Vol.55 画像とテキストの対比学習が生む汎用的な表現:Perception Encoderの研究
◆汎用的な画像表現学習の課題
今日の話は画像の話で、Perception Encoderという研究を紹介します。
これはNeurIPSのOral、つまりもっとも代表的なAIの学会に選ばれた論文のなかでも最も選抜されていたものでした。どういうものかと言うと、画像の表現学習です。
画像とか動画は生の画素値だと使えないので、それを何らかの特徴ベクトルに変換します。変換した後はいろんなタスクに使えるような、できればすごい簡単な分類器とか回帰で、できるようないい表現を作れる方法はないかと。
そういうのをずっとみんな考えているんですけれども、今までは画像の良い表現で何でも使えるやつというのが実はなくて、ある表現というのは、例えば言語には強い(画像からキャプションを生成したりだとか)、しかし検出とかセグメンテーションには弱いだとか、必ず何かしらの表現は、何かに特化していました。
◆画像とテキストの対比学習がもたらす汎用性
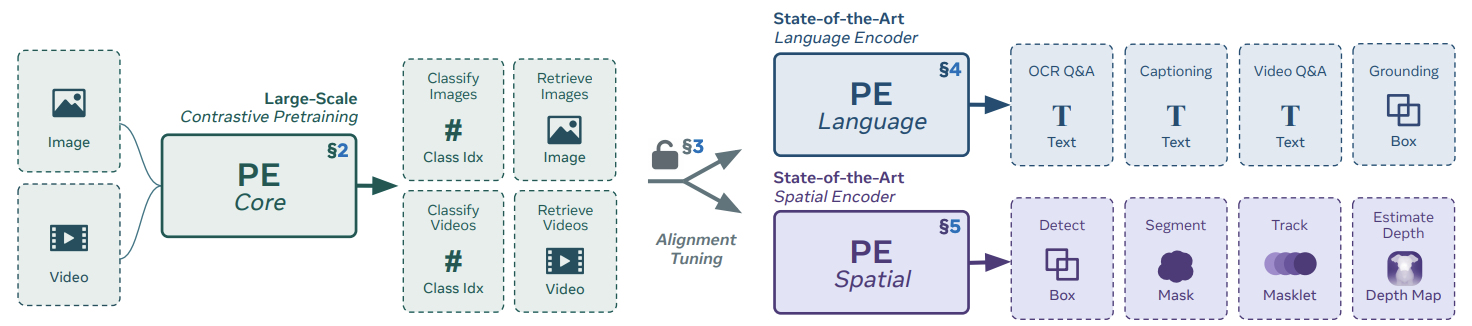
この研究は、画像とテキストのペアの対比学習をするのが汎用的な良い方法だというのと、さらに、そこで得られた最終層ではなく、途中のそれぞれの層で強みが違っているというのを見つけました、という論文です。
ある層は言語に強かったり、ある層は位置情報に強いような表現を持っています。実際、得られた表現は強くて、いろんなタスクで最先端の性能を出しています。
これは人間の対比でも面白いんですけど、人間も脳の中で、目から入ってきた情報が徐々に何層かで処理されていて、最初のほうは画素情報など生の情報に近く、途中で言語とかに紐づいて、最後のほうは画像全体の情報だとか、抽象的な情報になるんですが、そういったことがこのビジョンの変換モデルでも起きていたと。
◆対比学習と知識の取り出し方
もう少し丁寧に説明すると、まず画像とテキストのペア、動画だったら動画とテキストのペアをたくさん学習の際に用意します。
次に、画像とテキストをそれぞれエンコーダーで特徴ベクトルに変換します。その特徴ベクトルに変換したものが、同じペアのところの特徴は近くなるように更新して、違うものは離れるようにという、昔からずっとあるCLIPと呼ばれるような方法、いわゆる対比学習で学習をします。
