Vol.56 AIエージェントが賢くなる”Agent Data Protocol”とは
◆エージェント学習の課題と「統一フォーマット」の提案
エージェント・データ・プロトコルの話をします。これは、CMUのNeubig先生らによる研究です。余談ですがNeubig先生は日本でもずっと自然言語処理研究をしていて、昔からの知り合いです。
この論文では、エージェントで色々なタスクがあるという時の学習が難しいのですけれども、難しい理由は「異なるエージェントタスクでの標準的なフォーマットがないからだ」というようなことを提唱しています。
そこでエージェントタスクの統一的なフォーマットを定義して、そのフォーマットで書かれたエージェントタスクの学習データを使ってLLMを学習させる。
そのフォーマットから各エージェントタスク向けの特定のフォーマットというのは、機械的に変換して使うということで、LLMは様々なエージェントタスクにまたがって汎化しやすくなるよね、ということで、実際実験結果からはかなり汎化して性能が上がっているというような話をしています。
◆多様なタスクを統一する「観測」と「アクション」の形式
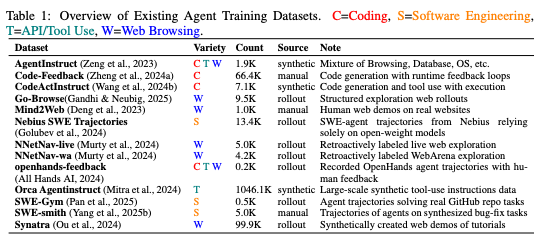
この論文ではエージェントタスクとして、十何種類かの色々なタスクがあります。
例えば「GO-Browse」というのは、Webをブラウジングして何かタスクをやるということになります。「SWE-Gym」のようなプログラムみたいなのもあったりだとか、最近増えているのはWebブラウジング系ですね。そういうタスクをまとめて学習すると。
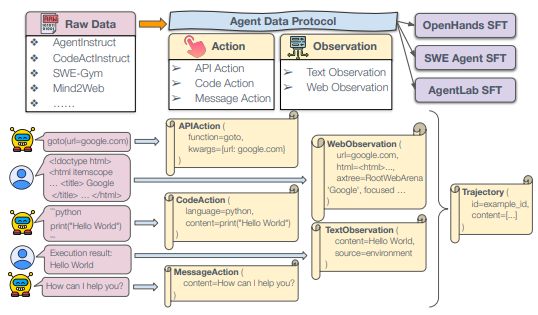
その際に統一的なフォーマットとして、どういうフォーマットにするかというと、強化学習のフォーマットとほぼ一緒で、データとしては観測(Observation)と行動(Action)というのが交互にずっと並んでいます。
で、観測と言っているものの各中身が、キーワード引数形式みたいな感じになっていて、キーワードとその値という形のがずらっと並んだ形式をフォーマットとして与えています。
違うエージェントのタスクとかエージェントを実行する際の異なるフレームワークも、この統一的な形式に全部入っていると。
行動の場合も、基本的にはAPIを叩くか、コードを書くか、テキストを出力するか、みたいなことなので、APIだったら、どのAPIを叩くかというのと、その時の引数が形式としてあるし、コードの場合はコードの種類と実際に書いたコードの内容になるし、メッセージの場合はメッセージになります。
これらが全部同じ形式フォーマットで学習すると、LLMが異なるエージェントタスクの共通する部分を勝手に考えてくれて、性能が特に汎化するように上がるというものになっています。
◆「理由付け」の追加と汎化性能の向上
あと最近っぽいなと思うのは、ある行動の時に、なぜその行動を選択したかというようなリーズニング(理由付け)もつけてあげると、それも性能向上にすごく効くというようなことを言っています。
これらのフォーマットの標準化とリーズニングをあわせた実験結果としては、個別で学習するよりも性能がガッと上がるし、エージェント間の汎化、新しいタスクに対する汎化みたいなものもガッと上がるという話があります。あと、エージェントタスクの中でもWebブラウジングによる学習結果がかなり効いているとのことです。
◆開発コスト(コード量)の削減と実用性
エンジニアリング的な話として、もしこういうことをしようとした時に、実際コードを書かないといけないものとしては、新しいエージェントのハーネス(実行環境)向けに、変換コードを書かないといけないというのが発生します。
ただ、この著者は、「一旦統一的なフォーマットさえ定めておけば、その統一的なフォーマットから新しいエージェントハーネスへの変換の部分だけ書けば使えるので、開発もすごく楽に済みます」というようなことを主張しています。
そういうのがなければ、データセットとハーネスごとの全通り、例えばデータセットがD種類あってハーネスがA種類あったらD×Aの変換がかかるところを、D+Aでコード量も1万行ぐらいで済むとか、そういったところが良いですね、と言っています。
これは実用的ですし、結構こういうのが効くと思います。

