Vol.54 なぜLLMはハルシネーションするのか?
今日は少し前に話題になったハルシネーションに関する論文です。
◆OpenAIによるハルシネーション問題の新たな分析
これはOpenAIが発表した研究でして、元々LLMを使った時に、ハルシネーションと呼ばれる「知らないことをあたかも事実のように言ってしまうという問題」がずっとあり、これを抑えられないかと、日々色々な方法で研究者が考えています。
そもそもハルシネーションがなぜ起きるのか、起きたとしてどうやって抑えられるのか、という研究は未だにずっと行われています。
GPT-5でだいぶハルシネーションが減ったと言われていると思いますが、まだ残っています。「なぜこれが難しいのか」というのをこの論文は紹介していて、これが答えではないけれども、かなり今までにない綺麗なまとめ方をしているので話題になっていました。
◆ハルシネーションを「分類問題」として捉え直す
ハルシネーションが起きない問いもたくさんあって、例えば有名人の出身地や誕生日といった情報は、ほぼ完璧に答えられます。
一方で、ハルシネーションする代表例が、有名な人の誕生日を間違えるというものです。例えば、この論文の著者の誕生日を聞くと、でたらめを、ものすごく確信を持っているかのように答えてしまいます。
誕生日に限らず、住所や本の名前など、色々なことをあたかも知っているかのように言ってしまう。
このハルシネーションという問題を捉えるために、著者らは、研究が進んでいる「分類」の問題に還元します。
生成というと色々ややこしい話があるのですが、LLMを「プロンプトを与えたら応答を出す確率モデルだ」と考えて、その確率モデルを分類器として使い、「与えられた文が妥当かどうか」を分類する問題設定を考えます。
ハルシネーションは、「分かりません」と答えればゼロに抑えられるなど、コーナーケースが多くて定義が難しいのですが、「妥当かどうか」を分類する問題だと考えれば、矛盾なく扱えます。
例えば、さっき挙げたような「(誰々)の誕生日は8月1日です」という文が妥当かどうかを判断させ、正しい組み合わせなら「妥当です」、めちゃくちゃな組み合わせなら「間違いです」と答える、という問題です。
◆ハルシネーションが発生する3つの原因
このように「妥当かどうかの分類問題」として見た時に、ハルシネーションが起きるケースは大きく3つに分類されます。

1つ目が、ハルシネーションが全く起きないケース(分類が簡単な問題)。「妥当かどうか」が、簡単で明確な基準で、綺麗に判定できる問題です。
例えばスペルミスで、正しい"Greetings"と間違いの"Greatings"は、誰が見ても明確に区別できます。学習データ中に正しい方は100万回出てくる一方で、間違いは1回も出ない、というようなケースは分類が簡単です。
2つ目が、モデルの能力不足で起きるケース(モデルが悪い問題) 。問題自体は綺麗に分けられるはずなのに、現在のTransformerモデルのアーキテクチャでは判断するのが難しい問題です。これはモデルが悪いということになります。
著名な例として、Transformerは「与えられた単語の中にあるアルファベットが何回出現しているか」という、人間には簡単な問題をめちゃくちゃ間違えます。これは、分類問題としては単純なのに、モデルの能力が追いついていないせいで起きるハルシネーションであり、モデルを改善すれば減らせるだろう、という問題です。
3つ目が、本質的に分類が困難なケース(パターンがない問題)。これが一番厄介な問題で、誕生日や住所などがまさにこの例になります。
これは、名前と誕生日の間には何の関係性もパターンもない、完全にランダムな組み合わせである、ということです。ある人の誕生日は8月17日だけど、ほとんど同じ名前の別の人は1月3日だったりする。
パターンがないので、分類器からすると、入力空間に「妥当」と「妥当でない」の点がランダムに混ざっているような状態を分類しなさい、と言われているのと同じです。
一応、超強力なモデルで、妥当な点だけを全て囲うような、めちゃくちゃ複雑な分類境界を作れば完璧に分類はできますが、これは事実上の丸暗記であり、汎化もしません。
◆理論的限界と現在の事後学習の課題
このように、LLMのハルシネーションに対応する能力は、「分類の能力で評価できる」というのがこの論文の功績の一つです。
具体的には、ハルシネーションの確率(妥当でないものを妥当だと言ってしまう確率)は、常に分類器が出すエラー率より大きくなる、ということが簡単な式で証明できます。
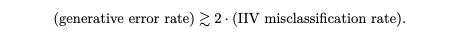
この式が示している重要なことは、分類が簡単にできないような問題は、そもそもハルシネーションを抑えられないということです。
ハルシネーションをゼロに抑えるのは、分類器のエラーをゼロにするのと同じくらい難しい問題だ、というのが一つ目の結論です。
2つ目に、事前学習の確率分布とは別に、事後学習で分からない問題だと想定される場合は答えないと指定することでハルシネーションを減らせる可能性はあります。しかし、現在使われている評価ベンチマークがこのようなアプローチをできなくしています。
例えばMMLUは4択問題で、他の多くも多肢選択問題です。その場合、モデルは「分かりません」と答えるよりは、少しでも当たりそうならそこに賭けて答えておく、という我々が試験でやるような戦略を取ってしまいます。
スコアを少しでも上げるためには、よく分からなくても何となく答えてしまう方が点数が上がるので、現在の事後学習はハルシネーション抑制に関しては、うまく機能していません。
◆解決への提言
ハルシネーションを測るベンチマーク自体はあるのですが、学習コミュニティの関心は、基本的にMMLUのような多肢選択問題のスコアを上げることに向いているので、ハルシネーションを抑えるのは難しい、というのが現状です。
そこで論文では、学習コミュニティに対して、多肢選択問題の場合でも「分からない」と答えることにインセンティブがあるような問題設計を行い、それをみんなで解くようにすれば、ハルシネーションは抑えられるのではないか、という提言をしています。
これを読んでの私のコメントとしては、ハルシネーション問題が3つのタイプに整理されて、上の2つ(分類が簡単な問題、モデルが悪い問題)はモデルの進化で解決できると思います。
一方、一番下の「丸暗記しないと解けない問題」は、多分、今の統計的機械学習の枠組みのままでは解けない問題になっています。こういう場合、人間はどうしているかというと「1回しかサンプルがなくてもそれを信用して丸暗記」しています。
そういう、「サンプル数が少ない場合に特別な扱いをして丸暗記する」というような(今の機械学習ではとらない)戦略をモデルに導入する工夫をすれば、解けるようになるかもしれません。あとは、ベンチマークを変えた方が良いという点については、その通りだと思います。