つまり「単に似ている特徴は近づく」「違うものは離れる」というだけで、いい特徴が獲得できます。
◆途中層からの情報抽出
最後の層だと、今の学習の仕方だと、最後のさっきのテキストのエンコーダーの結果と合うようにする、となるんですけど、途中のいろんな情報は捨てられています。
途中層の特徴量を持ってきて、それが最後の層にその結果が出るように「最終層の表現と途中層の表現を合わせる」というような学習をします。
そうすると、途中で捨てられた情報が最後まで生き残って、その最後の層を使うと、例えば、分類だとかOCRだとかビジュアルQA、グラウンディングとかに使えます。
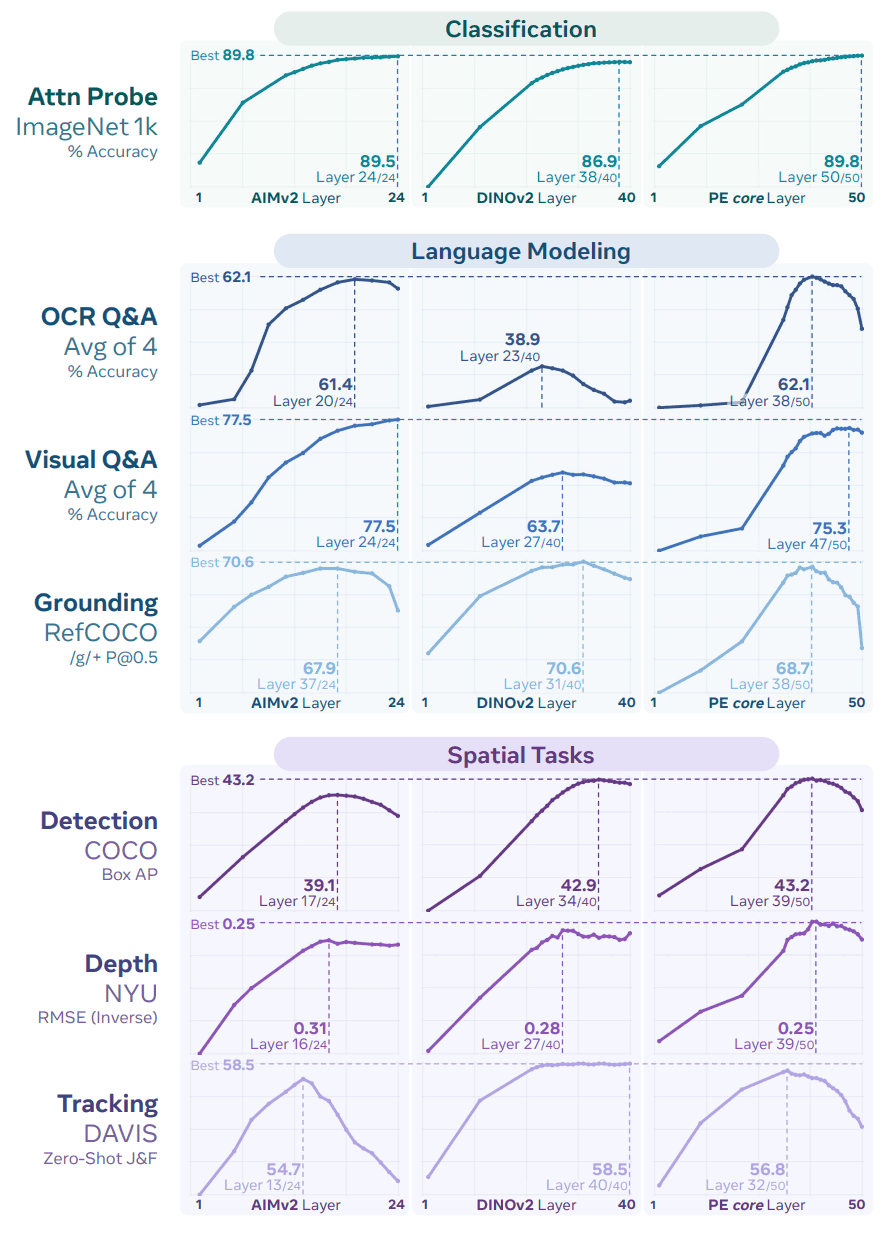
上記は、「何層目のものを取り出したか」というグラフになっているんですが、例えば1層目から50層あるようなネットワークの時に、グラウンディングのタスクだったら、最後の層だと性能がガクっと落ちちゃって情報を捨てているんですが、38層目くらいのものにいっぱい情報が残っているので、これを取り出すといいということが分かりました。
◆予想外の理解度と高い性能

結構びっくりする感じで、例えばデプス(3次元の深さ)の情報も、この画像変換モデルは知っています。
つまり、この画像を説明するテキストがあった時に、その「テキストとの特徴をマッチさせるという目的関数」だけで、各ピクセルがどれぐらいの深さになるかという情報も途中では推定しているということになります。
なので、ちゃんと3次元情報を実は画像エンコーダーが把握していて、「これこういう形だね」と理解しているのです。
例えば、キャプションで「牛乳パックの上は赤色です」という説明文があったとしたら、ちゃんと牛乳パックを把握して、「上側」というのがどこにあるかを推定して(3次元がわからないとわからない)、合うように、というような、そういう理解が勝手にされていて、それを今まで取り出してないだけだったけれども、取り出しているよ、ということになります。
意外と知っているということが面白いのと、あとこの方法は結構強くて、世の中でいろんな人が頑張って作っている有名モデルに勝ってしまっています。(Meta社がやっているため)学習データは多いんですが、非常に強いアプローチになっています。

