Vol.59 GENIAC第3期におけるVLMの開発
◆開発の目的と成果
今回は、GENIAC第3期でPFNが開発を進めているPLaMo VLM(大規模視覚言語モデル)の話をしたいと思います。
これは何かと言うと、これまでGENIACの第1期・第2期ではテキストを扱うLLMの開発を進めていたのですが、今期はそのLLMにマルチモーダルを目指す中でビジョン(視覚)の能力を加えるということを目標として、前期で作ったPLaMo 2.0に、視覚の能力を加えたPLaMo VLというのを開発してきました。
まだ中間発表の時点なんですが、すでに元々の予定目標をかなり超えるような成果が出てきています。そうしたこともあって、今回このタイミングで発表をするとともに、ユーザーとなっていただけそうな方々に提供を開始する、試してもらうことを開始しています。
今VLMって言うとオープンモデルで世界で一番性能が高いものとして例えば、AlibabaのQwenという非常に強力なVLMがあります。その他、日本語対応ということで言うと、Asagiというモデルが性能がいいというのが分かっています。
こういったところで、私たちがフルスクラッチで作ってるPLaMoに視覚の能力を加えて、それらを超えるような性能を達成できたということになります。
◆VLMの標準的なタスクとPLaMo VLの認識能力
VQA(Visual Question Answering)における推論能力
昔から画像認識があるわけですが、今VLMでどんなことが標準的なタスクでされていて、どれぐらいできるかという話をします。

例えばこういう画像が与えられ、たくさんいろんなものが置かれている。
「前方に積まれているのは何ですか」と質問に対して応えようとすると、人間にはもちろん簡単な問題ですが、AIが答えようと思うと、まずこの画像の中で前方をちゃんと認識しないといけない。
さらに前方においてあるものが何かというのをちゃんと分からなければいけないので、「これはスイカだ」と物体認識をして、それを言語で、この場合は日本語で答える、というのをする必要があります。
任意のいろんな画像に対する質問に回答することができるようになっていて、かなり汎用性のあるタスクになっています。

2つ目の例で、「自転車に乗っている人の中で一番小さい人のヘルメットの色は何色ですか」っていう質問に答える場合です。
まず自転車に乗っている、(後ろの人たちが自転車に乗ってるかって結構微妙な判定ですが)後ろまで1つの自転車に乗ってるって分かるわけですね。
これに加えて、この3人の中でどの人が一番小さくてっていう認識をした上で、その人のヘルメットの色が何色かということが答えられている、複数の推論、マルチホップの推論をすることができるようになっています。
Visual Groundingにおける高度な位置特定能力

もう1つのベンチマークとしてVisual Groundingの場合は、指示文が与えられた上で、それが描かれているところを、従来のオブジェクト検出と同じように検出をして、その座標を出力するというようなタスクになっています。
例えば上記のタスクで、「他の犬と人間を見ている犬のバウンディングボックス(囲う四角形)の座標を出力してください」という例ですと、これ日本語としてもかなり難しい例ですが、犬は犬だけれども、犬とその人間を見ている手前側の犬を区別して、指定した方のボックス座標を出すことができます。

