストを入れたら何でもいい感じにその後のタスクに使えるような良い特徴量を生み出すことができます。
一方、画像の方では、何でも使えるような特徴量を出すというのが、言語モデルに比べて汎用性や性能の面で遅れています。これに対して、このDINOというシリーズが、徐々に広いタスクで使えるようになってきています。
◆DINOv3の驚異的な性能と多様な応用例
具体的には、画像を入力すると、上記の右側にあるような各画素の位置ごとに特徴ベクトルというのを出します。
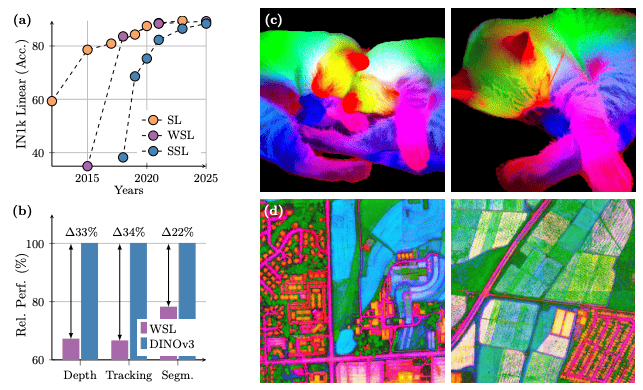
その特徴ベクトルがその後色々なタスクに使うことができて、例えばセグメンテーション(意味のある領域ごとに分ける)とか、ロボットピッキングタスクだったら掴めそうな場所の検出をするだとか、深度推定(深さがどれぐらいあるか)とか、色々なその後続タスクで、この特徴量を使って簡単な線形分類器とかを作ってやるだけで、ものすごい精度が出るようなものになっています。
実際に、上記の右側で見せているのは、DINOを使って各画素ごとに特徴ベクトルを出した後に、(ベクトルなので人には分からないので、)高次元のベクトルをPCAし3次元に落として色付けをしてあげていて、人間も直感的に理解できます。
これがどういう意味なのかというのは説明しにくいのですが、猫だったら猫の境界を完璧に捉えていて、耳だったら耳の部分、手の部分はこんな感じで捉えているし、少なくともその特徴ベクトルが色々な情報をかなり正確に理解しているというのが分かります。
同様に航空写真の場合でも、普通のRGB画像を入れると、かなり綺麗に、これだけでも使えるレベルのセグメンテーションができるようになっています。
あとは単にこれに、例えば農作物が取れそうな地域とかを、いくつか正解のセグメントの教師データを作っておいて学習させると、非常に少ない量のデータでも精度が出るし、さらに汎化もすると。
このDINO自体はものすごい量の色々な種類のデータで学習しているので、そういったことができます。それ以外にも、例えば深度(画素ごとにどれぐらいカメラからの距離があるか)とか、トラッキングだとか、そういったタスクでも高い性能を出すことができている手法です。

他にも、こちらも印象的な結果で、上記のようなめちゃくちゃ色々な種類の野菜とか果物が混在して置かれているような画像に対して、例えばこの左側のここの赤色の矢印が付いているところに対して特徴量を取って、その特徴量と単に似ている特徴ベクトルを(コサイン類似度などで)取り出すと、ちゃんとここの領域が取れます。
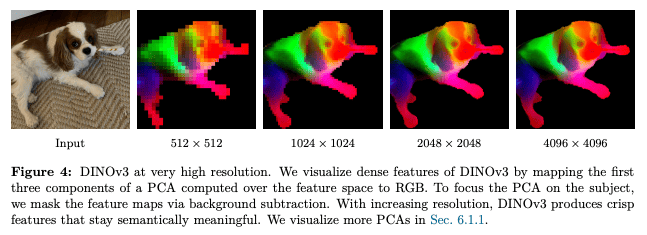
他にも今回のDINOは高解像度の4Kの画像にも対応しているし、トラッキングとか、そういったタスクもできます。
一番簡単な画像全体の分類タスクみたいなものも、このDINOを使った結果をそのまま線形分類器に入れると、ImageNetの分類タスクとかでほぼ上限に近いような性能が出るようになっています。
◆自己教師あり学習によるDINOの構築
DINOv2もかなり広く使われていたので、もう知っているよという人も多いかと思うのですが、今回のDINOv3はDINOv2を改良しています。
では次に、これをどうやって作るかという話をします。 今説明したように、この手法は自己教師あり学習で、正解データを全く使わずにやっている手法になっています。
もともとこういう画像の特徴量学習は、教師あり学習(Supervised Learning, SL)、弱教師あり学習(Weakly Supervised Learning, WSL)、自己教師あり学習(Self-Supervised Learning, SSL)とあった場合に、ImageNetの分類問題の精度で見ると、もともとは教師あり学習をたくさんやって、それで得られた特徴量を使うというアプローチでした。
けれども、やはり学習データが少ないとか多様性がないとか、そういった問題があるので、SSLが良いねという話はあったのだけれども、難しかったと。
それが2017年ぐらいに提案されてから、獲得された特徴量を線形分類にかけて分類タスクで評価した場合に関して言えば、ぐわーっと性能が上がってきて、ほぼ教師あり学習と変わらないぐらいの精度になっています。
DINOが自己教師あり学習でどういう方法で学習しているか、手法の方から説明します。
この自己教師あり学習は大きく2つの目的関数を使っていて、1つ目は、まず画像をパッチに分割して、いくつかのパッチをマスクして、残りの生き残ったパッチから、その消したパッチが何だったかというのを推定するタスクというのが、1つの目的関数になります。
例えば、人の顔が映っていて、半分ぐらい消えていて、目の部分を復元しようと思った場合には、ちゃんとこれが顔の構造だよというのを認識して、推定する部分が目の部分だということを理解していないと復元できないので、そこで復元に有効な特徴量を学習するようになっています。
