Vol.60 分散学習の再来
※英語でのトークを翻訳しています。
◆Jubatusから集中型学習へ
今回の話は、分散学習(Distributed Training)に関する新しい成果についてです。私もPreferred Networksの前身となるPreferred Infrastructure(PFI)の頃に『Jubatus(ユバタス)』と呼ばれるシステムを開発して分散学習を実現しようと試みていました。
JubatusはNTTの共同研究プロジェクトです。これは、すべてのデータや学習処理を一箇所に集めることができない場合に向けた分散学習を実現するアプローチで、私たちにとって非常に重要なプロジェクトでした。
しかし、ご存知のように、現在の主な学習・トレーニング環境はより集中型になっています。例えばLLM(大規模言語モデル)の学習の場合、非常に大規模なデータセンターを一箇所に用意し、大規模な学習を達成するために、極めて密に接続されたトレーニング環境を構築する必要があります。
しかし、これは理想的とは言えません。そのような場所を一箇所に用意するのは非常に困難であり、多くの拠点やデータセンターに学習を分散させる方が容易だからです。そうすれば、各データセンターの限られた能力を活用することができます。
◆分散学習の3つのパラダイム
今回、紹介する分散学習に関する研究論文は現在ICLR(The International Conference on Learning Representations)で査読中であるため、著者が誰なのかはわかりませんが、アイデアは非常に理解しやすく、結果も非常に良好なので、共有したいと思います。
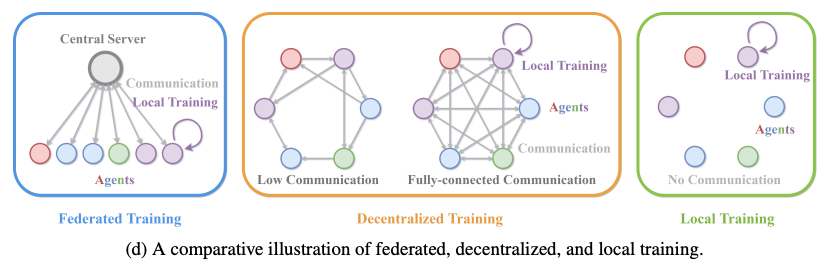
分散学習のパターンには、基本的に3つの方法があります。
1つ目は「連合学習(Federated Learning)」です。これはiPhoneなどがプライバシー保護学習で既に利用しているもので、実際、すべてのiPhoneはすでにこの学習をサポートしています。
この学習パラダイムでは、中央サーバーがあり、各クライアントがローカルで学習を行い、定期的に中央サーバーに学習した結果を集約します。
もう1つのパラダイムは「ローカル学習」です。この場合、もちろんデータや実行結果を共有せず、それぞれが独立に学習します。
そして、分散型および非中央集権型(Decentralized)学習があります。この場合も厳密には2つの方法があります。 1つ目は、完全接続(Fully Connected)通信です。各構成メンバーの学習結果が密に連携され、知識が共有されます。
そして、もう一つのより理想的なケースは、たまにしか通信を行わない、非中央集権的な学習です。このケースでは、システムが2つの構成メンバーを選び、これら2つのメンバーが相互に通信してモデルを同期させます。この場合、ネットワークへの要件が非常に限られているため、これは理想的です。
驚くべき現象として、この研究では、最後の「通信なしに近い」学習が「密に通信する」場合と同じぐらい機能することを発見しました。この場合、頻繁に通信する必要はありません。たまに、ペアのメンバーのみで通信するだけで同期をとります。
そして学習後、すべてのモデルは単なる平均化(Averaging)を使って1つのモデルに統合されます。これだけで、密に接続された通信の場合と同じ結果を達成するのに十分なのです。
これは少し驚きです。なぜなら最終的にそのような平均化を使うということを想定していなくても、いつのまにか平均化でうまくいくような調整が進んでいるのです。
◆メカニズムと今後の展望
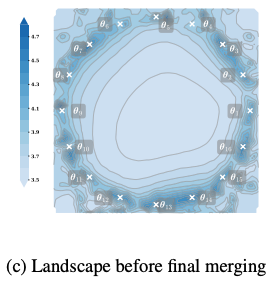
そして、最終的な統合(マージ)直前のランドスケープ(地形)も非常に興味深いものです。
各エージェントが相互に通信する際、どのように通信するか説明していませんでしたが、各エージェントは独自のモデルを持っており、そのモデルはプロトコル内で部分的にマージされます。具体的には、単純にエージェント間で重み付き平均を取り、その結果のモデルを各エージェントで共有します。
このプロトコルでは、最終的な結果として、各エージェントのモデルは、ある「basin(盆地/平坦な領域)」の内部および周辺に位置することになります。上の図は、各モデルが最終的な結果の周りにどのように位置しているかを示しています。
それらはある最終的なbasin(最適解の領域)を取り囲んでおり、マージした後、平均化されたモデルはもちろんこの領域の中心になります。このようにして、彼らはその領域の中心に対応する非常に良好な結果を得ることができ、その汎化性能は非常に高いと期待されます。
これは興味深いことです。なぜあのような単純な通信だけで、そのような場所に位置させることができるのかなど、多くの謎めいた部分はあります。しかし、経験的な結果はこれが問題ないことを示しています。また、簡略化された問題設定において、そのような疎な通信でこうした現象が現れることを理論的にも示しています。
これは彼らの研究論文からの結果ですが、将来的には、LLMやその他の大規模基盤モデルに対しても、同じような分散学習が達成できるのではないかと私は期待しています。現在は多くの学習が非常に大規模なデータセンターで行われていますが、将来的には、非常に分散された学習環境でそのような学習を実施できるかもしれません。