またですね、これもまあまあ難しいタスクで、「ショベルカーの近くにあるクレーンを検出して」と。
まずクレーンが複数あります。で、ショベルカーもちゃんと理解して、その近くにあるクレーンで、これを正しいバウンディングボックス出そうと思うと、クレーンの左端と右端がどこで、上と下がどこでというのを正確に認識した上で出さないといけないので、かなり難しいタスクなんですが、こういったことができるようになっています。
◆8Bモデルの優位性とエッジデバイスへの応用
今説明してきたのが、全て8Bという小さいモデルでこれらのタスクを達成できています。
8Bなのでもちろん、例えばQwenの数百Bのようなものすごい大きいモデルができるまでの認識精度はないんですが、一方で、8Bの中では一番性能が高くて、クラウドを介さずにエッジ側で処理するニーズが高いようなタスクで使えるようになっています。
例えば工場内の解析とか、工場内に限らず銀行とか施設内とか家の中だとか、いろんな理由で外に出したくないデータ、機密情報を扱うタスクもエッジ側で調べることができます。
また、今回目標としていた利用領域として自律稼働装置、監視カメラ、ドローン、ロボットに使ってもらうことを想定しました。例えばドローンを使って、建物だとか構造物だとか重要インフラ、そういったところの異常検知をできるようにする、ということを進めています。
自律稼働装置としてはドローンとかロボットってこれから非常に重要になるタスクではあるんですが、直近だと監視カメラへの利用要望が非常に増えています。
それはカメラのコストが安くなって、通信インフラも整ってきて、「とりあえず置いとくか」っていうカメラがいろんな場所にあるんですが、まだ解析ができていない。そういったところにこのVLを使った解析を入れていくことができたらいいなという風に考えています。
◆高性能を実現した要因はPLaMo翻訳の活用
ではなぜ私たちが小型で性能の高いVLMを作れて目標を達成できたのかっていうところなんですが、重要なこととして、モデルで差が出るのって結局データです。
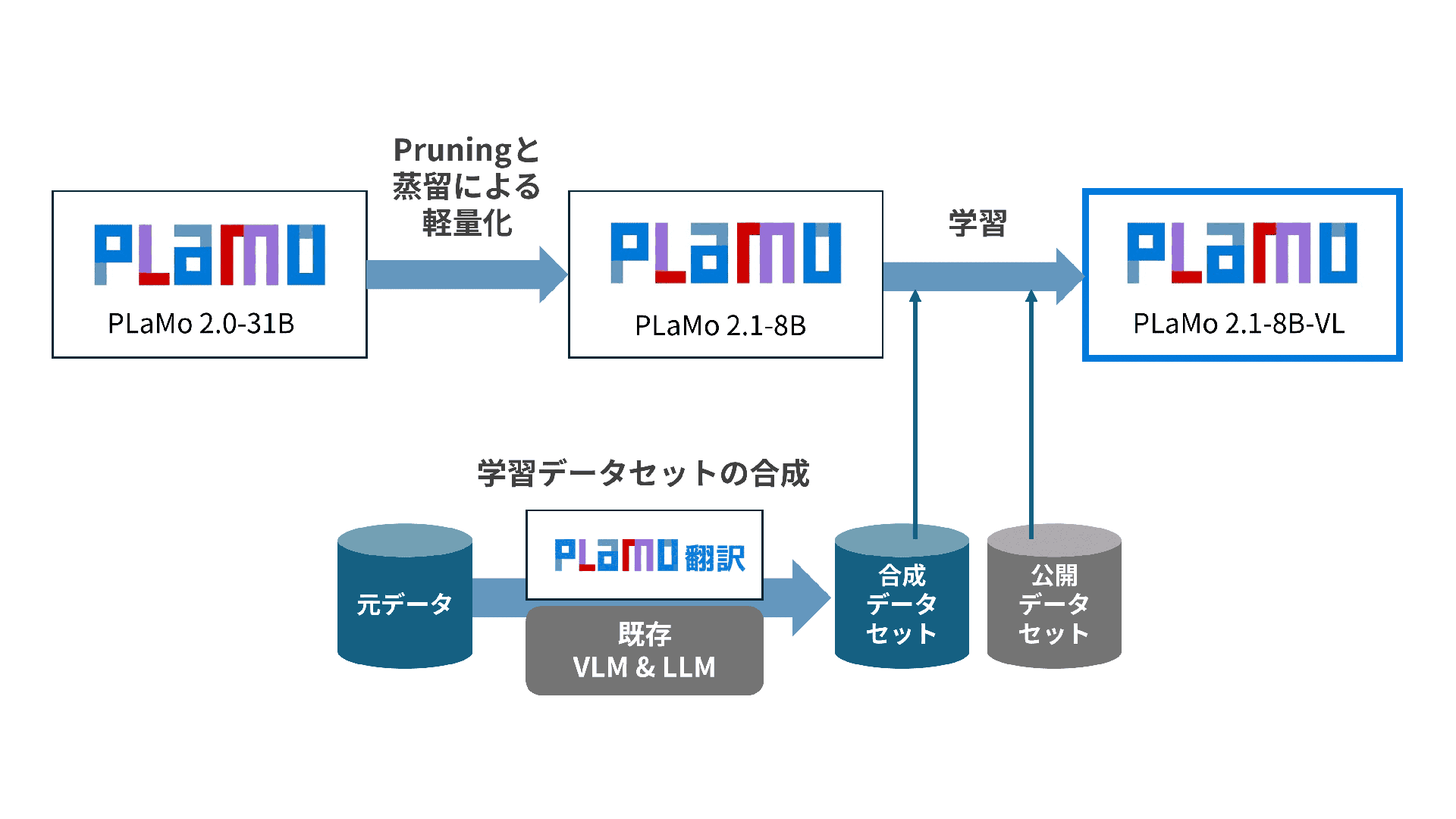
今回は学習データセット(最初からデータを生成して評価してっていうようなインフラ)を作って、いろんな形でデータをひたすら作り続けて、改善を回すということをやってきたおかげで、ここまで性能が上がったということがあります。
そこで実は、最近リリースしたPLaMo翻訳もかなり役に立っています。今回「日本語の指示で日本語の結果を出す」というようなタスクでは特に性能が上がっています。英語の指示で英語で結果を出す英語版でも勝ってるんですが、特に日本語では差を持って勝てるようになっています。
たくさんの「英語で正解がついてるようなデータ」を、PLaMo翻訳で高品質な「日本語の指示や答えがついたデータ」に変換して加えているおかげで、今回のような高い精度を持ったモデルができてるということになります。

例えば翻訳のところでは、上記のような画像と原文「A framed sign reading “YOU ARE NOT ALONE”.」 が書かれていて、画像の“YOU ARE NOT ALONE”はこのまま答えなければいけないけれど、機械翻訳でやると、認識して欲しい英字も翻訳しちゃったりするみたいな例もあります。
あとは、さっきの犬の例とかまさにそうですが、普通に翻訳が難しいのもたくさんあります。下手したら複数解釈ができるようなものがあったりするので、そういったところでは翻訳の部分、データを作る部分で重要だったと思います。
◆今後の展望
今回かなり短い期間で最初の成果が出ましたし、まだGENIAC第3期の残り半分の期間がありますので、さらに性能を上げていくことと、世界最高水準の性能がでているものの、実際使ってみるとまだまだ実用的には認識間違ったり、致命的なミスが起きたりとかもあるので、検証をしながらどういう場面に使えるか、その辺の工夫をこれから開始しようとしています。