もう1つが、イメージレベル、画像全体の目的関数で、これは、画像全体から計算した特徴量と、それぞれの部分の特徴量が合うように学習をするようになっています。
この2つを組み合わせるのがすごく重要で、画像全体の情報は、例えば画像分類(「画像全体に写っているのは犬ですか」など)のタスクに役立つような特徴を獲得できますし、一方で先ほどのパッチレベルの推定の方だと、画像の局所情報(ある一部分の情報をちゃんと取り出して)の推定をできるようにするという観点で特徴を獲得すると。
この2つの学習目標を同時に最適化するようにどんどん学習していくというのが、DINOv2ぐらいまでのアプローチでした。
◆DINOv2の課題とDINOv3の解決策「グラムアンカーリング」
しかし、DINOv2でどんどんモデルを大きくしていくとうまくいかないというのが分かりました。言語モデルの場合は大きくしていけばとにかくうまくいっちゃうので、そういうのが起きなかったのですが、画像の場合はこういう問題があるので、なかなかスケールがうまくいっていませんでした。
どういう問題かというと、全部の特徴量が似通ってきてしまって、特徴ベクトルが縮退(collapse)します。
先ほどパッチごとに分けるという話があったのですが、とはいえ、各特徴量を同じ方向にしていくというのが簡単な改善できる方向なので、どんどんそっち側になっていって、それによって全部の位置の特徴が同じような情報になってしまう。
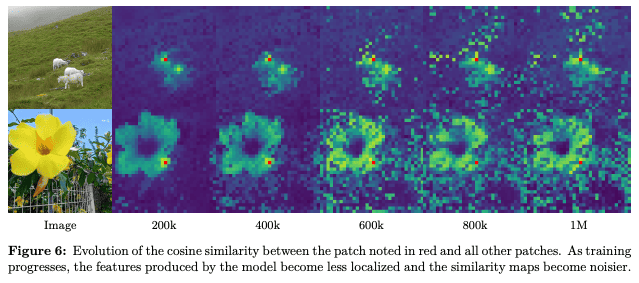
例えばこの羊の例だと、学習初期はちゃんと羊の背中を取って、「それと似た特徴ベクトルは何か」というのを見ると、似た羊のところだけが反応するのですが、ずっと学習を続けていくと、羊と全く関係ない色々な場所も、どんどん似たような特徴量を持ってしまうという現象が起きてしまいます。花の場合も一緒です。
これに対して、「グラムアンカーリング(Gram Anchoring)」という手法を提案しています。
この手法自体はオリジナルではなく、昔使われていた手法ですが、学習初期の時点での、各パッチ間で「どのパッチとどのパッチが似ていたか」という情報、類似度行列をターゲットにして、初期の時のものをずっと持っておき、これに学習後半もずっと合わせるようなことをします。
これによって、自由度としては各特徴ベクトルは似ていると言っても、かなり色々な方向でまだまだ変えられるのですが、「これとこれは似てなきゃいけないよね」という制約が最後まで残ることによって、劇的に特徴の品質を改善することができています。
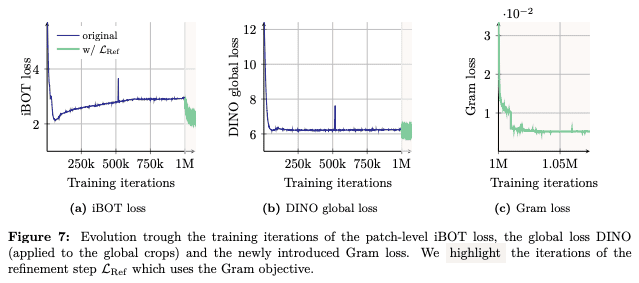
ある画像認識タスクを見た時に、学習を進めていくと損失があるところまで一回下がるのですが、そこからどんどん悪くなっていったのが、この損失を導入したら、すぐにガクッと改善されるということが分かっています。これを学習中にずっと入れるという工夫をしています。
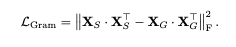
計算式で書くと上記のような感じで、学習初期の特徴量の類似度行列、「どのパッチとどのパッチがどれぐらい似ていたか」というのが入っている行列をターゲットにして、今の行列が合うようにというのを損失として加えるという工夫をしています。
◆事後学習による実用性の向上
これは最近のLLMの話とかなり似ているのですが、色々な形で事後学習をします。
まず、解像度を学習中は256x256でやっているのですが、これを高解像度とか違うアスペクト比の画像も対応できるように、色々なアスペクト比に少し変えて学習をします。
この際には、必ずしも本当の画像を変えるだけじゃなく、画像パッチごとに位置埋め込みの情報があるので、そこの位置埋め込みの情報も色々いじって、色々な解像度に対応して、テストデータの時に初めて見る新しい解像度だとか、新しい縦横比の画像があったとしても対応できるようにします。
もう1つが蒸留(Distillation)。これは手法じゃなくて、その後の使い勝手の話ですが、蒸留もしていて、作ったモデル自体は非常に大きくて「性能は高いけれども使いづらい」ので、それを元に蒸留をして小さいモデル群を揃えています。

こういったことをして、色々なところに使えるようにしています。例えば、初めて見るようなオブジェクトの発見(Discovery)もこんな感じで、もうかなり正確にできたりします。
なので、画像認識みたいなところでは、結構重要なタスクが色々と自己教師ありで解けています。動画もフレームで切り出して、その特徴量と似ている特徴量を次のフレームから持ってくるだけでトラッキングできちゃうし、かなり簡単に色々な問題が解けちゃうというものになっています。

